 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReducing Memorisation in Generative Models via Riemannian Bayesian Inference
Jan 30, 2026Modern generative models can produce realistic samples, however, balancing memorisation and generalisation remains an open problem. We approach this challenge from a Bayesian perspective by focusing on the parameter space of flow matching and diffusion models and constructing a predictive posterior that better captures the variability of the data distribution. In particular, we capture the geometry of the loss using a Riemannian metric and leverage a flexible approximate posterior that adapts to the local structure of the loss landscape. This approach allows us to sample generative models that resemble the original model, but exhibit reduced memorisation. Empirically, we demonstrate that the proposed approach reduces memorisation while preserving generalisation. Further, we provide a theoretical analysis of our method, which explains our findings. Overall, our work illustrates how considering the geometry of the loss enables effective use of the parameter space, even for complex high-dimensional generative models.
Learning geometry and topology via multi-chart flows
May 30, 2025Real world data often lie on low-dimensional Riemannian manifolds embedded in high-dimensional spaces. This motivates learning degenerate normalizing flows that map between the ambient space and a low-dimensional latent space. However, if the manifold has a non-trivial topology, it can never be correctly learned using a single flow. Instead multiple flows must be `glued together'. In this paper, we first propose the general training scheme for learning such a collection of flows, and secondly we develop the first numerical algorithms for computing geodesics on such manifolds. Empirically, we demonstrate that this leads to highly significant improvements in topology estimation.
Geodesic Slice Sampler for Multimodal Distributions with Strong Curvature
Feb 28, 2025Traditional Markov Chain Monte Carlo sampling methods often struggle with sharp curvatures, intricate geometries, and multimodal distributions. Slice sampling can resolve local exploration inefficiency issues and Riemannian geometries help with sharp curvatures. Recent extensions enable slice sampling on Riemannian manifolds, but they are restricted to cases where geodesics are available in closed form. We propose a method that generalizes Hit-and-Run slice sampling to more general geometries tailored to the target distribution, by approximating geodesics as solutions to differential equations. Our approach enables exploration of regions with strong curvature and rapid transitions between modes in multimodal distributions. We demonstrate the advantages of the approach over challenging sampling problems.
Monge SAM: Robust Reparameterization-Invariant Sharpness-Aware Minimization Based on Loss Geometry
Feb 12, 2025Recent studies on deep neural networks show that flat minima of the loss landscape correlate with improved generalization. Sharpness-aware minimization (SAM) efficiently finds flat regions by updating the parameters according to the gradient at an adversarial perturbation. The perturbation depends on the Euclidean metric, making SAM non-invariant under reparametrizations, which blurs sharpness and generalization. We propose Monge SAM (M-SAM), a reparametrization invariant version of SAM by considering a Riemannian metric in the parameter space induced naturally by the loss surface. Compared to previous approaches, M-SAM works under any modeling choice, relies only on mild assumptions while being as computationally efficient as SAM. We theoretically argue that M-SAM varies between SAM and gradient descent (GD), which increases robustness to hyperparameter selection and reduces attraction to suboptimal equilibria like saddle points. We demonstrate this behavior both theoretically and empirically on a multi-modal representation alignment task.
Extended Neural Contractive Dynamical Systems: On Multiple Tasks and Riemannian Safety Regions
Nov 20, 2024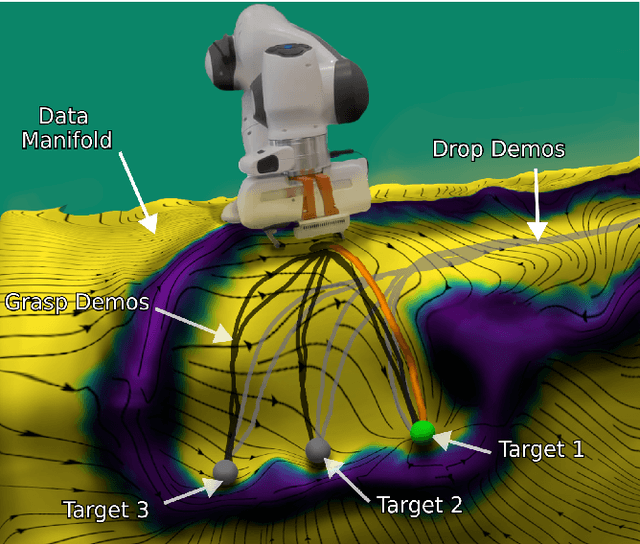

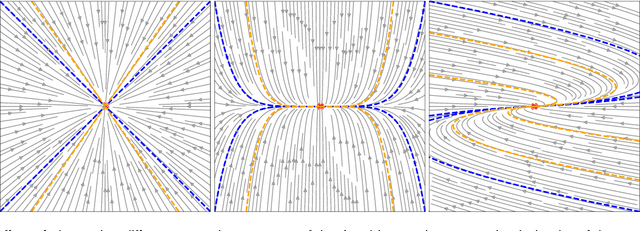
Stability guarantees are crucial when ensuring that a fully autonomous robot does not take undesirable or potentially harmful actions. We recently proposed the Neural Contractive Dynamical Systems (NCDS), which is a neural network architecture that guarantees contractive stability. With this, learning-from-demonstrations approaches can trivially provide stability guarantees. However, our early work left several unanswered questions, which we here address. Beyond providing an in-depth explanation of NCDS, this paper extends the framework with more careful regularization, a conditional variant of the framework for handling multiple tasks, and an uncertainty-driven approach to latent obstacle avoidance. Experiments verify that the developed system has the flexibility of ordinary neural networks while providing the stability guarantees needed for autonomous robotics.
Counterfactual Explanations via Riemannian Latent Space Traversal
Nov 04, 2024The adoption of increasingly complex deep models has fueled an urgent need for insight into how these models make predictions. Counterfactual explanations form a powerful tool for providing actionable explanations to practitioners. Previously, counterfactual explanation methods have been designed by traversing the latent space of generative models. Yet, these latent spaces are usually greatly simplified, with most of the data distribution complexity contained in the decoder rather than the latent embedding. Thus, traversing the latent space naively without taking the nonlinear decoder into account can lead to unnatural counterfactual trajectories. We introduce counterfactual explanations obtained using a Riemannian metric pulled back via the decoder and the classifier under scrutiny. This metric encodes information about the complex geometric structure of the data and the learned representation, enabling us to obtain robust counterfactual trajectories with high fidelity, as demonstrated by our experiments in real-world tabular datasets.
Neural Contractive Dynamical Systems
Jan 17, 2024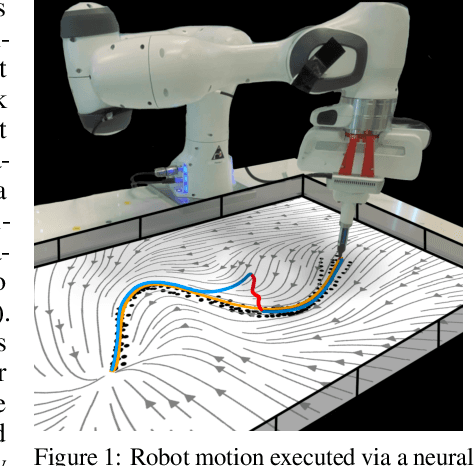


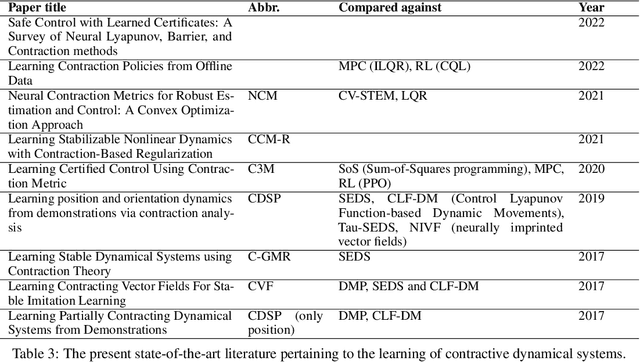
Stability guarantees are crucial when ensuring a fully autonomous robot does not take undesirable or potentially harmful actions. Unfortunately, global stability guarantees are hard to provide in dynamical systems learned from data, especially when the learned dynamics are governed by neural networks. We propose a novel methodology to learn neural contractive dynamical systems, where our neural architecture ensures contraction, and hence, global stability. To efficiently scale the method to high-dimensional dynamical systems, we develop a variant of the variational autoencoder that learns dynamics in a low-dimensional latent representation space while retaining contractive stability after decoding. We further extend our approach to learning contractive systems on the Lie group of rotations to account for full-pose end-effector dynamic motions. The result is the first highly flexible learning architecture that provides contractive stability guarantees with capability to perform obstacle avoidance. Empirically, we demonstrate that our approach encodes the desired dynamics more accurately than the current state-of-the-art, which provides less strong stability guarantees.
On the curvature of the loss landscape
Jul 10, 2023One of the main challenges in modern deep learning is to understand why such over-parameterized models perform so well when trained on finite data. A way to analyze this generalization concept is through the properties of the associated loss landscape. In this work, we consider the loss landscape as an embedded Riemannian manifold and show that the differential geometric properties of the manifold can be used when analyzing the generalization abilities of a deep net. In particular, we focus on the scalar curvature, which can be computed analytically for our manifold, and show connections to several settings that potentially imply generalization.
Riemannian Laplace approximations for Bayesian neural networks
Jun 12, 2023Bayesian neural networks often approximate the weight-posterior with a Gaussian distribution. However, practical posteriors are often, even locally, highly non-Gaussian, and empirical performance deteriorates. We propose a simple parametric approximate posterior that adapts to the shape of the true posterior through a Riemannian metric that is determined by the log-posterior gradient. We develop a Riemannian Laplace approximation where samples naturally fall into weight-regions with low negative log-posterior. We show that these samples can be drawn by solving a system of ordinary differential equations, which can be done efficiently by leveraging the structure of the Riemannian metric and automatic differentiation. Empirically, we demonstrate that our approach consistently improves over the conventional Laplace approximation across tasks. We further show that, unlike the conventional Laplace approximation, our method is not overly sensitive to the choice of prior, which alleviates a practical pitfall of current approaches.
Reactive Motion Generation on Learned Riemannian Manifolds
Mar 15, 2022
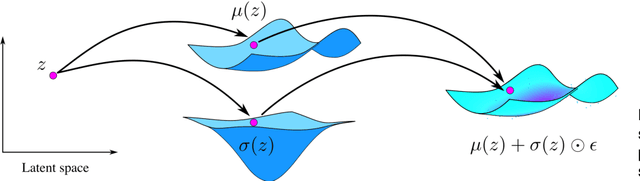
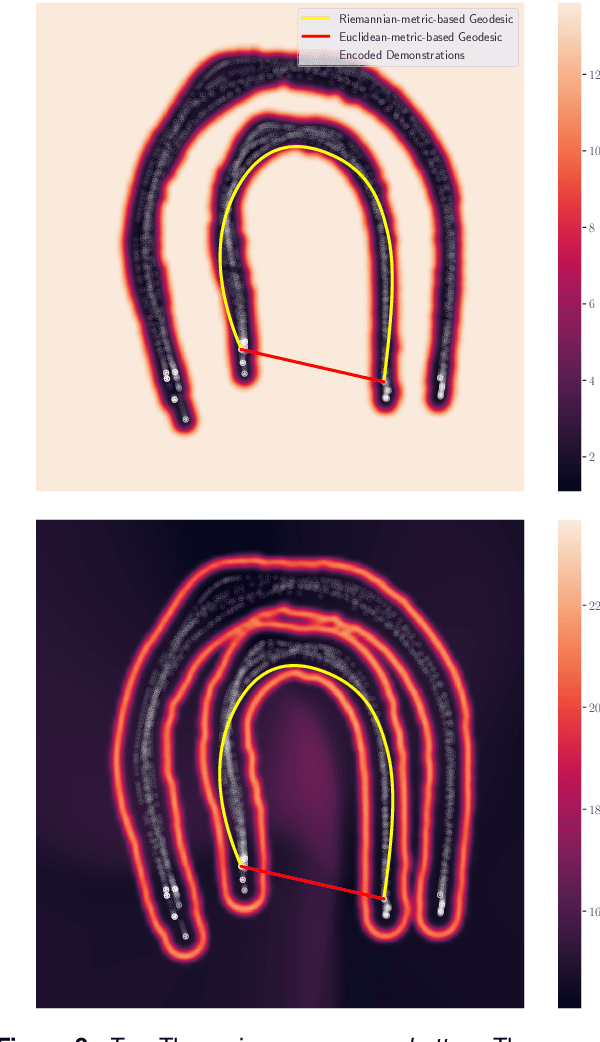
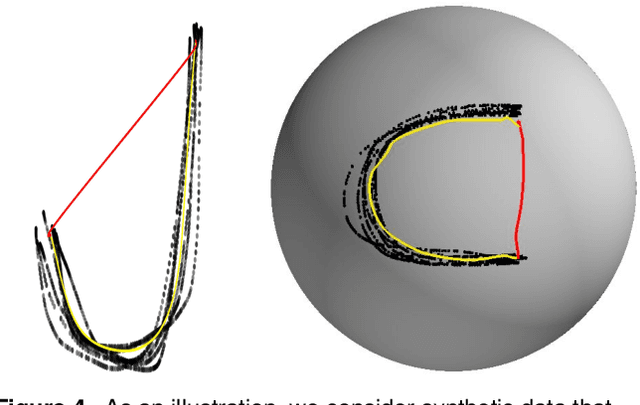
In recent decades, advancements in motion learning have enabled robots to acquire new skills and adapt to unseen conditions in both structured and unstructured environments. In practice, motion learning methods capture relevant patterns and adjust them to new conditions such as dynamic obstacle avoidance or variable targets. In this paper, we investigate the robot motion learning paradigm from a Riemannian manifold perspective. We argue that Riemannian manifolds may be learned via human demonstrations in which geodesics are natural motion skills. The geodesics are generated using a learned Riemannian metric produced by our novel variational autoencoder (VAE), which is especially intended to recover full-pose end-effector states and joint space configurations. In addition, we propose a technique for facilitating on-the-fly end-effector/multiple-limb obstacle avoidance by reshaping the learned manifold using an obstacle-aware ambient metric. The motion generated using these geodesics may naturally result in multiple-solution tasks that have not been explicitly demonstrated previously. We extensively tested our approach in task space and joint space scenarios using a 7-DoF robotic manipulator. We demonstrate that our method is capable of learning and generating motion skills based on complicated motion patterns demonstrated by a human operator. Additionally, we assess several obstacle avoidance strategies and generate trajectories in multiple-mode settings.