 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoder ensembling for learned latent geometries
Aug 14, 2024


Latent space geometry provides a rigorous and empirically valuable framework for interacting with the latent variables of deep generative models. This approach reinterprets Euclidean latent spaces as Riemannian through a pull-back metric, allowing for a standard differential geometric analysis of the latent space. Unfortunately, data manifolds are generally compact and easily disconnected or filled with holes, suggesting a topological mismatch to the Euclidean latent space. The most established solution to this mismatch is to let uncertainty be a proxy for topology, but in neural network models, this is often realized through crude heuristics that lack principle and generally do not scale to high-dimensional representations. We propose using ensembles of decoders to capture model uncertainty and show how to easily compute geodesics on the associated expected manifold. Empirically, we find this simple and reliable, thereby coming one step closer to easy-to-use latent geometries.
Gradients of Functions of Large Matrices
May 27, 2024



Tuning scientific and probabilistic machine learning models -- for example, partial differential equations, Gaussian processes, or Bayesian neural networks -- often relies on evaluating functions of matrices whose size grows with the data set or the number of parameters. While the state-of-the-art for evaluating these quantities is almost always based on Lanczos and Arnoldi iterations, the present work is the first to explain how to differentiate these workhorses of numerical linear algebra efficiently. To get there, we derive previously unknown adjoint systems for Lanczos and Arnoldi iterations, implement them in JAX, and show that the resulting code can compete with Diffrax when it comes to differentiating PDEs, GPyTorch for selecting Gaussian process models and beats standard factorisation methods for calibrating Bayesian neural networks. All this is achieved without any problem-specific code optimisation. Find the code at https://github.com/pnkraemer/experiments-lanczos-adjoints and install the library with pip install matfree.
Riemannian Laplace approximations for Bayesian neural networks
Jun 12, 2023Bayesian neural networks often approximate the weight-posterior with a Gaussian distribution. However, practical posteriors are often, even locally, highly non-Gaussian, and empirical performance deteriorates. We propose a simple parametric approximate posterior that adapts to the shape of the true posterior through a Riemannian metric that is determined by the log-posterior gradient. We develop a Riemannian Laplace approximation where samples naturally fall into weight-regions with low negative log-posterior. We show that these samples can be drawn by solving a system of ordinary differential equations, which can be done efficiently by leveraging the structure of the Riemannian metric and automatic differentiation. Empirically, we demonstrate that our approach consistently improves over the conventional Laplace approximation across tasks. We further show that, unlike the conventional Laplace approximation, our method is not overly sensitive to the choice of prior, which alleviates a practical pitfall of current approaches.
On Masked Pre-training and the Marginal Likelihood
Jun 01, 2023Masked pre-training removes random input dimensions and learns a model that can predict the missing values. Empirical results indicate that this intuitive form of self-supervised learning yields models that generalize very well to new domains. A theoretical understanding is, however, lacking. This paper shows that masked pre-training with a suitable cumulative scoring function corresponds to maximizing the model's marginal likelihood, which is de facto the Bayesian model selection measure of generalization. Beyond shedding light on the success of masked pre-training, this insight also suggests that Bayesian models can be trained with appropriately designed self-supervision. Empirically, we confirm the developed theory and explore the main learning principles of masked pre-training in large language models.
Revisiting Active Sets for Gaussian Process Decoders
Sep 10, 2022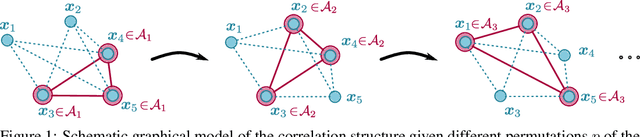

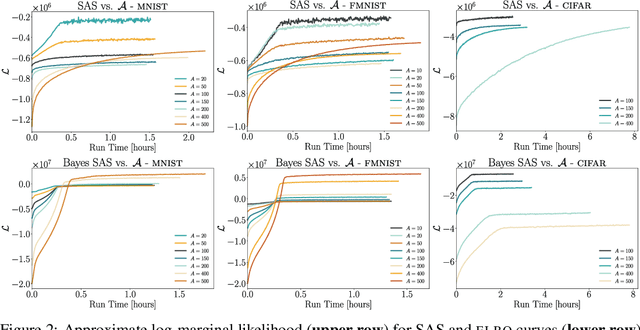
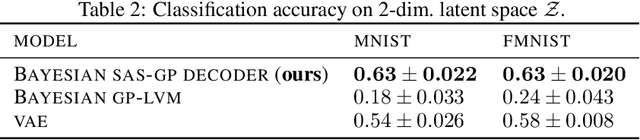
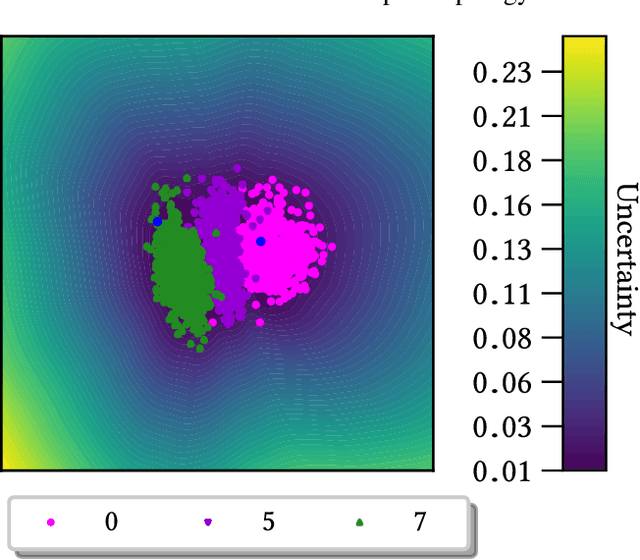
Decoders built on Gaussian processes (GPs) are enticing due to the marginalisation over the non-linear function space. Such models (also known as GP-LVMs) are often expensive and notoriously difficult to train in practice, but can be scaled using variational inference and inducing points. In this paper, we revisit active set approximations. We develop a new stochastic estimate of the log-marginal likelihood based on recently discovered links to cross-validation, and propose a computationally efficient approximation thereof. We demonstrate that the resulting stochastic active sets (SAS) approximation significantly improves the robustness of GP decoder training while reducing computational cost. The SAS-GP obtains more structure in the latent space, scales to many datapoints and learns better representations than variational autoencoders, which is rarely the case for GP decoders.
Laplacian Autoencoders for Learning Stochastic Representations
Jul 03, 2022
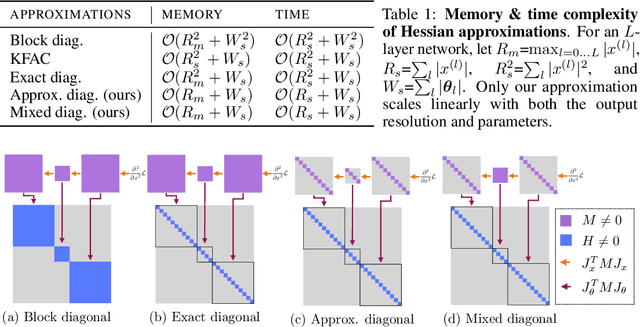

Established methods for unsupervised representation learning such as variational autoencoders produce none or poorly calibrated uncertainty estimates making it difficult to evaluate if learned representations are stable and reliable. In this work, we present a Bayesian autoencoder for unsupervised representation learning, which is trained using a novel variational lower-bound of the autoencoder evidence. This is maximized using Monte Carlo EM with a variational distribution that takes the shape of a Laplace approximation. We develop a new Hessian approximation that scales linearly with data size allowing us to model high-dimensional data. Empirically, we show that our Laplacian autoencoder estimates well-calibrated uncertainties in both latent and output space. We demonstrate that this results in improved performance across a multitude of downstream tasks.
Adaptive Cholesky Gaussian Processes
Feb 23, 2022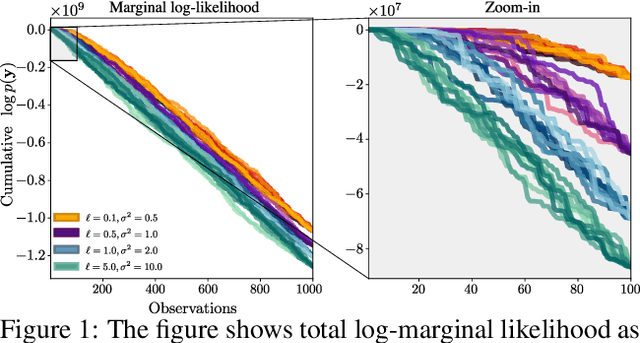
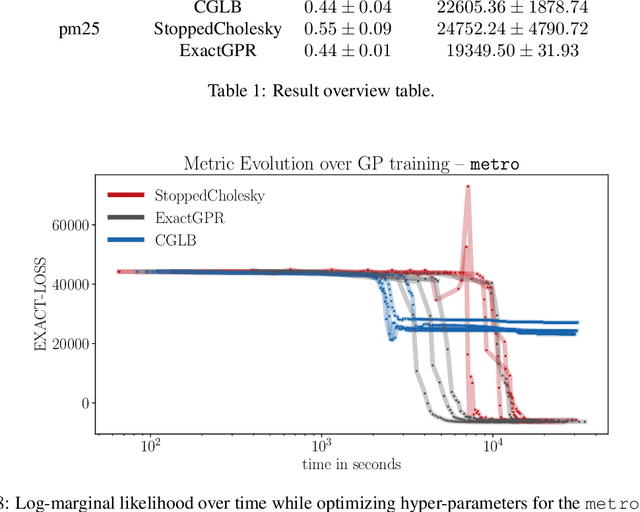
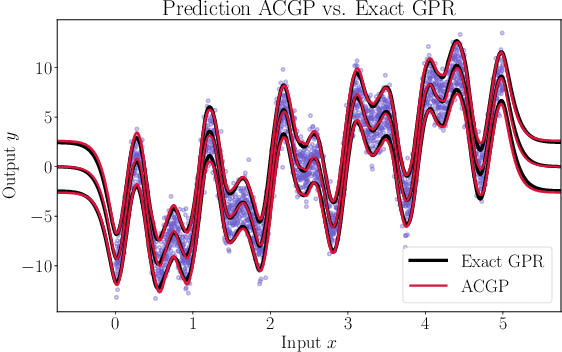
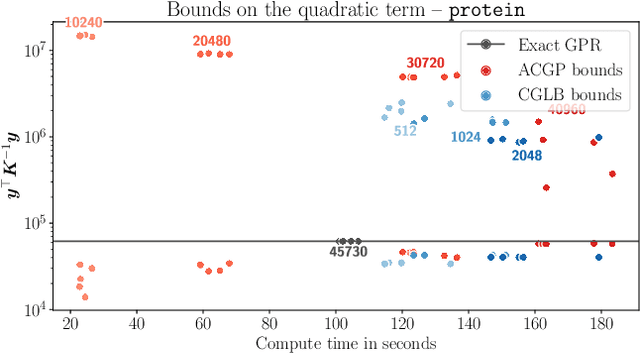
We present a method to fit exact Gaussian process models to large datasets by considering only a subset of the data. Our approach is novel in that the size of the subset is selected on the fly during exact inference with little computational overhead. From an empirical observation that the log-marginal likelihood often exhibits a linear trend once a sufficient subset of a dataset has been observed, we conclude that many large datasets contain redundant information that only slightly affects the posterior. Based on this, we provide probabilistic bounds on the full model evidence that can identify such subsets. Remarkably, these bounds are largely composed of terms that appear in intermediate steps of the standard Cholesky decomposition, allowing us to modify the algorithm to adaptively stop the decomposition once enough data have been observed. Empirically, we show that our method can be directly plugged into well-known inference schemes to fit exact Gaussian process models to large datasets.
Modular Gaussian Processes for Transfer Learning
Oct 26, 2021
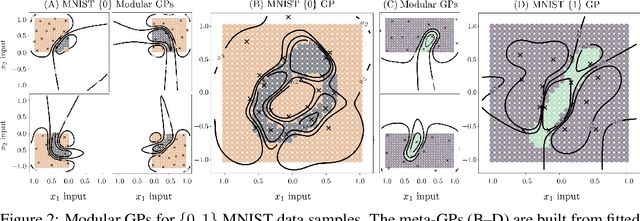
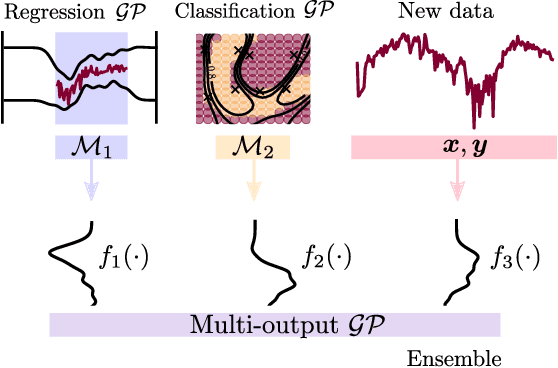
We present a framework for transfer learning based on modular variational Gaussian processes (GP). We develop a module-based method that having a dictionary of well fitted GPs, one could build ensemble GP models without revisiting any data. Each model is characterised by its hyperparameters, pseudo-inputs and their corresponding posterior densities. Our method avoids undesired data centralisation, reduces rising computational costs and allows the transfer of learned uncertainty metrics after training. We exploit the augmentation of high-dimensional integral operators based on the Kullback-Leibler divergence between stochastic processes to introduce an efficient lower bound under all the sparse variational GPs, with different complexity and even likelihood distribution. The method is also valid for multi-output GPs, learning correlations a posteriori between independent modules. Extensive results illustrate the usability of our framework in large-scale and multi-task experiments, also compared with the exact inference methods in the literature.
Passive detection of behavioral shifts for suicide attempt prevention
Nov 14, 2020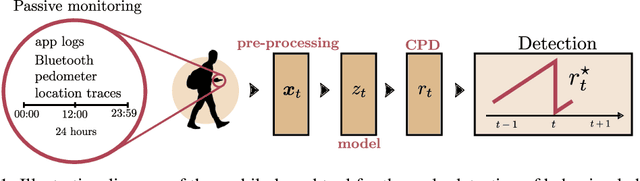
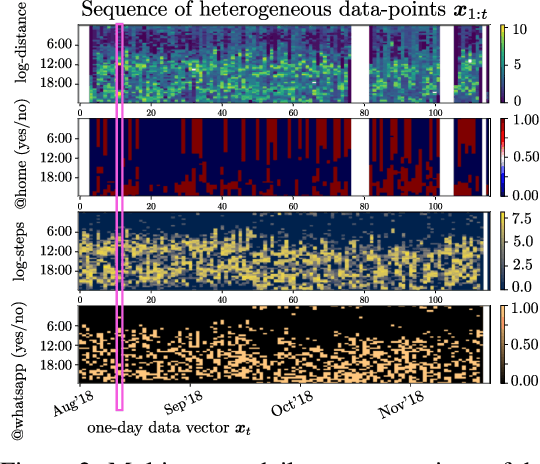
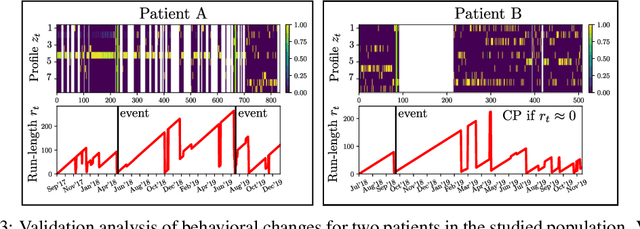
More than one million people commit suicide every year worldwide. The costs of daily cares, social stigma and treatment issues are still hard barriers to overcome in mental health. Most symptoms of mental disorders are related to the behavioral state of a patient, such as the mobility or social activity. Mobile-based technologies allow the passive collection of patients data, which supplements conventional assessments that rely on biased questionnaires and occasional medical appointments. In this work, we present a non-invasive machine learning (ML) model to detect behavioral shifts in psychiatric patients from unobtrusive data collected by a smartphone app. Our clinically validated results shed light on the idea of an early detection mobile tool for the task of suicide attempt prevention.
Recyclable Gaussian Processes
Oct 06, 2020

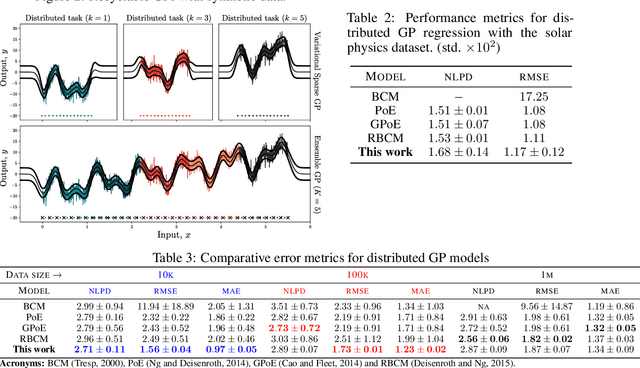
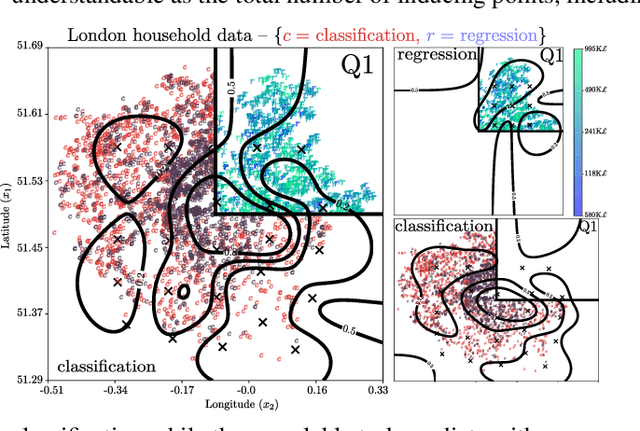
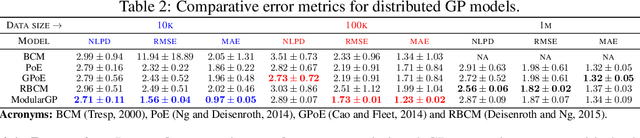
We present a new framework for recycling independent variational approximations to Gaussian processes. The main contribution is the construction of variational ensembles given a dictionary of fitted Gaussian processes without revisiting any subset of observations. Our framework allows for regression, classification and heterogeneous tasks, i.e. mix of continuous and discrete variables over the same input domain. We exploit infinite-dimensional integral operators based on the Kullback-Leibler divergence between stochastic processes to re-combine arbitrary amounts of variational sparse approximations with different complexity, likelihood model and location of the pseudo-inputs. Extensive results illustrate the usability of our framework in large-scale distributed experiments, also compared with the exact inference models in the literature.