 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn-Context Bias Propagation in LLM-Based Tabular Data Generation
Jun 11, 2025Large Language Models (LLMs) are increasingly used for synthetic tabular data generation through in-context learning (ICL), offering a practical solution for data augmentation in data scarce scenarios. While prior work has shown the potential of LLMs to improve downstream task performance through augmenting underrepresented groups, these benefits often assume access to a subset of unbiased in-context examples, representative of the real dataset. In real-world settings, however, data is frequently noisy and demographically skewed. In this paper, we systematically study how statistical biases within in-context examples propagate to the distribution of synthetic tabular data, showing that even mild in-context biases lead to global statistical distortions. We further introduce an adversarial scenario where a malicious contributor can inject bias into the synthetic dataset via a subset of in-context examples, ultimately compromising the fairness of downstream classifiers for a targeted and protected subgroup. Our findings demonstrate a new vulnerability associated with LLM-based data generation pipelines that rely on in-context prompts with in sensitive domains.
Mind the Memory Gap: Unveiling GPU Bottlenecks in Large-Batch LLM Inference
Mar 11, 2025Large language models have been widely adopted across different tasks, but their auto-regressive generation nature often leads to inefficient resource utilization during inference. While batching is commonly used to increase throughput, performance gains plateau beyond a certain batch size, especially with smaller models, a phenomenon that existing literature typically explains as a shift to the compute-bound regime. In this paper, through an in-depth GPU-level analysis, we reveal that large-batch inference remains memory-bound, with most GPU compute capabilities underutilized due to DRAM bandwidth saturation as the primary bottleneck. To address this, we propose a Batching Configuration Advisor (BCA) that optimizes memory allocation, reducing GPU memory requirements with minimal impact on throughput. The freed memory and underutilized GPU compute capabilities can then be leveraged by concurrent workloads. Specifically, we use model replication to improve serving throughput and GPU utilization. Our findings challenge conventional assumptions about LLM inference, offering new insights and practical strategies for improving resource utilization, particularly for smaller language models.
FRIDA: Free-Rider Detection using Privacy Attacks
Oct 07, 2024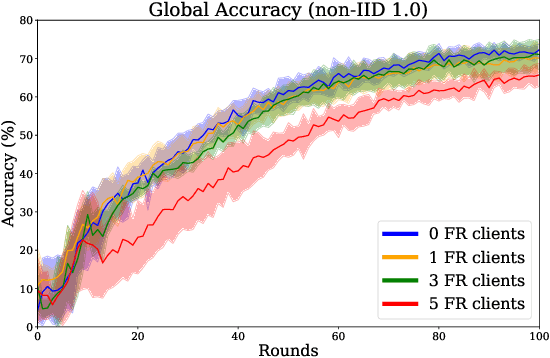
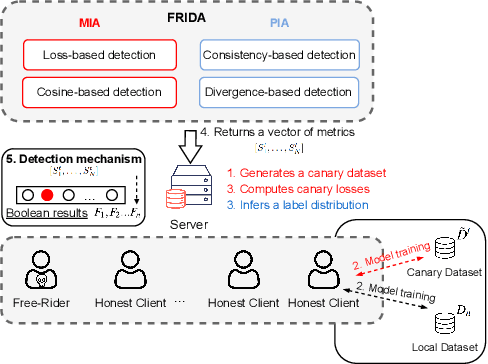
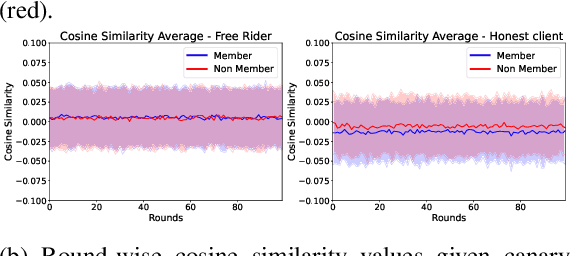
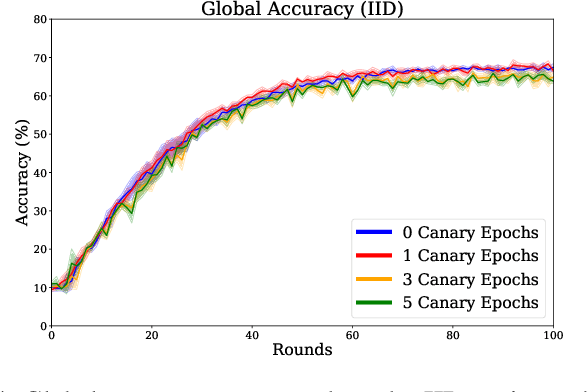
Federated learning is increasingly popular as it enables multiple parties with limited datasets and resources to train a high-performing machine learning model collaboratively. However, similarly to other collaborative systems, federated learning is vulnerable to free-riders -- participants who do not contribute to the training but still benefit from the shared model. Free-riders not only compromise the integrity of the learning process but also slow down the convergence of the global model, resulting in increased costs for the honest participants. To address this challenge, we propose FRIDA: free-rider detection using privacy attacks, a framework that leverages inference attacks to detect free-riders. Unlike traditional methods that only capture the implicit effects of free-riding, FRIDA directly infers details of the underlying training datasets, revealing characteristics that indicate free-rider behaviour. Through extensive experiments, we demonstrate that membership and property inference attacks are effective for this purpose. Our evaluation shows that FRIDA outperforms state-of-the-art methods, especially in non-IID settings.
Towards Pareto Optimal Throughput in Small Language Model Serving
Apr 04, 2024Large language models (LLMs) have revolutionized the state-of-the-art of many different natural language processing tasks. Although serving LLMs is computationally and memory demanding, the rise of Small Language Models (SLMs) offers new opportunities for resource-constrained users, who now are able to serve small models with cutting-edge performance. In this paper, we present a set of experiments designed to benchmark SLM inference at performance and energy levels. Our analysis provides a new perspective in serving, highlighting that the small memory footprint of SLMs allows for reaching the Pareto-optimal throughput within the resource capacity of a single accelerator. In this regard, we present an initial set of findings demonstrating how model replication can effectively improve resource utilization for serving SLMs.
On Masked Pre-training and the Marginal Likelihood
Jun 01, 2023Masked pre-training removes random input dimensions and learns a model that can predict the missing values. Empirical results indicate that this intuitive form of self-supervised learning yields models that generalize very well to new domains. A theoretical understanding is, however, lacking. This paper shows that masked pre-training with a suitable cumulative scoring function corresponds to maximizing the model's marginal likelihood, which is de facto the Bayesian model selection measure of generalization. Beyond shedding light on the success of masked pre-training, this insight also suggests that Bayesian models can be trained with appropriately designed self-supervision. Empirically, we confirm the developed theory and explore the main learning principles of masked pre-training in large language models.