 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaximizing GPU Efficiency via Optimal Adapter Caching: An Analytical Approach for Multi-Tenant LLM Serving
Aug 11, 2025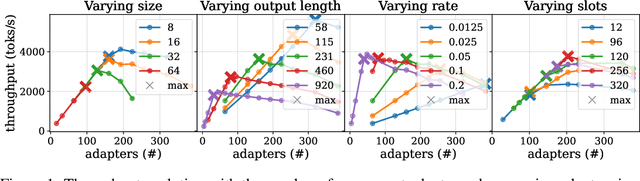
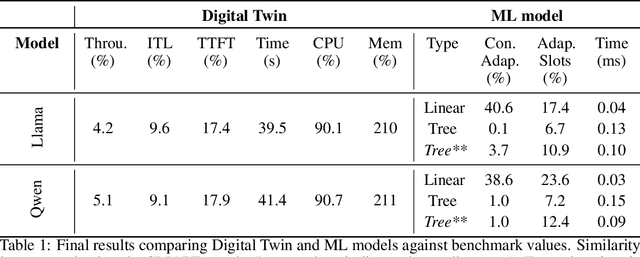
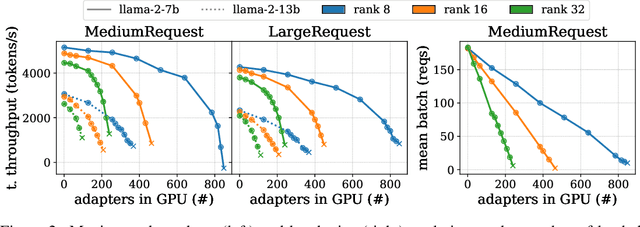
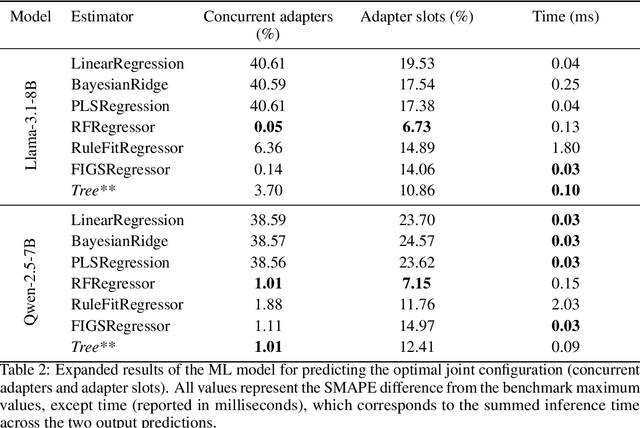
Serving LLM adapters has gained significant attention as an effective approach to adapt general-purpose language models to diverse, task-specific use cases. However, serving a wide range of adapters introduces several and substantial overheads, leading to performance degradation and challenges in optimal placement. To address these challenges, we present an analytical, AI-driven pipeline that accurately determines the optimal allocation of adapters in single-node setups. This allocation maximizes performance, effectively using GPU resources, while preventing request starvation. Crucially, the proposed allocation is given based on current workload patterns. These insights in single-node setups can be leveraged in multi-replica deployments for overall placement, load balancing and server configuration, ultimately enhancing overall performance and improving resource efficiency. Our approach builds on an in-depth analysis of LLM adapter serving, accounting for overheads and performance variability, and includes the development of the first Digital Twin capable of replicating online LLM-adapter serving systems with matching key performance metrics. The experimental results demonstrate that the Digital Twin achieves a SMAPE difference of no more than 5.5% in throughput compared to real results, and the proposed pipeline accurately predicts the optimal placement with minimal latency.
Mind the Memory Gap: Unveiling GPU Bottlenecks in Large-Batch LLM Inference
Mar 11, 2025Large language models have been widely adopted across different tasks, but their auto-regressive generation nature often leads to inefficient resource utilization during inference. While batching is commonly used to increase throughput, performance gains plateau beyond a certain batch size, especially with smaller models, a phenomenon that existing literature typically explains as a shift to the compute-bound regime. In this paper, through an in-depth GPU-level analysis, we reveal that large-batch inference remains memory-bound, with most GPU compute capabilities underutilized due to DRAM bandwidth saturation as the primary bottleneck. To address this, we propose a Batching Configuration Advisor (BCA) that optimizes memory allocation, reducing GPU memory requirements with minimal impact on throughput. The freed memory and underutilized GPU compute capabilities can then be leveraged by concurrent workloads. Specifically, we use model replication to improve serving throughput and GPU utilization. Our findings challenge conventional assumptions about LLM inference, offering new insights and practical strategies for improving resource utilization, particularly for smaller language models.
Towards Pareto Optimal Throughput in Small Language Model Serving
Apr 04, 2024Large language models (LLMs) have revolutionized the state-of-the-art of many different natural language processing tasks. Although serving LLMs is computationally and memory demanding, the rise of Small Language Models (SLMs) offers new opportunities for resource-constrained users, who now are able to serve small models with cutting-edge performance. In this paper, we present a set of experiments designed to benchmark SLM inference at performance and energy levels. Our analysis provides a new perspective in serving, highlighting that the small memory footprint of SLMs allows for reaching the Pareto-optimal throughput within the resource capacity of a single accelerator. In this regard, we present an initial set of findings demonstrating how model replication can effectively improve resource utilization for serving SLMs.