 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaximizing GPU Efficiency via Optimal Adapter Caching: An Analytical Approach for Multi-Tenant LLM Serving
Aug 11, 2025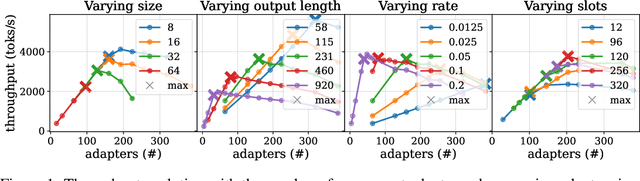
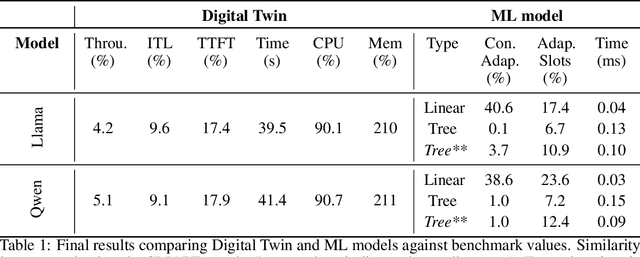
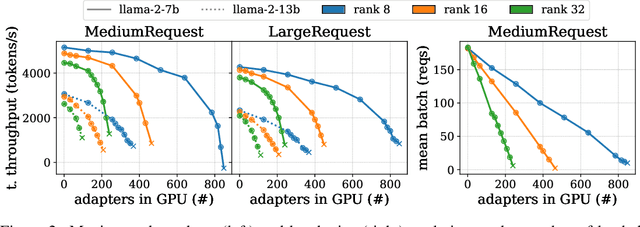
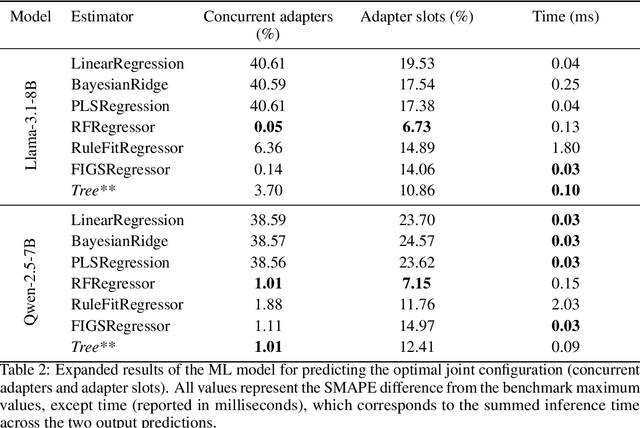
Serving LLM adapters has gained significant attention as an effective approach to adapt general-purpose language models to diverse, task-specific use cases. However, serving a wide range of adapters introduces several and substantial overheads, leading to performance degradation and challenges in optimal placement. To address these challenges, we present an analytical, AI-driven pipeline that accurately determines the optimal allocation of adapters in single-node setups. This allocation maximizes performance, effectively using GPU resources, while preventing request starvation. Crucially, the proposed allocation is given based on current workload patterns. These insights in single-node setups can be leveraged in multi-replica deployments for overall placement, load balancing and server configuration, ultimately enhancing overall performance and improving resource efficiency. Our approach builds on an in-depth analysis of LLM adapter serving, accounting for overheads and performance variability, and includes the development of the first Digital Twin capable of replicating online LLM-adapter serving systems with matching key performance metrics. The experimental results demonstrate that the Digital Twin achieves a SMAPE difference of no more than 5.5% in throughput compared to real results, and the proposed pipeline accurately predicts the optimal placement with minimal latency.
Foundation Models in Radiology: What, How, When, Why and Why Not
Nov 27, 2024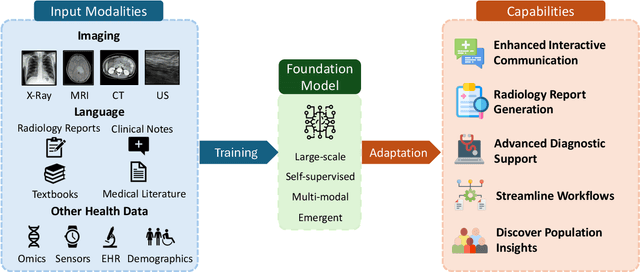
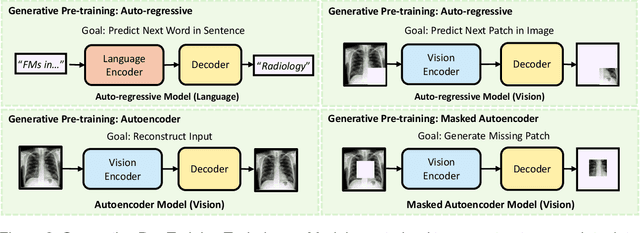
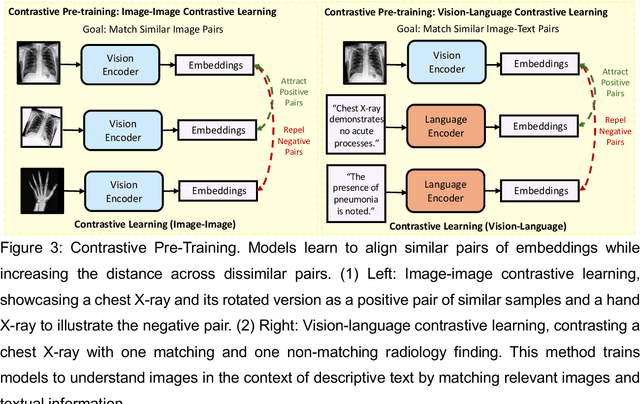
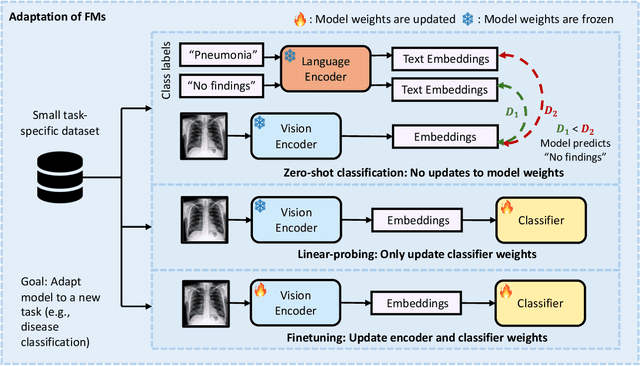
Recent advances in artificial intelligence have witnessed the emergence of large-scale deep learning models capable of interpreting and generating both textual and imaging data. Such models, typically referred to as foundation models, are trained on extensive corpora of unlabeled data and demonstrate high performance across various tasks. Foundation models have recently received extensive attention from academic, industry, and regulatory bodies. Given the potentially transformative impact that foundation models can have on the field of radiology, this review aims to establish a standardized terminology concerning foundation models, with a specific focus on the requirements of training data, model training paradigms, model capabilities, and evaluation strategies. We further outline potential pathways to facilitate the training of radiology-specific foundation models, with a critical emphasis on elucidating both the benefits and challenges associated with such models. Overall, we envision that this review can unify technical advances and clinical needs in the training of foundation models for radiology in a safe and responsible manner, for ultimately benefiting patients, providers, and radiologists.
Transforming the Hybrid Cloud for Emerging AI Workloads
Nov 20, 2024



This white paper, developed through close collaboration between IBM Research and UIUC researchers within the IIDAI Institute, envisions transforming hybrid cloud systems to meet the growing complexity of AI workloads through innovative, full-stack co-design approaches, emphasizing usability, manageability, affordability, adaptability, efficiency, and scalability. By integrating cutting-edge technologies such as generative and agentic AI, cross-layer automation and optimization, unified control plane, and composable and adaptive system architecture, the proposed framework addresses critical challenges in energy efficiency, performance, and cost-effectiveness. Incorporating quantum computing as it matures will enable quantum-accelerated simulations for materials science, climate modeling, and other high-impact domains. Collaborative efforts between academia and industry are central to this vision, driving advancements in foundation models for material design and climate solutions, scalable multimodal data processing, and enhanced physics-based AI emulators for applications like weather forecasting and carbon sequestration. Research priorities include advancing AI agentic systems, LLM as an Abstraction (LLMaaA), AI model optimization and unified abstractions across heterogeneous infrastructure, end-to-end edge-cloud transformation, efficient programming model, middleware and platform, secure infrastructure, application-adaptive cloud systems, and new quantum-classical collaborative workflows. These ideas and solutions encompass both theoretical and practical research questions, requiring coordinated input and support from the research community. This joint initiative aims to establish hybrid clouds as secure, efficient, and sustainable platforms, fostering breakthroughs in AI-driven applications and scientific discovery across academia, industry, and society.
Towards Pareto Optimal Throughput in Small Language Model Serving
Apr 04, 2024Large language models (LLMs) have revolutionized the state-of-the-art of many different natural language processing tasks. Although serving LLMs is computationally and memory demanding, the rise of Small Language Models (SLMs) offers new opportunities for resource-constrained users, who now are able to serve small models with cutting-edge performance. In this paper, we present a set of experiments designed to benchmark SLM inference at performance and energy levels. Our analysis provides a new perspective in serving, highlighting that the small memory footprint of SLMs allows for reaching the Pareto-optimal throughput within the resource capacity of a single accelerator. In this regard, we present an initial set of findings demonstrating how model replication can effectively improve resource utilization for serving SLMs.
Standing on FURM ground -- A framework for evaluating Fair, Useful, and Reliable AI Models in healthcare systems
Mar 14, 2024



The impact of using artificial intelligence (AI) to guide patient care or operational processes is an interplay of the AI model's output, the decision-making protocol based on that output, and the capacity of the stakeholders involved to take the necessary subsequent action. Estimating the effects of this interplay before deployment, and studying it in real time afterwards, are essential to bridge the chasm between AI model development and achievable benefit. To accomplish this, the Data Science team at Stanford Health Care has developed a Testing and Evaluation (T&E) mechanism to identify fair, useful and reliable AI models (FURM) by conducting an ethical review to identify potential value mismatches, simulations to estimate usefulness, financial projections to assess sustainability, as well as analyses to determine IT feasibility, design a deployment strategy, and recommend a prospective monitoring and evaluation plan. We report on FURM assessments done to evaluate six AI guided solutions for potential adoption, spanning clinical and operational settings, each with the potential to impact from several dozen to tens of thousands of patients each year. We describe the assessment process, summarize the six assessments, and share our framework to enable others to conduct similar assessments. Of the six solutions we assessed, two have moved into a planning and implementation phase. Our novel contributions - usefulness estimates by simulation, financial projections to quantify sustainability, and a process to do ethical assessments - as well as their underlying methods and open source tools, are available for other healthcare systems to conduct actionable evaluations of candidate AI solutions.
CheXagent: Towards a Foundation Model for Chest X-Ray Interpretation
Jan 22, 2024



Chest X-rays (CXRs) are the most frequently performed imaging test in clinical practice. Recent advances in the development of vision-language foundation models (FMs) give rise to the possibility of performing automated CXR interpretation, which can assist physicians with clinical decision-making and improve patient outcomes. However, developing FMs that can accurately interpret CXRs is challenging due to the (1) limited availability of large-scale vision-language datasets in the medical image domain, (2) lack of vision and language encoders that can capture the complexities of medical data, and (3) absence of evaluation frameworks for benchmarking the abilities of FMs on CXR interpretation. In this work, we address these challenges by first introducing \emph{CheXinstruct} - a large-scale instruction-tuning dataset curated from 28 publicly-available datasets. We then present \emph{CheXagent} - an instruction-tuned FM capable of analyzing and summarizing CXRs. To build CheXagent, we design a clinical large language model (LLM) for parsing radiology reports, a vision encoder for representing CXR images, and a network to bridge the vision and language modalities. Finally, we introduce \emph{CheXbench} - a novel benchmark designed to systematically evaluate FMs across 8 clinically-relevant CXR interpretation tasks. Extensive quantitative evaluations and qualitative reviews with five expert radiologists demonstrate that CheXagent outperforms previously-developed general- and medical-domain FMs on CheXbench tasks. Furthermore, in an effort to improve model transparency, we perform a fairness evaluation across factors of sex, race and age to highlight potential performance disparities. Our project is at \url{https://stanford-aimi.github.io/chexagent.html}.
RadFusion: Benchmarking Performance and Fairness for Multimodal Pulmonary Embolism Detection from CT and EHR
Nov 27, 2021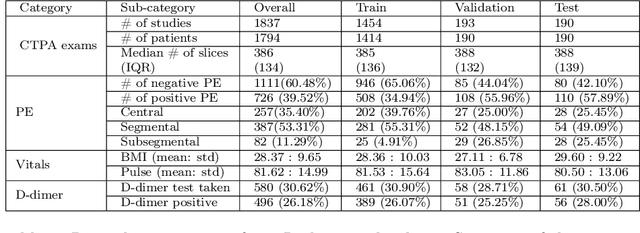
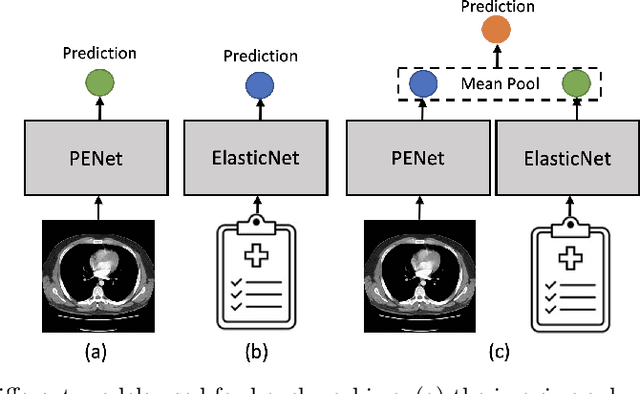
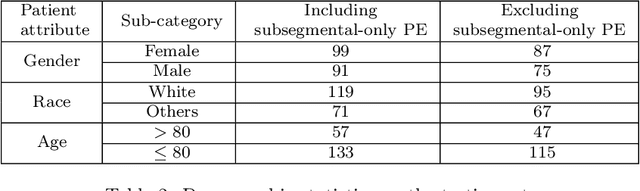
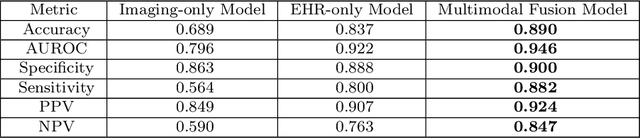
Despite the routine use of electronic health record (EHR) data by radiologists to contextualize clinical history and inform image interpretation, the majority of deep learning architectures for medical imaging are unimodal, i.e., they only learn features from pixel-level information. Recent research revealing how race can be recovered from pixel data alone highlights the potential for serious biases in models which fail to account for demographics and other key patient attributes. Yet the lack of imaging datasets which capture clinical context, inclusive of demographics and longitudinal medical history, has left multimodal medical imaging underexplored. To better assess these challenges, we present RadFusion, a multimodal, benchmark dataset of 1794 patients with corresponding EHR data and high-resolution computed tomography (CT) scans labeled for pulmonary embolism. We evaluate several representative multimodal fusion models and benchmark their fairness properties across protected subgroups, e.g., gender, race/ethnicity, age. Our results suggest that integrating imaging and EHR data can improve classification performance and robustness without introducing large disparities in the true positive rate between population groups.