 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComputing with Living Neurons: Chaos-Controlled Reservoir Computing with Knowledge Transplant
Apr 02, 2026We introduce chaos-controlled Reservoir Computing (cc-RC) for living neural cultures: dynamically rich substrates of unique potential for adaptive computation. To account for intrinsic biological variability, cc-RC combines: (i) pre-training identification of each culture's dynamical signature and phase-portrait attractor; (ii) low-power optical chaos control to stabilize spontaneous and stimulus-evoked activity; (iii) readout training within this controlled regime. Across hundreds of neural samples, cc-RC enables robust learning and pattern classification, improving both accuracy and model longevity by approximately 300% over standard RC. We further propose Knowledge Transplant (KT), for which the reservoir map learned by an expert culture is transplanted to an attractor-equivalent student culture, reducing training time to minutes while improving performance. By enabling cross-substrate, reusable learned models, KT paves the way for knowledge accumulation and sharing across neural populations, transcending biological lifespan limits.
Beyond Pooling: Matching for Robust Generalization under Data Heterogeneity
Feb 06, 2026Pooling heterogeneous datasets across domains is a common strategy in representation learning, but naive pooling can amplify distributional asymmetries and yield biased estimators, especially in settings where zero-shot generalization is required. We propose a matching framework that selects samples relative to an adaptive centroid and iteratively refines the representation distribution. The double robustness and the propensity score matching for the inclusion of data domains make matching more robust than naive pooling and uniform subsampling by filtering out the confounding domains (the main cause of heterogeneity). Theoretical and empirical analyses show that, unlike naive pooling or uniform subsampling, matching achieves better results under asymmetric meta-distributions, which are also extended to non-Gaussian and multimodal real-world settings. Most importantly, we show that these improvements translate to zero-shot medical anomaly detection, one of the extreme forms of data heterogeneity and asymmetry. The code is available on https://github.com/AyushRoy2001/Beyond-Pooling.
SparseJEPA: Sparse Representation Learning of Joint Embedding Predictive Architectures
Apr 22, 2025Joint Embedding Predictive Architectures (JEPA) have emerged as a powerful framework for learning general-purpose representations. However, these models often lack interpretability and suffer from inefficiencies due to dense embedding representations. We propose SparseJEPA, an extension that integrates sparse representation learning into the JEPA framework to enhance the quality of learned representations. SparseJEPA employs a penalty method that encourages latent space variables to be shared among data features with strong semantic relationships, while maintaining predictive performance. We demonstrate the effectiveness of SparseJEPA by training on the CIFAR-100 dataset and pre-training a lightweight Vision Transformer. The improved embeddings are utilized in linear-probe transfer learning for both image classification and low-level tasks, showcasing the architecture's versatility across different transfer tasks. Furthermore, we provide a theoretical proof that demonstrates that the grouping mechanism enhances representation quality. This was done by displaying that grouping reduces Multiinformation among latent-variables, including proofing the Data Processing Inequality for Multiinformation. Our results indicate that incorporating sparsity not only refines the latent space but also facilitates the learning of more meaningful and interpretable representations. In further work, hope to further extend this method by finding new ways to leverage the grouping mechanism through object-centric representation learning.
Transforming the Hybrid Cloud for Emerging AI Workloads
Nov 20, 2024



This white paper, developed through close collaboration between IBM Research and UIUC researchers within the IIDAI Institute, envisions transforming hybrid cloud systems to meet the growing complexity of AI workloads through innovative, full-stack co-design approaches, emphasizing usability, manageability, affordability, adaptability, efficiency, and scalability. By integrating cutting-edge technologies such as generative and agentic AI, cross-layer automation and optimization, unified control plane, and composable and adaptive system architecture, the proposed framework addresses critical challenges in energy efficiency, performance, and cost-effectiveness. Incorporating quantum computing as it matures will enable quantum-accelerated simulations for materials science, climate modeling, and other high-impact domains. Collaborative efforts between academia and industry are central to this vision, driving advancements in foundation models for material design and climate solutions, scalable multimodal data processing, and enhanced physics-based AI emulators for applications like weather forecasting and carbon sequestration. Research priorities include advancing AI agentic systems, LLM as an Abstraction (LLMaaA), AI model optimization and unified abstractions across heterogeneous infrastructure, end-to-end edge-cloud transformation, efficient programming model, middleware and platform, secure infrastructure, application-adaptive cloud systems, and new quantum-classical collaborative workflows. These ideas and solutions encompass both theoretical and practical research questions, requiring coordinated input and support from the research community. This joint initiative aims to establish hybrid clouds as secure, efficient, and sustainable platforms, fostering breakthroughs in AI-driven applications and scientific discovery across academia, industry, and society.
Learning Transfers over Several Programming Languages
Oct 25, 2023



Large language models (LLMs) have recently become remarkably good at improving developer productivity for high-resource programming languages. These models use two kinds of data: large amounts of unlabeled code samples for pretraining and relatively smaller amounts of labeled code samples for fine-tuning or in-context learning. Unfortunately, many programming languages are low-resource, lacking labeled samples for most tasks and often even lacking unlabeled samples. Therefore, users of low-resource languages (e.g., legacy or new languages) miss out on the benefits of LLMs. Cross-lingual transfer learning uses data from a source language to improve model performance on a target language. It has been well-studied for natural languages, but has received little attention for programming languages. This paper reports extensive experiments on four tasks using a transformer-based LLM and 11 to 41 programming languages to explore the following questions. First, how well cross-lingual transfer works for a given task across different language pairs. Second, given a task and target language, how to best choose a source language. Third, the characteristics of a language pair that are predictive of transfer performance, and fourth, how that depends on the given task.
Universal Clustering via Crowdsourcing
Oct 05, 2016



Consider unsupervised clustering of objects drawn from a discrete set, through the use of human intelligence available in crowdsourcing platforms. This paper defines and studies the problem of universal clustering using responses of crowd workers, without knowledge of worker reliability or task difficulty. We model stochastic worker response distributions by incorporating traits of memory for similar objects and traits of distance among differing objects. We are particularly interested in two limiting worker types---temporary workers who retain no memory of responses and long-term workers with memory. We first define clustering algorithms for these limiting cases and then integrate them into an algorithm for the unified worker model. We prove asymptotic consistency of the algorithms and establish sufficient conditions on the sample complexity of the algorithm. Converse arguments establish necessary conditions on sample complexity, proving that the defined algorithms are asymptotically order-optimal in cost.
Neural Networks Built from Unreliable Components
May 31, 2013

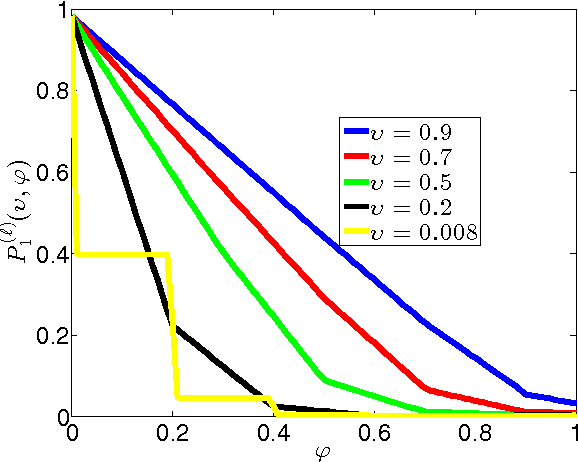
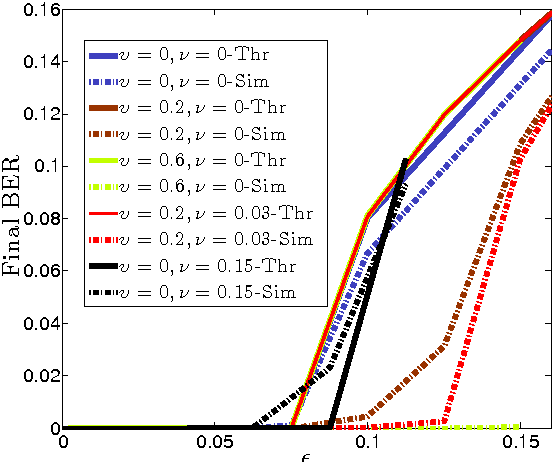
Recent advances in associative memory design through strutured pattern sets and graph-based inference algorithms have allowed the reliable learning and retrieval of an exponential number of patterns. Both these and classical associative memories, however, have assumed internally noiseless computational nodes. This paper considers the setting when internal computations are also noisy. Even if all components are noisy, the final error probability in recall can often be made exceedingly small, as we characterize. There is a threshold phenomenon. We also show how to optimize inference algorithm parameters when knowing statistical properties of internal noise.