 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGRIP: Feedback-Guided Prompt Retrieval for Large Multimodal Models
Jun 10, 2026In-Context Learning (ICL) has become a powerful mechanism for adapting Large Language Models (LLMs) to new tasks without fine-tuning. Extending this concept to Large Multimodal Models (LMMs), Multimodal In-Context Learning (M-ICL) relies on retrieving relevant examples, such as images, captions, or question-answer pairs, to guide predictions across tasks like classification, captioning, and visual question answering (VQA). Most existing approaches select in-context examples based on feature-space similarity, assuming that semantically similar samples provide the most useful context. However, our systematic analysis reveals that this assumption does not always hold: visually similar examples are not necessarily those that most effectively enhance in-context learning performance. To address this, we propose the Guided Retrieval of In-context Prompts (GRIP), a learnable vision-only retrieval framework that leverages feedback from LMMs to identify examples that truly improve model predictions. GRIP learns to distinguish beneficial from detrimental in-context examples through contrastive training, refining retrieval beyond pure similarity. Across three multimodal tasks, namely classification, captioning, and VQA, GRIP improves consistently over similarity-based retrieval on Qwen2.5-VL-7B, with its strongest gains in classification on Idefics2-8B. Moreover, we demonstrate that retrievers trained with feedback from one open LMM can be transferred to other models without retraining, including closed-source GPT-4o and Gemini, enabling scalable and cost-efficient deployment of M-ICL. Code will be published upon acceptance.
Transforming the Hybrid Cloud for Emerging AI Workloads
Nov 20, 2024



This white paper, developed through close collaboration between IBM Research and UIUC researchers within the IIDAI Institute, envisions transforming hybrid cloud systems to meet the growing complexity of AI workloads through innovative, full-stack co-design approaches, emphasizing usability, manageability, affordability, adaptability, efficiency, and scalability. By integrating cutting-edge technologies such as generative and agentic AI, cross-layer automation and optimization, unified control plane, and composable and adaptive system architecture, the proposed framework addresses critical challenges in energy efficiency, performance, and cost-effectiveness. Incorporating quantum computing as it matures will enable quantum-accelerated simulations for materials science, climate modeling, and other high-impact domains. Collaborative efforts between academia and industry are central to this vision, driving advancements in foundation models for material design and climate solutions, scalable multimodal data processing, and enhanced physics-based AI emulators for applications like weather forecasting and carbon sequestration. Research priorities include advancing AI agentic systems, LLM as an Abstraction (LLMaaA), AI model optimization and unified abstractions across heterogeneous infrastructure, end-to-end edge-cloud transformation, efficient programming model, middleware and platform, secure infrastructure, application-adaptive cloud systems, and new quantum-classical collaborative workflows. These ideas and solutions encompass both theoretical and practical research questions, requiring coordinated input and support from the research community. This joint initiative aims to establish hybrid clouds as secure, efficient, and sustainable platforms, fostering breakthroughs in AI-driven applications and scientific discovery across academia, industry, and society.
Detection and Positive Reconstruction of Cognitive Distortion sentences: Mandarin Dataset and Evaluation
May 24, 2024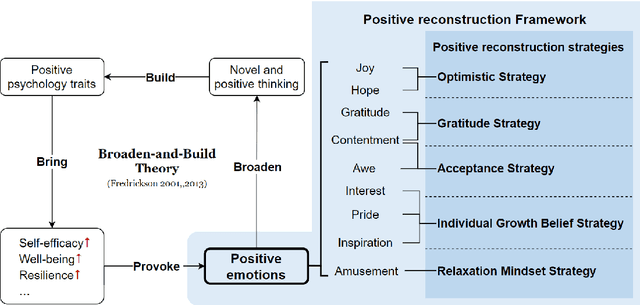

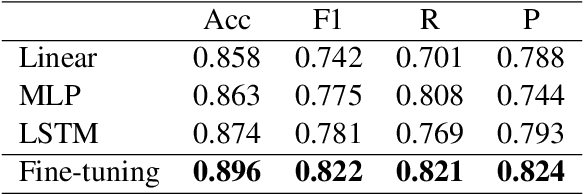

This research introduces a Positive Reconstruction Framework based on positive psychology theory. Overcoming negative thoughts can be challenging, our objective is to address and reframe them through a positive reinterpretation. To tackle this challenge, a two-fold approach is necessary: identifying cognitive distortions and suggesting a positively reframed alternative while preserving the original thought's meaning. Recent studies have investigated the application of Natural Language Processing (NLP) models in English for each stage of this process. In this study, we emphasize the theoretical foundation for the Positive Reconstruction Framework, grounded in broaden-and-build theory. We provide a shared corpus containing 4001 instances for detecting cognitive distortions and 1900 instances for positive reconstruction in Mandarin. Leveraging recent NLP techniques, including transfer learning, fine-tuning pretrained networks, and prompt engineering, we demonstrate the effectiveness of automated tools for both tasks. In summary, our study contributes to multilingual positive reconstruction, highlighting the effectiveness of NLP in cognitive distortion detection and positive reconstruction.
MV-Map: Offboard HD-Map Generation with Multi-view Consistency
May 15, 2023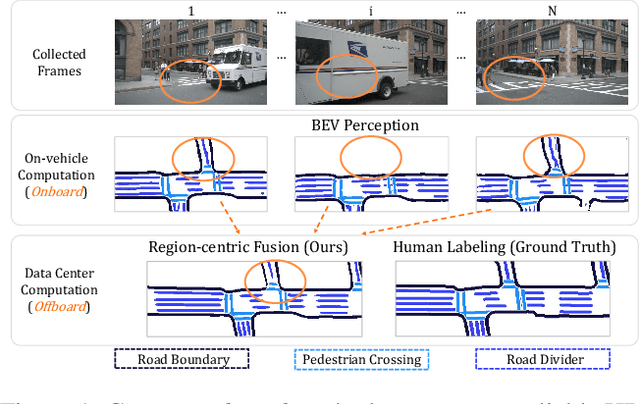



While bird's-eye-view (BEV) perception models can be useful for building high-definition maps (HD-Maps) with less human labor, their results are often unreliable and demonstrate noticeable inconsistencies in the predicted HD-Maps from different viewpoints. This is because BEV perception is typically set up in an 'onboard' manner, which restricts the computation and consequently prevents algorithms from reasoning multiple views simultaneously. This paper overcomes these limitations and advocates a more practical 'offboard' HD-Map generation setup that removes the computation constraints, based on the fact that HD-Maps are commonly reusable infrastructures built offline in data centers. To this end, we propose a novel offboard pipeline called MV-Map that capitalizes multi-view consistency and can handle an arbitrary number of frames with the key design of a 'region-centric' framework. In MV-Map, the target HD-Maps are created by aggregating all the frames of onboard predictions, weighted by the confidence scores assigned by an 'uncertainty network'. To further enhance multi-view consistency, we augment the uncertainty network with the global 3D structure optimized by a voxelized neural radiance field (Voxel-NeRF). Extensive experiments on nuScenes show that our MV-Map significantly improves the quality of HD-Maps, further highlighting the importance of offboard methods for HD-Map generation.
SIRfyN: Single Image Relighting from your Neighbors
Dec 08, 2021
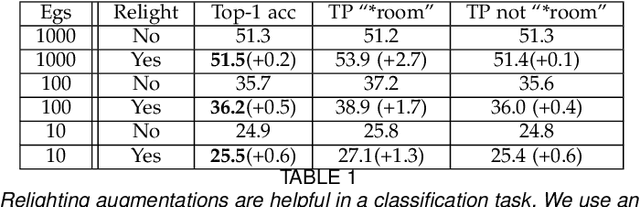
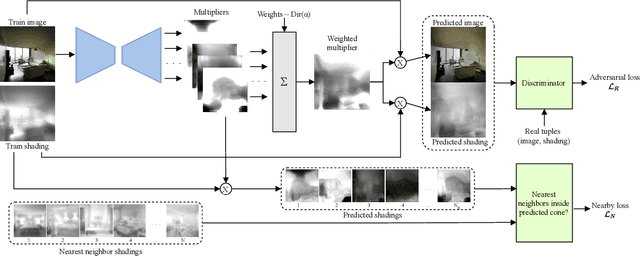
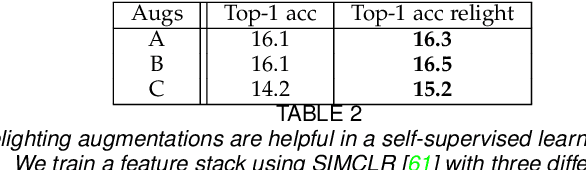
We show how to relight a scene, depicted in a single image, such that (a) the overall shading has changed and (b) the resulting image looks like a natural image of that scene. Applications for such a procedure include generating training data and building authoring environments. Naive methods for doing this fail. One reason is that shading and albedo are quite strongly related; for example, sharp boundaries in shading tend to appear at depth discontinuities, which usually apparent in albedo. The same scene can be lit in different ways, and established theory shows the different lightings form a cone (the illumination cone). Novel theory shows that one can use similar scenes to estimate the different lightings that apply to a given scene, with bounded expected error. Our method exploits this theory to estimate a representation of the available lighting fields in the form of imputed generators of the illumination cone. Our procedure does not require expensive "inverse graphics" datasets, and sees no ground truth data of any kind. Qualitative evaluation suggests the method can erase and restore soft indoor shadows, and can "steer" light around a scene. We offer a summary quantitative evaluation of the method with a novel application of the FID. An extension of the FID allows per-generated-image evaluation. Furthermore, we offer qualitative evaluation with a user study, and show that our method produces images that can successfully be used for data augmentation.
DIVeR: Real-time and Accurate Neural Radiance Fields with Deterministic Integration for Volume Rendering
Nov 19, 2021
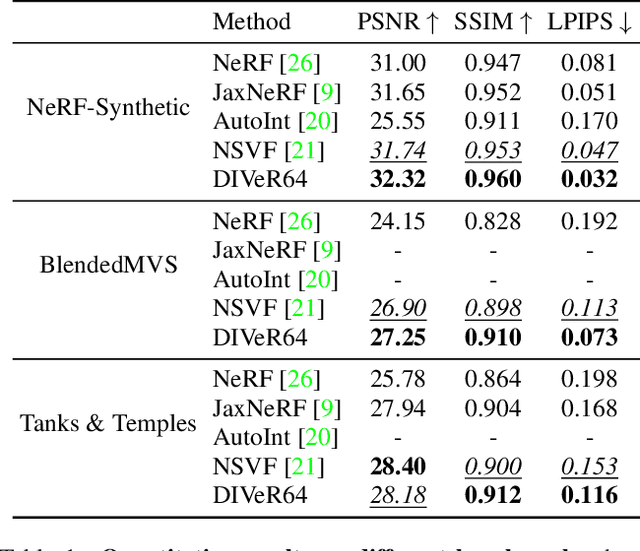
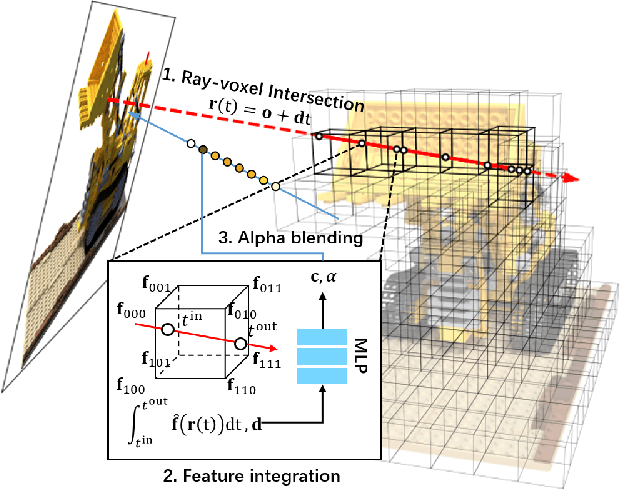
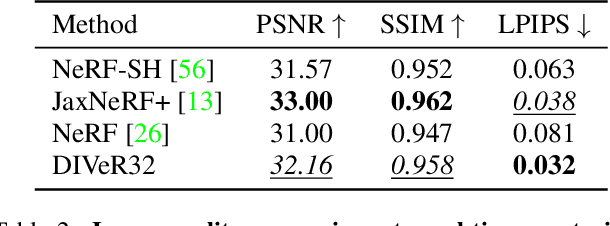
DIVeR builds on the key ideas of NeRF and its variants -- density models and volume rendering -- to learn 3D object models that can be rendered realistically from small numbers of images. In contrast to all previous NeRF methods, DIVeR uses deterministic rather than stochastic estimates of the volume rendering integral. DIVeR's representation is a voxel based field of features. To compute the volume rendering integral, a ray is broken into intervals, one per voxel; components of the volume rendering integral are estimated from the features for each interval using an MLP, and the components are aggregated. As a result, DIVeR can render thin translucent structures that are missed by other integrators. Furthermore, DIVeR's representation has semantics that is relatively exposed compared to other such methods -- moving feature vectors around in the voxel space results in natural edits. Extensive qualitative and quantitative comparisons to current state-of-the-art methods show that DIVeR produces models that (1) render at or above state-of-the-art quality, (2) are very small without being baked, (3) render very fast without being baked, and (4) can be edited in natural ways.