 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovering Semantic Latent Structures in Psychological Scales: A Response-Free Pathway to Efficient Simplification
Feb 13, 2026Psychological scale refinement traditionally relies on response-based methods such as factor analysis, item response theory, and network psychometrics to optimize item composition. Although rigorous, these approaches require large samples and may be constrained by data availability and cross-cultural comparability. Recent advances in natural language processing suggest that the semantic structure of questionnaire items may encode latent construct organization, offering a complementary response-free perspective. We introduce a topic-modeling framework that operationalizes semantic latent structure for scale simplification. Items are encoded using contextual sentence embeddings and grouped via density-based clustering to discover latent semantic factors without predefining their number. Class-based term weighting derives interpretable topic representations that approximate constructs and enable merging of semantically adjacent clusters. Representative items are selected using membership criteria within an integrated reduction pipeline. We benchmarked the framework across DASS, IPIP, and EPOCH, evaluating structural recovery, internal consistency, factor congruence, correlation preservation, and reduction efficiency. The proposed method recovered coherent factor-like groupings aligned with established constructs. Selected items reduced scale length by 60.5% on average while maintaining psychometric adequacy. Simplified scales showed high concordance with original factor structures and preserved inter-factor correlations, indicating that semantic latent organization provides a response-free approximation of measurement structure. Our framework formalizes semantic structure as an inspectable front-end for scale construction and reduction. To facilitate adoption, we provide a visualization-supported tool enabling one-click semantic analysis and structured simplification.
A Review of Human Emotion Synthesis Based on Generative Technology
Dec 10, 2024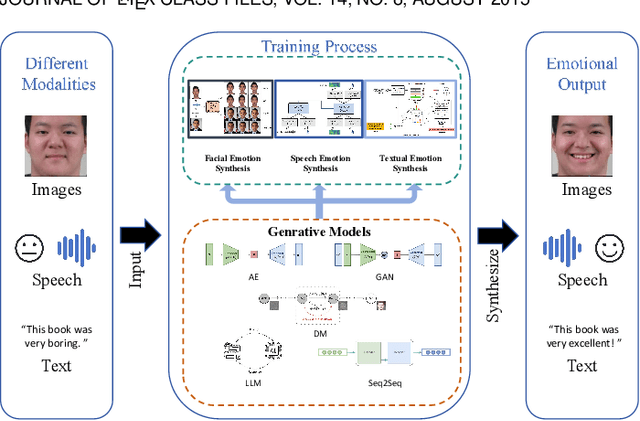
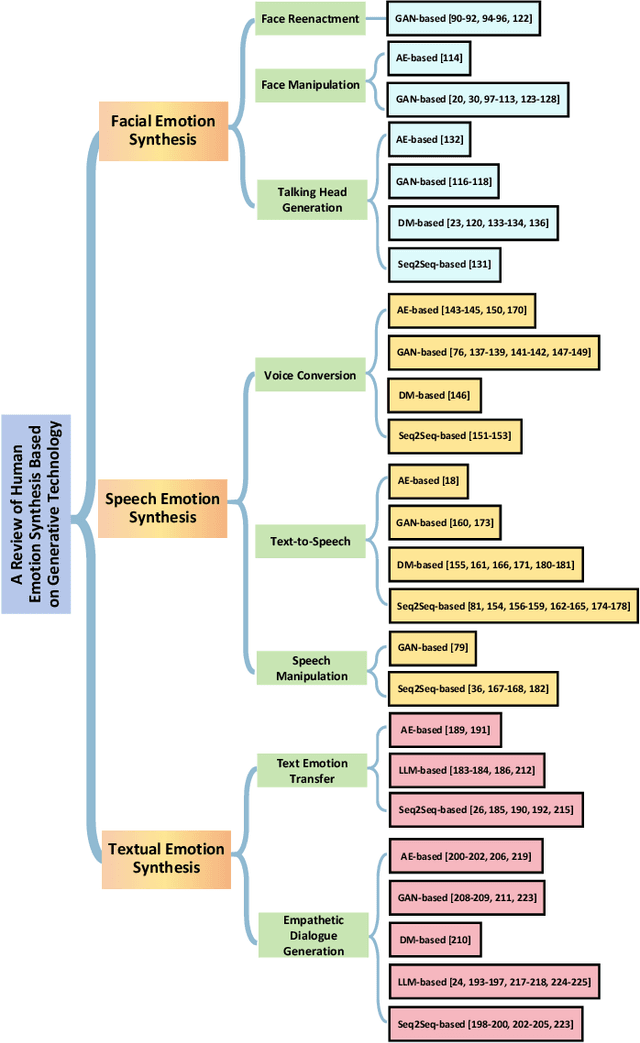
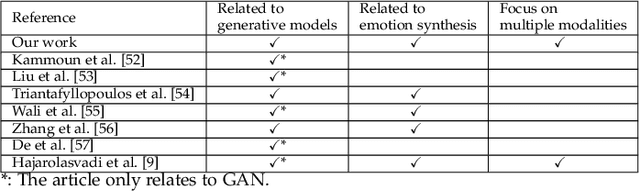
Human emotion synthesis is a crucial aspect of affective computing. It involves using computational methods to mimic and convey human emotions through various modalities, with the goal of enabling more natural and effective human-computer interactions. Recent advancements in generative models, such as Autoencoders, Generative Adversarial Networks, Diffusion Models, Large Language Models, and Sequence-to-Sequence Models, have significantly contributed to the development of this field. However, there is a notable lack of comprehensive reviews in this field. To address this problem, this paper aims to address this gap by providing a thorough and systematic overview of recent advancements in human emotion synthesis based on generative models. Specifically, this review will first present the review methodology, the emotion models involved, the mathematical principles of generative models, and the datasets used. Then, the review covers the application of different generative models to emotion synthesis based on a variety of modalities, including facial images, speech, and text. It also examines mainstream evaluation metrics. Additionally, the review presents some major findings and suggests future research directions, providing a comprehensive understanding of the role of generative technology in the nuanced domain of emotion synthesis.
Generative Technology for Human Emotion Recognition: A Scope Review
Jul 04, 2024



Affective computing stands at the forefront of artificial intelligence (AI), seeking to imbue machines with the ability to comprehend and respond to human emotions. Central to this field is emotion recognition, which endeavors to identify and interpret human emotional states from different modalities, such as speech, facial images, text, and physiological signals. In recent years, important progress has been made in generative models, including Autoencoder, Generative Adversarial Network, Diffusion Model, and Large Language Model. These models, with their powerful data generation capabilities, emerge as pivotal tools in advancing emotion recognition. However, up to now, there remains a paucity of systematic efforts that review generative technology for emotion recognition. This survey aims to bridge the gaps in the existing literature by conducting a comprehensive analysis of over 320 research papers until June 2024. Specifically, this survey will firstly introduce the mathematical principles of different generative models and the commonly used datasets. Subsequently, through a taxonomy, it will provide an in-depth analysis of how generative techniques address emotion recognition based on different modalities in several aspects, including data augmentation, feature extraction, semi-supervised learning, cross-domain, etc. Finally, the review will outline future research directions, emphasizing the potential of generative models to advance the field of emotion recognition and enhance the emotional intelligence of AI systems.
Detection and Positive Reconstruction of Cognitive Distortion sentences: Mandarin Dataset and Evaluation
May 24, 2024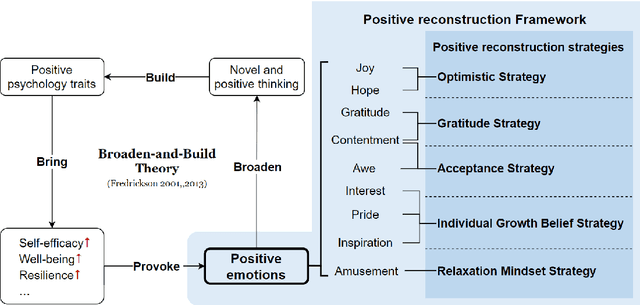

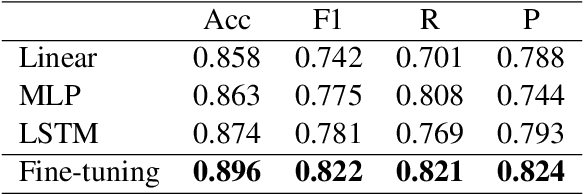

This research introduces a Positive Reconstruction Framework based on positive psychology theory. Overcoming negative thoughts can be challenging, our objective is to address and reframe them through a positive reinterpretation. To tackle this challenge, a two-fold approach is necessary: identifying cognitive distortions and suggesting a positively reframed alternative while preserving the original thought's meaning. Recent studies have investigated the application of Natural Language Processing (NLP) models in English for each stage of this process. In this study, we emphasize the theoretical foundation for the Positive Reconstruction Framework, grounded in broaden-and-build theory. We provide a shared corpus containing 4001 instances for detecting cognitive distortions and 1900 instances for positive reconstruction in Mandarin. Leveraging recent NLP techniques, including transfer learning, fine-tuning pretrained networks, and prompt engineering, we demonstrate the effectiveness of automated tools for both tasks. In summary, our study contributes to multilingual positive reconstruction, highlighting the effectiveness of NLP in cognitive distortion detection and positive reconstruction.
A Finger on the Pulse of Cardiovascular Health: Smartphone Photoplethysmography-Based Pulse Waveform Analysis for Blood Pressure Measurement
Jan 20, 2024Routine blood pressure (BP) monitoring, crucial for health assessment, faces challenges such as limited access to medical-grade equipment and expertise. Portable cuff BP devices, on the other hand, are cumbersome to carry all day and often cost-prohibitive in less developed countries. Besides, these sphygmomanometer-based devices can cause discomfort and disrupt blood flow during measurement. This study explores the use of smartphones for continuous BP monitoring, focusing on overcoming the trust barriers associated with the opacity of machine learning models in predicting BP from low-quality PPG signals. Our approach included developing models based on cardiovascular literature, using simple statistical methods to estimate BP from smartphone PPG signals with comprehensive data pre-processing, applying SHAP for enhanced interpretability and feature identification, and comparing our methods against standard references using Bland-Altman analysis. Validated with data from 125 participants, the study demonstrated significant correlations in waveform features between smartphone and reference BP monitoring devices. The cross-validation of linear regression [MAE=9.86 and 8.01 mmHg for systolic blood pressure (SBP) and diastolic blood pressure (DBP), respectively] and random forest model (MAE=8.91 and 6.68 mmHg for SBP and DBP) using waveform-only variables demonstrated the feasibility of using a smartphone to estimate BP. Although SHAP analysis identified key feature sets, Bland-Altman results did not fully meet established thresholds (84.64% and 94.69% of MAE<15 mmHg for SBP and DBP, respectively). The study suggests the potential of smartphone cameras to enhance the accuracy and interpretability of machine learning models for daily BP estimation, but also indicates that smartphone PPG-based BP prediction is not yet a replacement for traditional medical devices.