 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Review of Human Emotion Synthesis Based on Generative Technology
Dec 10, 2024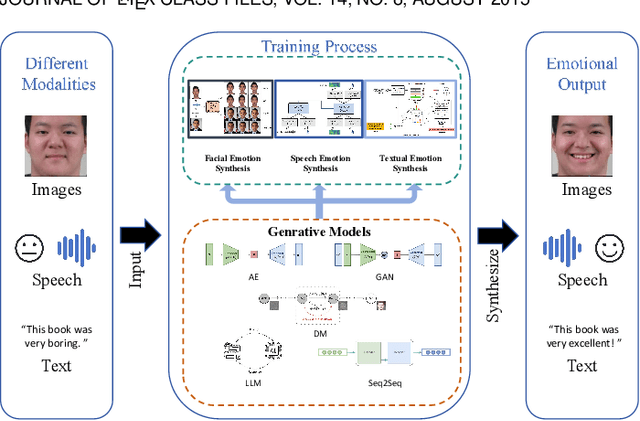
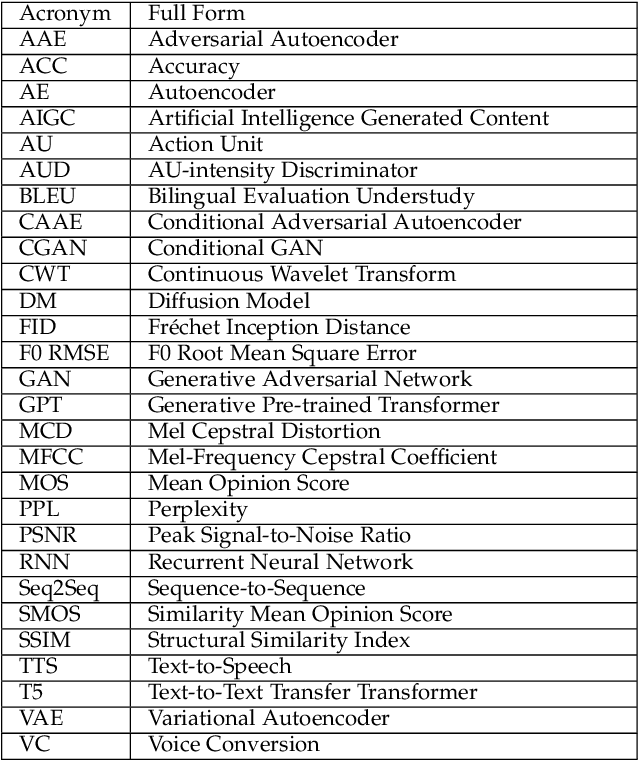
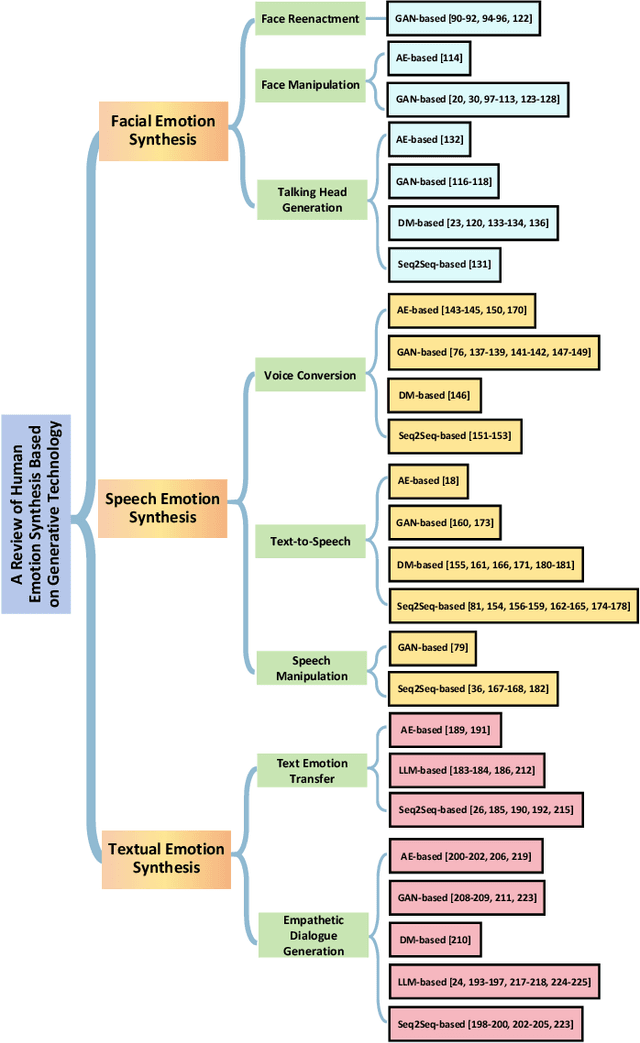
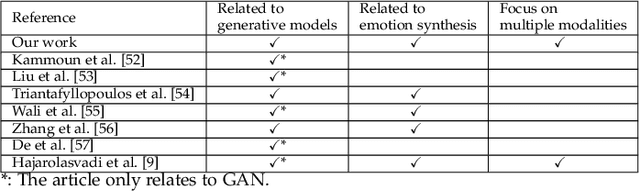
Human emotion synthesis is a crucial aspect of affective computing. It involves using computational methods to mimic and convey human emotions through various modalities, with the goal of enabling more natural and effective human-computer interactions. Recent advancements in generative models, such as Autoencoders, Generative Adversarial Networks, Diffusion Models, Large Language Models, and Sequence-to-Sequence Models, have significantly contributed to the development of this field. However, there is a notable lack of comprehensive reviews in this field. To address this problem, this paper aims to address this gap by providing a thorough and systematic overview of recent advancements in human emotion synthesis based on generative models. Specifically, this review will first present the review methodology, the emotion models involved, the mathematical principles of generative models, and the datasets used. Then, the review covers the application of different generative models to emotion synthesis based on a variety of modalities, including facial images, speech, and text. It also examines mainstream evaluation metrics. Additionally, the review presents some major findings and suggests future research directions, providing a comprehensive understanding of the role of generative technology in the nuanced domain of emotion synthesis.