 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVISTA: Auditing Semantic Divergence in Vision-Language Models
Jul 03, 2026Vision-language models can exhibit visual concept-conditioned divergence: given images containing demographic features, corporate logos, or ideological symbols, some models produce unusually uniform responses that differ from what peer models say about the same input. These behaviors evade text-only audits because visual concepts cannot be isolated or substituted the way text tokens can. We present VISTA (Visual Inconsistency Screening Through Analysis), a black-box cross-model audit that couples semantic entropy with distribution-based divergence to flag model-specific anomalies. In a controlled study, we implant concept-conditioned stances in three VLMs via fine-tuning on small biased datasets and confirm that VISTA detects them. Auditing six VLMs across 19 topics, VISTA surfaces 142 high-suspicion cases (1.2%) and identifies selective refusal as a previously unreported divergence pattern, where models refuse demographic queries at rates varying from 0 to 65% across groups.
Beyond Static Collision Handling: Adaptive Semantic ID Learning for Multimodal Recommendation at Industrial Scale
Apr 26, 2026Modern recommendation systems involve massive catalogs of multimodal items, where scalable item identification must balance compactness, semantic fidelity, and downstream effectiveness. Semantic IDs (SIDs) address this need by representing items as short discrete token sequences derived from multimodal signals, providing a compact interface for retrieval, ranking, and generative recommendation. However, effective SID learning is hindered by collisions, where different items are assigned identical or highly confusable codes. Existing methods mainly rely on improved quantization or fixed overlap regularization, but they do not adaptively distinguish whether an overlap should be suppressed or preserved. We propose AdaSID, an adaptive semantic ID learning framework for recommendation. AdaSID regulates SID overlaps through a two-stage process. First, it relaxes repulsion for observed overlaps when the involved items are semantically compatible, preserving admissible sharing rather than uniformly separating all collisions. Second, it allocates the remaining regulation pressure according to local collision load and training progress, strengthening control in congested regions while gradually rebalancing optimization toward recommendation alignment. This design adaptively decides which overlaps to penalize, how strongly to regulate them, and when to shift the learning focus. Extensive offline and online experiments validate AdaSID. On two public benchmarks, AdaSID improves Recall and NDCG by about 4.5% on average over strong baselines, while improving codebook utilization and SID diversity. In Kuaishou e-commerce, an online A/B test on short-video retrieval covering tens of millions of users achieves statistically significant gains, including a 0.98% GMV improvement, and industrial ranking evaluation shows consistent AUC improvements.
Beyond Explicit Refusals: Soft-Failure Attacks on Retrieval-Augmented Generation
Apr 20, 2026Existing jamming attacks on Retrieval-Augmented Generation (RAG) systems typically induce explicit refusals or denial-of-service behaviors, which are conspicuous and easy to detect. In this work, we formalize a subtler availability threat, termed soft failure, which degrades system utility by inducing fluent and coherent yet non-informative responses rather than overt failures. We propose Deceptive Evolutionary Jamming Attack (DEJA), an automated black-box attack framework that generates adversarial documents to trigger such soft failures by exploiting safety-aligned behaviors of large language models. DEJA employs an evolutionary optimization process guided by a fine-grained Answer Utility Score (AUS), computed via an LLM-based evaluator, to systematically degrade the certainty of answers while maintaining high retrieval success. Extensive experiments across multiple RAG configurations and benchmark datasets show that DEJA consistently drives responses toward low-utility soft failures, achieving SASR above 79\% while keeping hard-failure rates below 15\%, significantly outperforming prior attacks. The resulting adversarial documents exhibit high stealth, evading perplexity-based detection and resisting query paraphrasing, and transfer across model families to proprietary systems without retargeting.
EthicMind: A Risk-Aware Framework for Ethical-Emotional Alignment in Multi-Turn Dialogue
Apr 10, 2026Intelligent dialogue systems are increasingly deployed in emotionally and ethically sensitive settings, where failures in either emotional attunement or ethical judgment can cause significant harm. Existing dialogue models typically address empathy and ethical safety in isolation, and often fail to adapt their behavior as ethical risk and user emotion evolve across multi-turn interactions. We formulate ethical-emotional alignment in dialogue as an explicit turn-level decision problem, and propose \textsc{EthicMind}, a risk-aware framework that implements this formulation in multi-turn dialogue at inference time. At each turn, \textsc{EthicMind} jointly analyzes ethical risk signals and user emotion, plans a high-level response strategy, and generates context-sensitive replies that balance ethical guidance with emotional engagement, without requiring additional model training. To evaluate alignment behavior under ethically complex interactions, we introduce a risk-stratified, multi-turn evaluation protocol with a context-aware user simulation procedure. Experimental results show that \textsc{EthicMind} achieves more consistent ethical guidance and emotional engagement than competitive baselines, particularly in high-risk and morally ambiguous scenarios.
Breakdowns in Conversational AI: Interactional Failures in Emotionally and Ethically Sensitive Contexts
Apr 03, 2026Conversational AI is increasingly deployed in emotionally charged and ethically sensitive interactions. Previous research has primarily concentrated on emotional benchmarks or static safety checks, overlooking how alignment unfolds in evolving conversation. We explore the research question: what breakdowns arise when conversational agents confront emotionally and ethically sensitive behaviors, and how do these affect dialogue quality? To stress-test chatbot performance, we develop a persona-conditioned user simulator capable of engaging in multi-turn dialogue with psychological personas and staged emotional pacing. Our analysis reveals that mainstream models exhibit recurrent breakdowns that intensify as emotional trajectories escalate. We identify several common failure patterns, including affective misalignments, ethical guidance failures, and cross-dimensional trade-offs where empathy supersedes or undermines responsibility. We organize these patterns into a taxonomy and discuss the design implications, highlighting the necessity to maintain ethical coherence and affective sensitivity throughout dynamic interactions. The study offers the HCI community a new perspective on the diagnosis and improvement of conversational AI in value-sensitive and emotionally charged contexts.
Stop Treating Collisions Equally: Qualification-Aware Semantic ID Learning for Recommendation at Industrial Scale
Feb 28, 2026Semantic IDs (SIDs) are compact discrete representations derived from multimodal item features, serving as a unified abstraction for ID-based and generative recommendation. However, learning high-quality SIDs remains challenging due to two issues. (1) Collision problem: the quantized token space is prone to collisions, in which semantically distinct items are assigned identical or overly similar SID compositions, resulting in semantic entanglement. (2) Collision-signal heterogeneity: collisions are not uniformly harmful. Some reflect genuine conflicts between semantically unrelated items, while others stem from benign redundancy or systematic data effects. To address these challenges, we propose Qualification-Aware Semantic ID Learning (QuaSID), an end-to-end framework that learns collision-qualified SIDs by selectively repelling qualified conflict pairs and scaling the repulsion strength by collision severity. QuaSID consists of two mechanisms: Hamming-guided Margin Repulsion, which translates low-Hamming SID overlaps into explicit, severity-scaled geometric constraints on the encoder space; and Conflict-Aware Valid Pair Masking, which masks protocol-induced benign overlaps to denoise repulsion supervision. In addition, QuaSID incorporates a dual-tower contrastive objective to inject collaborative signals into tokenization. Experiments on public benchmarks and industrial data validate QuaSID. On public datasets, QuaSID consistently outperforms strong baselines, improving top-K ranking quality by 5.9% over the best baseline while increasing SID composition diversity. In an online A/B test on Kuaishou e-commerce with a 5% traffic split, QuaSID increases ranking GMV-S2 by 2.38% and improves completed orders on cold-start retrieval by up to 6.42%. Finally, we show that the proposed repulsion loss is plug-and-play and enhances a range of SID learning frameworks across datasets.
SSG-Dit: A Spatial Signal Guided Framework for Controllable Video Generation
Aug 23, 2025Controllable video generation aims to synthesize video content that aligns precisely with user-provided conditions, such as text descriptions and initial images. However, a significant challenge persists in this domain: existing models often struggle to maintain strong semantic consistency, frequently generating videos that deviate from the nuanced details specified in the prompts. To address this issue, we propose SSG-DiT (Spatial Signal Guided Diffusion Transformer), a novel and efficient framework for high-fidelity controllable video generation. Our approach introduces a decoupled two-stage process. The first stage, Spatial Signal Prompting, generates a spatially aware visual prompt by leveraging the rich internal representations of a pre-trained multi-modal model. This prompt, combined with the original text, forms a joint condition that is then injected into a frozen video DiT backbone via our lightweight and parameter-efficient SSG-Adapter. This unique design, featuring a dual-branch attention mechanism, allows the model to simultaneously harness its powerful generative priors while being precisely steered by external spatial signals. Extensive experiments demonstrate that SSG-DiT achieves state-of-the-art performance, outperforming existing models on multiple key metrics in the VBench benchmark, particularly in spatial relationship control and overall consistency.
Beyond Empathy: Integrating Diagnostic and Therapeutic Reasoning with Large Language Models for Mental Health Counseling
May 21, 2025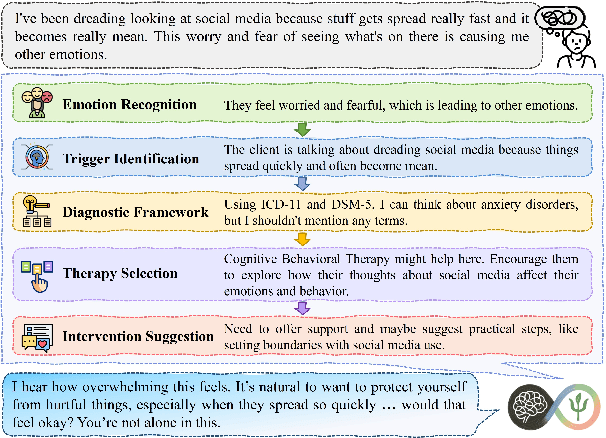

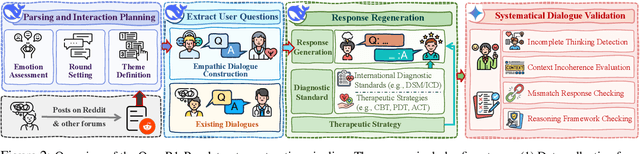
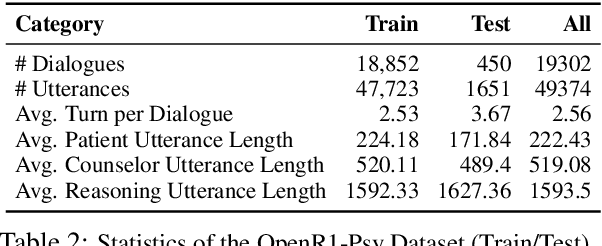
Large language models (LLMs) hold significant potential for mental health support, capable of generating empathetic responses and simulating therapeutic conversations. However, existing LLM-based approaches often lack the clinical grounding necessary for real-world psychological counseling, particularly in explicit diagnostic reasoning aligned with standards like the DSM/ICD and incorporating diverse therapeutic modalities beyond basic empathy or single strategies. To address these critical limitations, we propose PsyLLM, the first large language model designed to systematically integrate both diagnostic and therapeutic reasoning for mental health counseling. To develop the PsyLLM, we propose a novel automated data synthesis pipeline. This pipeline processes real-world mental health posts, generates multi-turn dialogue structures, and leverages LLMs guided by international diagnostic standards (e.g., DSM/ICD) and multiple therapeutic frameworks (e.g., CBT, ACT, psychodynamic) to simulate detailed clinical reasoning processes. Rigorous multi-dimensional filtering ensures the generation of high-quality, clinically aligned dialogue data. In addition, we introduce a new benchmark and evaluation protocol, assessing counseling quality across four key dimensions: comprehensiveness, professionalism, authenticity, and safety. Our experiments demonstrate that PsyLLM significantly outperforms state-of-the-art baseline models on this benchmark.
Road Rage Reasoning with Vision-language Models (VLMs): Task Definition and Evaluation Dataset
Mar 14, 2025Road rage, triggered by driving-related stimuli such as traffic congestion and aggressive driving, poses a significant threat to road safety. Previous research on road rage regulation has primarily focused on response suppression, lacking proactive prevention capabilities. With the advent of Vision-Language Models (VLMs), it has become possible to reason about trigger events visually and then engage in dialog-based comforting before drivers' anger escalates. To this end, we propose the road rage reasoning task, along with a finely annotated test dataset and evaluation metrics, to assess the capabilities of current mainstream VLMs in scene understanding, event recognition, and road rage reasoning. The results indicate that current VLMs exhibit significant shortcomings in scene understanding within the visual modality, as well as in comprehending the spatial relationships between objects in the textual modality. Improving VLMs' performance in these areas will greatly benefit downstream tasks like antecedent-focused road rage regulation.
MDEval: Evaluating and Enhancing Markdown Awareness in Large Language Models
Jan 25, 2025Large language models (LLMs) are expected to offer structured Markdown responses for the sake of readability in web chatbots (e.g., ChatGPT). Although there are a myriad of metrics to evaluate LLMs, they fail to evaluate the readability from the view of output content structure. To this end, we focus on an overlooked yet important metric -- Markdown Awareness, which directly impacts the readability and structure of the content generated by these language models. In this paper, we introduce MDEval, a comprehensive benchmark to assess Markdown Awareness for LLMs, by constructing a dataset with 20K instances covering 10 subjects in English and Chinese. Unlike traditional model-based evaluations, MDEval provides excellent interpretability by combining model-based generation tasks and statistical methods. Our results demonstrate that MDEval achieves a Spearman correlation of 0.791 and an accuracy of 84.1% with human, outperforming existing methods by a large margin. Extensive experimental results also show that through fine-tuning over our proposed dataset, less performant open-source models are able to achieve comparable performance to GPT-4o in terms of Markdown Awareness. To ensure reproducibility and transparency, MDEval is open sourced at https://github.com/SWUFE-DB-Group/MDEval-Benchmark.