 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePunctuation-aware Hybrid Trainable Sparse Attention for Large Language Models
Jan 06, 2026Attention serves as the fundamental mechanism for long-context modeling in large language models (LLMs), yet dense attention becomes structurally prohibitive for long sequences due to its quadratic complexity. Consequently, sparse attention has received increasing attention as a scalable alternative. However, existing sparse attention methods rely on coarse-grained semantic representations during block selection, which blur intra-block semantic boundaries and lead to the loss of critical information. To address this issue, we propose \textbf{P}unctuation-aware \textbf{H}ybrid \textbf{S}parse \textbf{A}ttention \textbf{(PHSA)}, a natively trainable sparse attention framework that leverages punctuation tokens as semantic boundary anchors. Specifically, (1) we design a dual-branch aggregation mechanism that fuses global semantic representations with punctuation-enhanced boundary features, preserving the core semantic structure while introducing almost no additional computational overhead; (2) we introduce an extreme-sparsity-adaptive training and inference strategy that stabilizes model behavior under very low token activation ratios; Extensive experiments on general benchmarks and long-context evaluations demonstrate that PHSA consistently outperforms dense attention and state-of-the-art sparse attention baselines, including InfLLM v2. Specifically, for the 0.6B-parameter model with 32k-token input sequences, PHSA can reduce the information loss by 10.8\% at a sparsity ratio of 97.3\%.
Beyond Empathy: Integrating Diagnostic and Therapeutic Reasoning with Large Language Models for Mental Health Counseling
May 21, 2025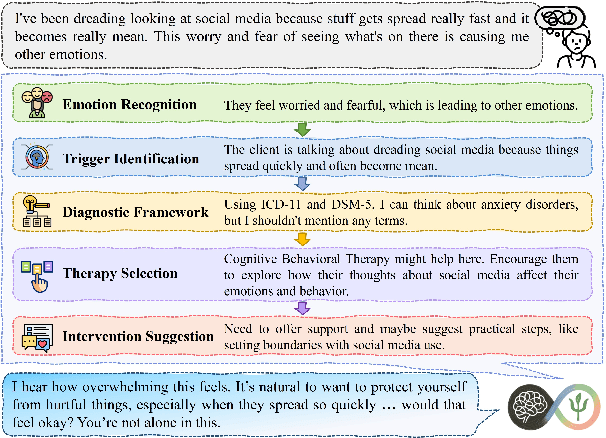

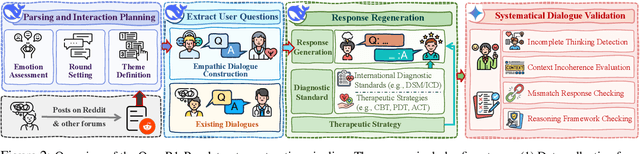
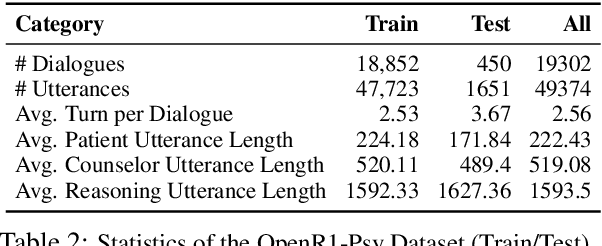
Large language models (LLMs) hold significant potential for mental health support, capable of generating empathetic responses and simulating therapeutic conversations. However, existing LLM-based approaches often lack the clinical grounding necessary for real-world psychological counseling, particularly in explicit diagnostic reasoning aligned with standards like the DSM/ICD and incorporating diverse therapeutic modalities beyond basic empathy or single strategies. To address these critical limitations, we propose PsyLLM, the first large language model designed to systematically integrate both diagnostic and therapeutic reasoning for mental health counseling. To develop the PsyLLM, we propose a novel automated data synthesis pipeline. This pipeline processes real-world mental health posts, generates multi-turn dialogue structures, and leverages LLMs guided by international diagnostic standards (e.g., DSM/ICD) and multiple therapeutic frameworks (e.g., CBT, ACT, psychodynamic) to simulate detailed clinical reasoning processes. Rigorous multi-dimensional filtering ensures the generation of high-quality, clinically aligned dialogue data. In addition, we introduce a new benchmark and evaluation protocol, assessing counseling quality across four key dimensions: comprehensiveness, professionalism, authenticity, and safety. Our experiments demonstrate that PsyLLM significantly outperforms state-of-the-art baseline models on this benchmark.
QA-LoRA: Quantization-Aware Low-Rank Adaptation of Large Language Models
Sep 26, 2023



Recently years have witnessed a rapid development of large language models (LLMs). Despite the strong ability in many language-understanding tasks, the heavy computational burden largely restricts the application of LLMs especially when one needs to deploy them onto edge devices. In this paper, we propose a quantization-aware low-rank adaptation (QA-LoRA) algorithm. The motivation lies in the imbalanced degrees of freedom of quantization and adaptation, and the solution is to use group-wise operators which increase the degree of freedom of quantization meanwhile decreasing that of adaptation. QA-LoRA is easily implemented with a few lines of code, and it equips the original LoRA with two-fold abilities: (i) during fine-tuning, the LLM's weights are quantized (e.g., into INT4) to reduce time and memory usage; (ii) after fine-tuning, the LLM and auxiliary weights are naturally integrated into a quantized model without loss of accuracy. We apply QA-LoRA to the LLaMA and LLaMA2 model families and validate its effectiveness in different fine-tuning datasets and downstream scenarios. Code will be made available at https://github.com/yuhuixu1993/qa-lora.
Pipeline MoE: A Flexible MoE Implementation with Pipeline Parallelism
Apr 22, 2023


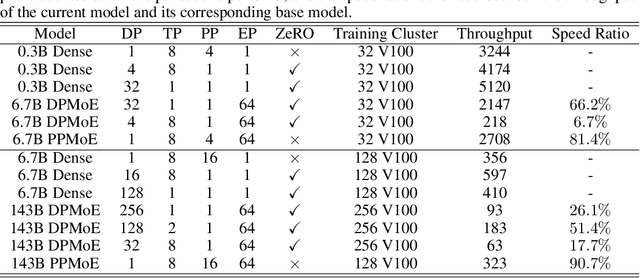
The Mixture of Experts (MoE) model becomes an important choice of large language models nowadays because of its scalability with sublinear computational complexity for training and inference. However, existing MoE models suffer from two critical drawbacks, 1) tremendous inner-node and inter-node communication overhead introduced by all-to-all dispatching and gathering, and 2) limited scalability for the backbone because of the bound data parallel and expert parallel to scale in the expert dimension. In this paper, we systematically analyze these drawbacks in terms of training efficiency in the parallel framework view and propose a novel MoE architecture called Pipeline MoE (PPMoE) to tackle them. PPMoE builds expert parallel incorporating with tensor parallel and replaces communication-intensive all-to-all dispatching and gathering with a simple tensor index slicing and inner-node all-reduce. Besides, it is convenient for PPMoE to integrate pipeline parallel to further scale the backbone due to its flexible parallel architecture. Extensive experiments show that PPMoE not only achieves a more than $1.75\times$ speed up compared to existing MoE architectures but also reaches $90\%$ throughput of its corresponding backbone model that is $20\times$ smaller.
Pangu-Weather: A 3D High-Resolution Model for Fast and Accurate Global Weather Forecast
Nov 03, 2022
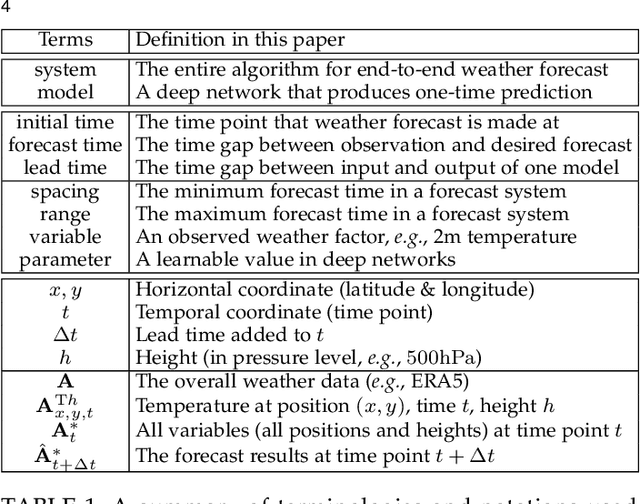


In this paper, we present Pangu-Weather, a deep learning based system for fast and accurate global weather forecast. For this purpose, we establish a data-driven environment by downloading $43$ years of hourly global weather data from the 5th generation of ECMWF reanalysis (ERA5) data and train a few deep neural networks with about $256$ million parameters in total. The spatial resolution of forecast is $0.25^\circ\times0.25^\circ$, comparable to the ECMWF Integrated Forecast Systems (IFS). More importantly, for the first time, an AI-based method outperforms state-of-the-art numerical weather prediction (NWP) methods in terms of accuracy (latitude-weighted RMSE and ACC) of all factors (e.g., geopotential, specific humidity, wind speed, temperature, etc.) and in all time ranges (from one hour to one week). There are two key strategies to improve the prediction accuracy: (i) designing a 3D Earth Specific Transformer (3DEST) architecture that formulates the height (pressure level) information into cubic data, and (ii) applying a hierarchical temporal aggregation algorithm to alleviate cumulative forecast errors. In deterministic forecast, Pangu-Weather shows great advantages for short to medium-range forecast (i.e., forecast time ranges from one hour to one week). Pangu-Weather supports a wide range of downstream forecast scenarios, including extreme weather forecast (e.g., tropical cyclone tracking) and large-member ensemble forecast in real-time. Pangu-Weather not only ends the debate on whether AI-based methods can surpass conventional NWP methods, but also reveals novel directions for improving deep learning weather forecast systems.
Disassembling the Dataset: A Camera Alignment Mechanism for Multiple Tasks in Person Re-identification
Jan 23, 2020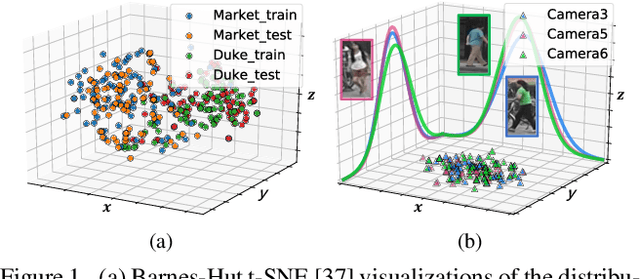
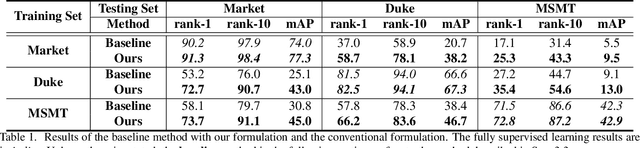
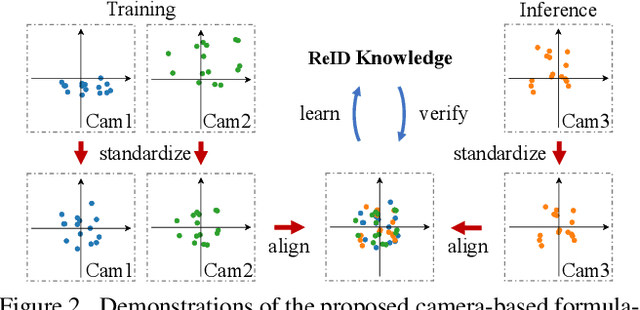
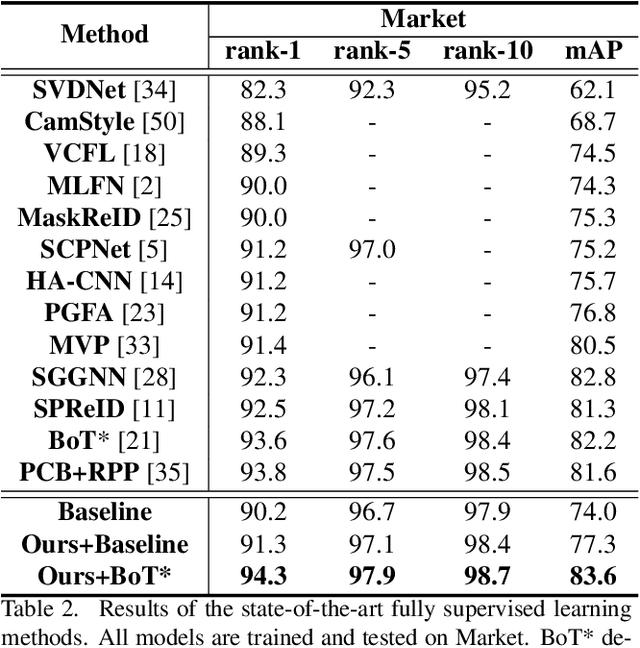
In person re-identification (ReID), one of the main challenges is the distribution inconsistency among different datasets. Previous researchers have defined several seemingly individual topics, such as fully supervised learning, direct transfer, domain adaptation, and incremental learning, each with different settings of training and testing scenarios. These topics are designed in a dataset-wise manner, i.e., images from the same dataset, even from disjoint cameras, are presumed to follow the same distribution. However, such distribution is coarse and training-set-specific, and the ReID knowledge learned in such manner works well only on the corresponding scenarios. To address this issue, we propose a fine-grained distribution alignment formulation, which disassembles the dataset and aligns all training and testing cameras. It connects all topics above and guarantees that ReID knowledge is always learned, accumulated, and verified in the aligned distributions. In practice, we devise the Camera-based Batch Normalization, which is easy for integration and nearly cost-free for existing ReID methods. Extensive experiments on the above four ReID tasks demonstrate the superiority of our approach. The code will be publicly available.
Person Re-identification in the Wild
Apr 06, 2017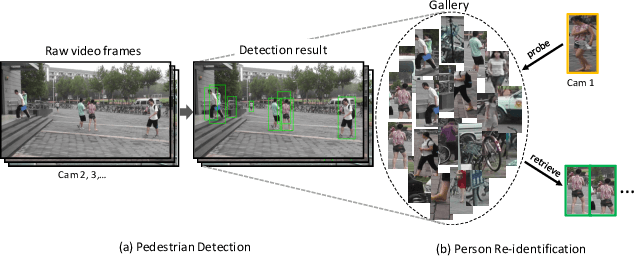



We present a novel large-scale dataset and comprehensive baselines for end-to-end pedestrian detection and person recognition in raw video frames. Our baselines address three issues: the performance of various combinations of detectors and recognizers, mechanisms for pedestrian detection to help improve overall re-identification accuracy and assessing the effectiveness of different detectors for re-identification. We make three distinct contributions. First, a new dataset, PRW, is introduced to evaluate Person Re-identification in the Wild, using videos acquired through six synchronized cameras. It contains 932 identities and 11,816 frames in which pedestrians are annotated with their bounding box positions and identities. Extensive benchmarking results are presented on this dataset. Second, we show that pedestrian detection aids re-identification through two simple yet effective improvements: a discriminatively trained ID-discriminative Embedding (IDE) in the person subspace using convolutional neural network (CNN) features and a Confidence Weighted Similarity (CWS) metric that incorporates detection scores into similarity measurement. Third, we derive insights in evaluating detector performance for the particular scenario of accurate person re-identification.