 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTheraMind: A Strategic and Adaptive Agent for Longitudinal Psychological Counseling
Oct 29, 2025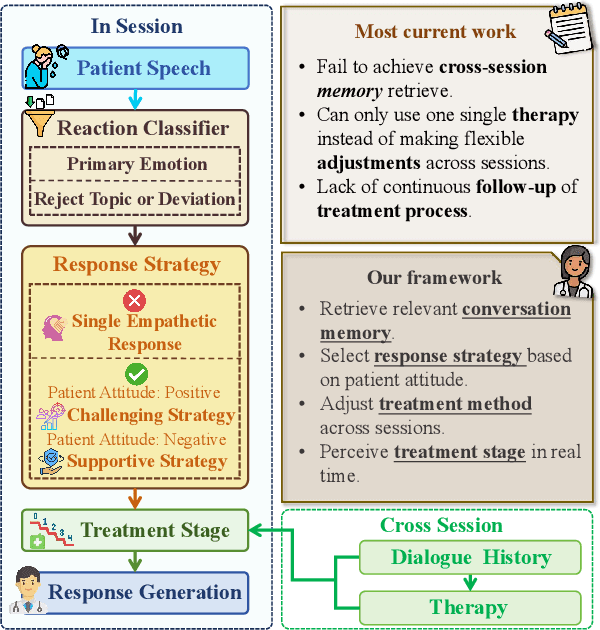
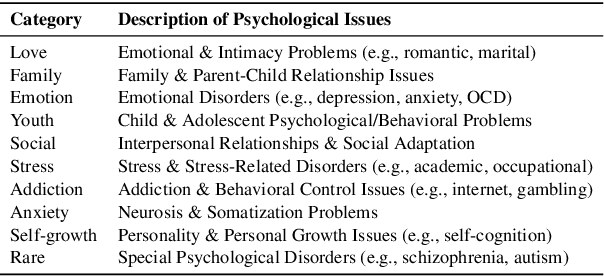
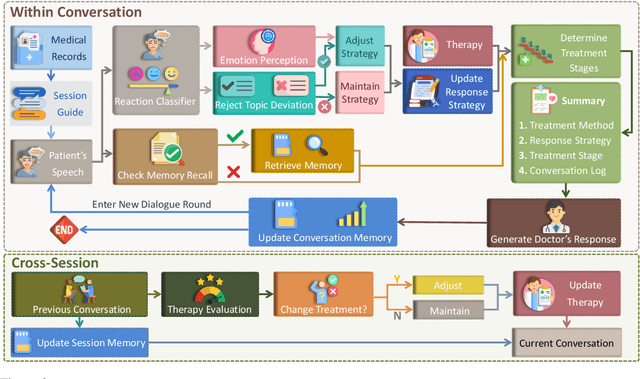
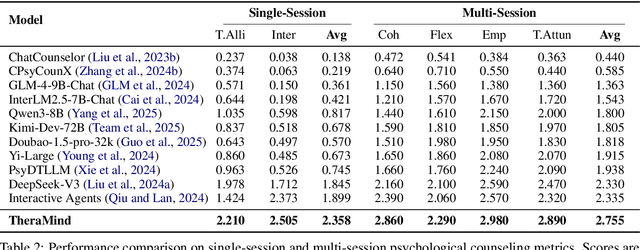
Large language models (LLMs) in psychological counseling have attracted increasing attention. However, existing approaches often lack emotional understanding, adaptive strategies, and the use of therapeutic methods across multiple sessions with long-term memory, leaving them far from real clinical practice. To address these critical gaps, we introduce TheraMind, a strategic and adaptive agent for longitudinal psychological counseling. The cornerstone of TheraMind is a novel dual-loop architecture that decouples the complex counseling process into an Intra-Session Loop for tactical dialogue management and a Cross-Session Loop for strategic therapeutic planning. The Intra-Session Loop perceives the patient's emotional state to dynamically select response strategies while leveraging cross-session memory to ensure continuity. Crucially, the Cross-Session Loop empowers the agent with long-term adaptability by evaluating the efficacy of the applied therapy after each session and adjusting the method for subsequent interactions. We validate our approach in a high-fidelity simulation environment grounded in real clinical cases. Extensive evaluations show that TheraMind outperforms other methods, especially on multi-session metrics like Coherence, Flexibility, and Therapeutic Attunement, validating the effectiveness of its dual-loop design in emulating strategic, adaptive, and longitudinal therapeutic behavior. The code is publicly available at https://0mwwm0.github.io/TheraMind/.
ComplexBench-Edit: Benchmarking Complex Instruction-Driven Image Editing via Compositional Dependencies
Jun 15, 2025Text-driven image editing has achieved remarkable success in following single instructions. However, real-world scenarios often involve complex, multi-step instructions, particularly ``chain'' instructions where operations are interdependent. Current models struggle with these intricate directives, and existing benchmarks inadequately evaluate such capabilities. Specifically, they often overlook multi-instruction and chain-instruction complexities, and common consistency metrics are flawed. To address this, we introduce ComplexBench-Edit, a novel benchmark designed to systematically assess model performance on complex, multi-instruction, and chain-dependent image editing tasks. ComplexBench-Edit also features a new vision consistency evaluation method that accurately assesses non-modified regions by excluding edited areas. Furthermore, we propose a simple yet powerful Chain-of-Thought (CoT)-based approach that significantly enhances the ability of existing models to follow complex instructions. Our extensive experiments demonstrate ComplexBench-Edit's efficacy in differentiating model capabilities and highlight the superior performance of our CoT-based method in handling complex edits. The data and code are released at https://github.com/llllly26/ComplexBench-Edit.
Draw ALL Your Imagine: A Holistic Benchmark and Agent Framework for Complex Instruction-based Image Generation
May 30, 2025Recent advancements in text-to-image (T2I) generation have enabled models to produce high-quality images from textual descriptions. However, these models often struggle with complex instructions involving multiple objects, attributes, and spatial relationships. Existing benchmarks for evaluating T2I models primarily focus on general text-image alignment and fail to capture the nuanced requirements of complex, multi-faceted prompts. Given this gap, we introduce LongBench-T2I, a comprehensive benchmark specifically designed to evaluate T2I models under complex instructions. LongBench-T2I consists of 500 intricately designed prompts spanning nine diverse visual evaluation dimensions, enabling a thorough assessment of a model's ability to follow complex instructions. Beyond benchmarking, we propose an agent framework (Plan2Gen) that facilitates complex instruction-driven image generation without requiring additional model training. This framework integrates seamlessly with existing T2I models, using large language models to interpret and decompose complex prompts, thereby guiding the generation process more effectively. As existing evaluation metrics, such as CLIPScore, fail to adequately capture the nuances of complex instructions, we introduce an evaluation toolkit that automates the quality assessment of generated images using a set of multi-dimensional metrics. The data and code are released at https://github.com/yczhou001/LongBench-T2I.
Beyond Empathy: Integrating Diagnostic and Therapeutic Reasoning with Large Language Models for Mental Health Counseling
May 21, 2025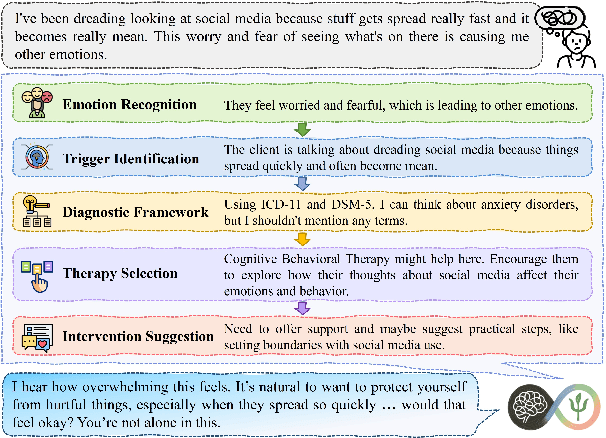

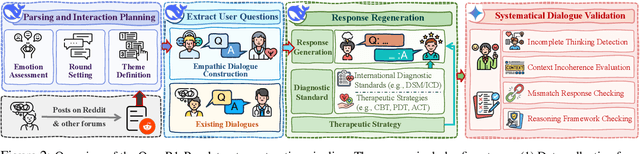
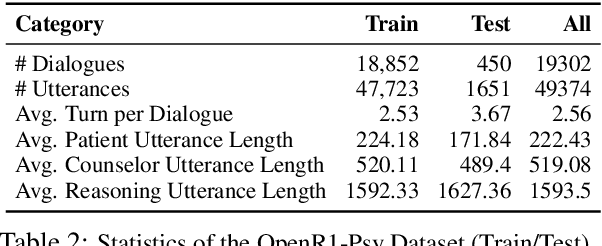
Large language models (LLMs) hold significant potential for mental health support, capable of generating empathetic responses and simulating therapeutic conversations. However, existing LLM-based approaches often lack the clinical grounding necessary for real-world psychological counseling, particularly in explicit diagnostic reasoning aligned with standards like the DSM/ICD and incorporating diverse therapeutic modalities beyond basic empathy or single strategies. To address these critical limitations, we propose PsyLLM, the first large language model designed to systematically integrate both diagnostic and therapeutic reasoning for mental health counseling. To develop the PsyLLM, we propose a novel automated data synthesis pipeline. This pipeline processes real-world mental health posts, generates multi-turn dialogue structures, and leverages LLMs guided by international diagnostic standards (e.g., DSM/ICD) and multiple therapeutic frameworks (e.g., CBT, ACT, psychodynamic) to simulate detailed clinical reasoning processes. Rigorous multi-dimensional filtering ensures the generation of high-quality, clinically aligned dialogue data. In addition, we introduce a new benchmark and evaluation protocol, assessing counseling quality across four key dimensions: comprehensiveness, professionalism, authenticity, and safety. Our experiments demonstrate that PsyLLM significantly outperforms state-of-the-art baseline models on this benchmark.
EmoBench-M: Benchmarking Emotional Intelligence for Multimodal Large Language Models
Feb 06, 2025



With the integration of Multimodal large language models (MLLMs) into robotic systems and various AI applications, embedding emotional intelligence (EI) capabilities into these models is essential for enabling robots to effectively address human emotional needs and interact seamlessly in real-world scenarios. Existing static, text-based, or text-image benchmarks overlook the multimodal complexities of real-world interactions and fail to capture the dynamic, multimodal nature of emotional expressions, making them inadequate for evaluating MLLMs' EI. Based on established psychological theories of EI, we build EmoBench-M, a novel benchmark designed to evaluate the EI capability of MLLMs across 13 valuation scenarios from three key dimensions: foundational emotion recognition, conversational emotion understanding, and socially complex emotion analysis. Evaluations of both open-source and closed-source MLLMs on EmoBench-M reveal a significant performance gap between them and humans, highlighting the need to further advance their EI capabilities. All benchmark resources, including code and datasets, are publicly available at https://emo-gml.github.io/.
MemoryMamba: Memory-Augmented State Space Model for Defect Recognition
May 06, 2024



As automation advances in manufacturing, the demand for precise and sophisticated defect detection technologies grows. Existing vision models for defect recognition methods are insufficient for handling the complexities and variations of defects in contemporary manufacturing settings. These models especially struggle in scenarios involving limited or imbalanced defect data. In this work, we introduce MemoryMamba, a novel memory-augmented state space model (SSM), designed to overcome the limitations of existing defect recognition models. MemoryMamba integrates the state space model with the memory augmentation mechanism, enabling the system to maintain and retrieve essential defect-specific information in training. Its architecture is designed to capture dependencies and intricate defect characteristics, which are crucial for effective defect detection. In the experiments, MemoryMamba was evaluated across four industrial datasets with diverse defect types and complexities. The model consistently outperformed other methods, demonstrating its capability to adapt to various defect recognition scenarios.
InsectMamba: Insect Pest Classification with State Space Model
Apr 04, 2024



The classification of insect pests is a critical task in agricultural technology, vital for ensuring food security and environmental sustainability. However, the complexity of pest identification, due to factors like high camouflage and species diversity, poses significant obstacles. Existing methods struggle with the fine-grained feature extraction needed to distinguish between closely related pest species. Although recent advancements have utilized modified network structures and combined deep learning approaches to improve accuracy, challenges persist due to the similarity between pests and their surroundings. To address this problem, we introduce InsectMamba, a novel approach that integrates State Space Models (SSMs), Convolutional Neural Networks (CNNs), Multi-Head Self-Attention mechanism (MSA), and Multilayer Perceptrons (MLPs) within Mix-SSM blocks. This integration facilitates the extraction of comprehensive visual features by leveraging the strengths of each encoding strategy. A selective module is also proposed to adaptively aggregate these features, enhancing the model's ability to discern pest characteristics. InsectMamba was evaluated against strong competitors across five insect pest classification datasets. The results demonstrate its superior performance and verify the significance of each model component by an ablation study.
Visual In-Context Learning for Large Vision-Language Models
Feb 18, 2024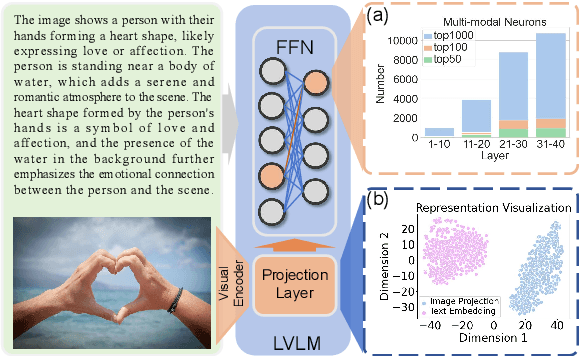



In Large Visual Language Models (LVLMs), the efficacy of In-Context Learning (ICL) remains limited by challenges in cross-modal interactions and representation disparities. To overcome these challenges, we introduce a novel Visual In-Context Learning (VICL) method comprising Visual Demonstration Retrieval, Intent-Oriented Image Summarization, and Intent-Oriented Demonstration Composition. Our approach retrieves images via ''Retrieval & Rerank'' paradigm, summarises images with task intent and task-specific visual parsing, and composes language-based demonstrations that reduce token count and alleviate cross-modal interaction problem. Experimental evaluations on five visual reasoning datasets demonstrate the effectiveness of our method. Moreover, our extensive experiments leverage information flow analysis to elucidate the effectiveness of our method, and investigate the impact of length and position of demonstrations for LVLM. The use of in-context unlearning further shows promise in resetting specific model knowledge without retraining.