 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes Unification Come at a Cost? Uni-SafeBench: A Safety Benchmark for Unified Multimodal Large Models
Apr 01, 2026Unified Multimodal Large Models (UMLMs) integrate understanding and generation capabilities within a single architecture. While this architectural unification, driven by the deep fusion of multimodal features, enhances model performance, it also introduces important yet underexplored safety challenges. Existing safety benchmarks predominantly focus on isolated understanding or generation tasks, failing to evaluate the holistic safety of UMLMs when handling diverse tasks under a unified framework. To address this, we introduce Uni-SafeBench, a comprehensive benchmark featuring a taxonomy of six major safety categories across seven task types. To ensure rigorous assessment, we develop Uni-Judger, a framework that effectively decouples contextual safety from intrinsic safety. Based on comprehensive evaluations across Uni-SafeBench, we uncover that while the unification process enhances model capabilities, it significantly degrades the inherent safety of the underlying LLM. Furthermore, open-source UMLMs exhibit much lower safety performance than multimodal large models specialized for either generation or understanding tasks. We open-source all resources to systematically expose these risks and foster safer AGI development.
Backdoor Sentinel: Detecting and Detoxifying Backdoors in Diffusion Models via Temporal Noise Consistency
Feb 02, 2026Diffusion models have been widely deployed in AIGC services; however, their reliance on opaque training data and procedures exposes a broad attack surface for backdoor injection. In practical auditing scenarios, due to the protection of intellectual property and commercial confidentiality, auditors are typically unable to access model parameters, rendering existing white-box or query-intensive detection methods impractical. More importantly, even after the backdoor is detected, existing detoxification approaches are often trapped in a dilemma between detoxification effectiveness and generation quality. In this work, we identify a previously unreported phenomenon called temporal noise unconsistency, where the noise predictions between adjacent diffusion timesteps is disrupted in specific temporal segments when the input is triggered, while remaining stable under clean inputs. Leveraging this finding, we propose Temporal Noise Consistency Defense (TNC-Defense), a unified framework for backdoor detection and detoxification. The framework first uses the adjacent timestep noise consistency to design a gray-box detection module, for identifying and locating anomalous diffusion timesteps. Furthermore, the framework uses the identified anomalous timesteps to construct a trigger-agnostic, timestep-aware detoxification module, which directly corrects the backdoor generation path. This effectively suppresses backdoor behavior while significantly reducing detoxification costs. We evaluate the proposed method under five representative backdoor attack scenarios and compare it with state-of-the-art defenses. The results show that TNC-Defense improves the average detection accuracy by $11\%$ with negligible additional overhead, and invalidates an average of $98.5\%$ of triggered samples with only a mild degradation in generation quality.
REMOTE: A Unified Multimodal Relation Extraction Framework with Multilevel Optimal Transport and Mixture-of-Experts
Sep 05, 2025
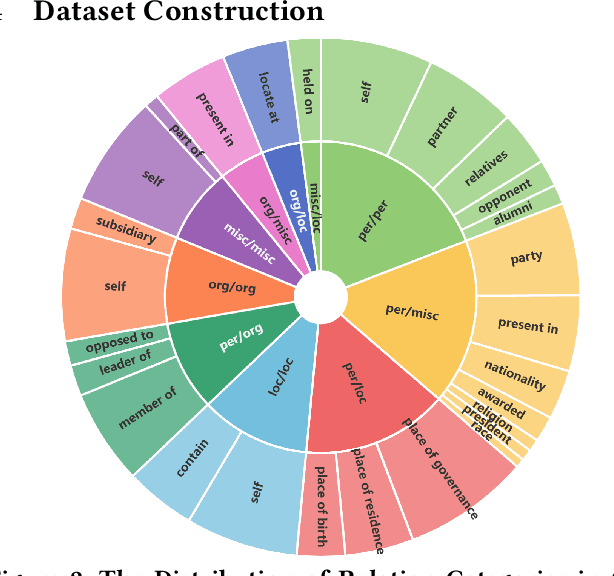
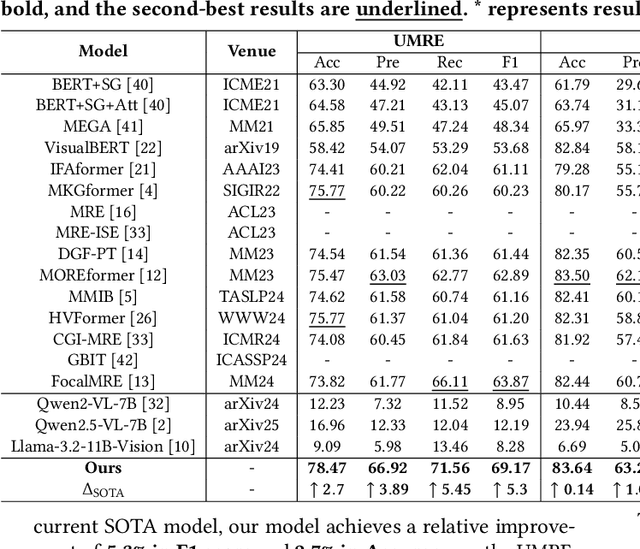
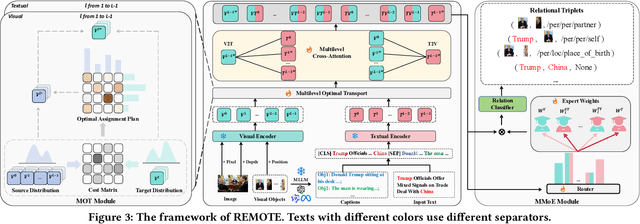
Multimodal relation extraction (MRE) is a crucial task in the fields of Knowledge Graph and Multimedia, playing a pivotal role in multimodal knowledge graph construction. However, existing methods are typically limited to extracting a single type of relational triplet, which restricts their ability to extract triplets beyond the specified types. Directly combining these methods fails to capture dynamic cross-modal interactions and introduces significant computational redundancy. Therefore, we propose a novel \textit{unified multimodal Relation Extraction framework with Multilevel Optimal Transport and mixture-of-Experts}, termed REMOTE, which can simultaneously extract intra-modal and inter-modal relations between textual entities and visual objects. To dynamically select optimal interaction features for different types of relational triplets, we introduce mixture-of-experts mechanism, ensuring the most relevant modality information is utilized. Additionally, considering that the inherent property of multilayer sequential encoding in existing encoders often leads to the loss of low-level information, we adopt a multilevel optimal transport fusion module to preserve low-level features while maintaining multilayer encoding, yielding more expressive representations. Correspondingly, we also create a Unified Multimodal Relation Extraction (UMRE) dataset to evaluate the effectiveness of our framework, encompassing diverse cases where the head and tail entities can originate from either text or image. Extensive experiments show that REMOTE effectively extracts various types of relational triplets and achieves state-of-the-art performanc on almost all metrics across two other public MRE datasets. We release our resources at https://github.com/Nikol-coder/REMOTE.
Joint Beamforming Optimization for Pinching-Antenna Systems (PASS)-assisted Symbiotic Radio
Aug 09, 2025This paper investigates a novel downlink symbiotic radio (SR) framework empowered by the pinching antenna system (PASS), aiming to enhance both primary and secondary transmissions through reconfigurable antenna positioning. PASS consists of multiple waveguides equipped with numerous low-cost pinching antennas (PAs), whose positions can be flexibly adjusted to simultaneously manipulate large-scale path loss and signal phases.We formulate a joint transmit and pinching beamforming optimization problem to maximize the achievable sum rate while satisfying the detection error probability constraint for the IR and the feasible deployment region constraints for the PAs. This problem is inherently nonconvex and highly coupled. To address it, two solution strategies are developed. 1) A learning-aided gradient descent (LGD) algorithm is proposed, where the constrained problem is reformulated into a differentiable form and solved through end-to-end learning based on the principle of gradient descent. The PA position matrix is reparameterized to inherently satisfy minimum spacing constraints, while transmit power and waveguide length limits are enforced via projection and normalization. 2) A two-stage optimization-based approach is designed, in which the transmit beamforming is first optimized via successive convex approximation (SCA), followed by pinching beamforming optimization using a particle swarm optimization (PSO) search over candidate PA placements. The SCA-PSO algorithm achieves performance close to that of the element-wise method while significantly reducing computational complexity by exploring a randomly generated effective solution subspace, while further improving upon the LGD method by avoiding undesirable local optima.
EmoBench-M: Benchmarking Emotional Intelligence for Multimodal Large Language Models
Feb 06, 2025



With the integration of Multimodal large language models (MLLMs) into robotic systems and various AI applications, embedding emotional intelligence (EI) capabilities into these models is essential for enabling robots to effectively address human emotional needs and interact seamlessly in real-world scenarios. Existing static, text-based, or text-image benchmarks overlook the multimodal complexities of real-world interactions and fail to capture the dynamic, multimodal nature of emotional expressions, making them inadequate for evaluating MLLMs' EI. Based on established psychological theories of EI, we build EmoBench-M, a novel benchmark designed to evaluate the EI capability of MLLMs across 13 valuation scenarios from three key dimensions: foundational emotion recognition, conversational emotion understanding, and socially complex emotion analysis. Evaluations of both open-source and closed-source MLLMs on EmoBench-M reveal a significant performance gap between them and humans, highlighting the need to further advance their EI capabilities. All benchmark resources, including code and datasets, are publicly available at https://emo-gml.github.io/.
Ensemble Predicate Decoding for Unbiased Scene Graph Generation
Aug 26, 2024Scene Graph Generation (SGG) aims to generate a comprehensive graphical representation that accurately captures the semantic information of a given scenario. However, the SGG model's performance in predicting more fine-grained predicates is hindered by a significant predicate bias. According to existing works, the long-tail distribution of predicates in training data results in the biased scene graph. However, the semantic overlap between predicate categories makes predicate prediction difficult, and there is a significant difference in the sample size of semantically similar predicates, making the predicate prediction more difficult. Therefore, higher requirements are placed on the discriminative ability of the model. In order to address this problem, this paper proposes Ensemble Predicate Decoding (EPD), which employs multiple decoders to attain unbiased scene graph generation. Two auxiliary decoders trained on lower-frequency predicates are used to improve the discriminative ability of the model. Extensive experiments are conducted on the VG, and the experiment results show that EPD enhances the model's representation capability for predicates. In addition, we find that our approach ensures a relatively superior predictive capability for more frequent predicates compared to previous unbiased SGG methods.
IBMEA: Exploring Variational Information Bottleneck for Multi-modal Entity Alignment
Jul 27, 2024



Multi-modal entity alignment (MMEA) aims to identify equivalent entities between multi-modal knowledge graphs (MMKGs), where the entities can be associated with related images. Most existing studies integrate multi-modal information heavily relying on the automatically-learned fusion module, rarely suppressing the redundant information for MMEA explicitly. To this end, we explore variational information bottleneck for multi-modal entity alignment (IBMEA), which emphasizes the alignment-relevant information and suppresses the alignment-irrelevant information in generating entity representations. Specifically, we devise multi-modal variational encoders to generate modal-specific entity representations as probability distributions. Then, we propose four modal-specific information bottleneck regularizers, limiting the misleading clues in refining modal-specific entity representations. Finally, we propose a modal-hybrid information contrastive regularizer to integrate all the refined modal-specific representations, enhancing the entity similarity between MMKGs to achieve MMEA. We conduct extensive experiments on two cross-KG and three bilingual MMEA datasets. Experimental results demonstrate that our model consistently outperforms previous state-of-the-art methods, and also shows promising and robust performance in low-resource and high-noise data scenarios.
MMIDR: Teaching Large Language Model to Interpret Multimodal Misinformation via Knowledge Distillation
Mar 21, 2024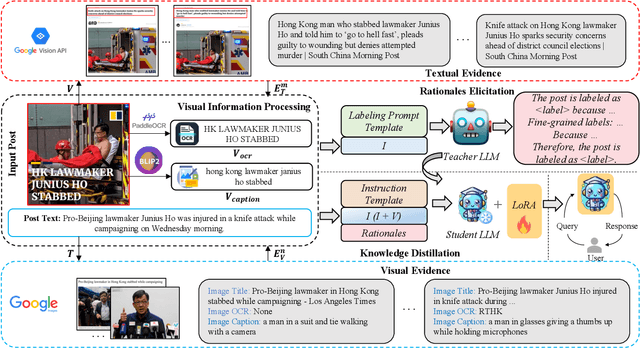



Automatic detection of multimodal misinformation has gained a widespread attention recently. However, the potential of powerful Large Language Models (LLMs) for multimodal misinformation detection remains underexplored. Besides, how to teach LLMs to interpret multimodal misinformation in cost-effective and accessible way is still an open question. To address that, we propose MMIDR, a framework designed to teach LLMs in providing fluent and high-quality textual explanations for their decision-making process of multimodal misinformation. To convert multimodal misinformation into an appropriate instruction-following format, we present a data augmentation perspective and pipeline. This pipeline consists of a visual information processing module and an evidence retrieval module. Subsequently, we prompt the proprietary LLMs with processed contents to extract rationales for interpreting the authenticity of multimodal misinformation. Furthermore, we design an efficient knowledge distillation approach to distill the capability of proprietary LLMs in explaining multimodal misinformation into open-source LLMs. To explore several research questions regarding the performance of LLMs in multimodal misinformation detection tasks, we construct an instruction-following multimodal misinformation dataset and conduct comprehensive experiments. The experimental findings reveal that our MMIDR exhibits sufficient detection performance and possesses the capacity to provide compelling rationales to support its assessments.
Learning to Correct Noisy Labels for Fine-Grained Entity Typing via Co-Prediction Prompt Tuning
Oct 23, 2023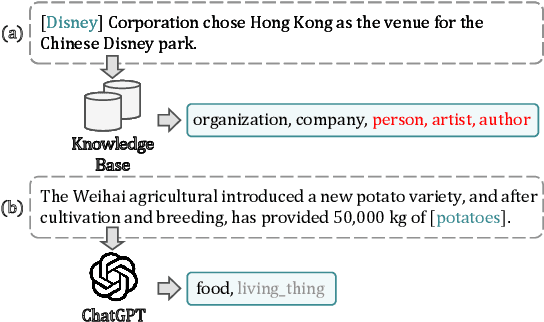
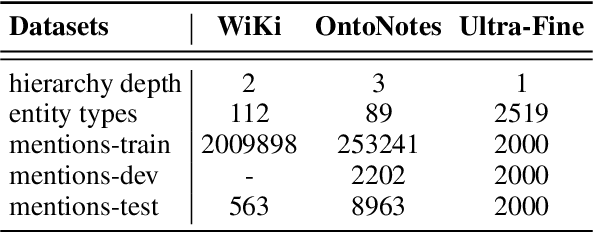
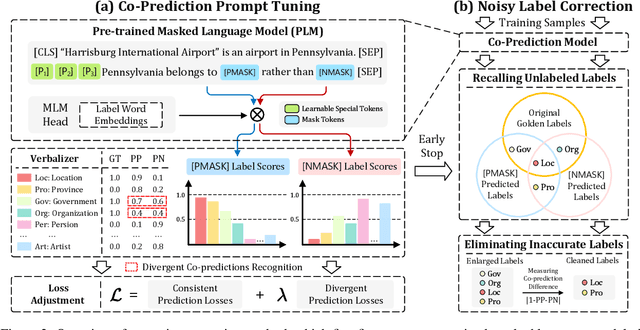
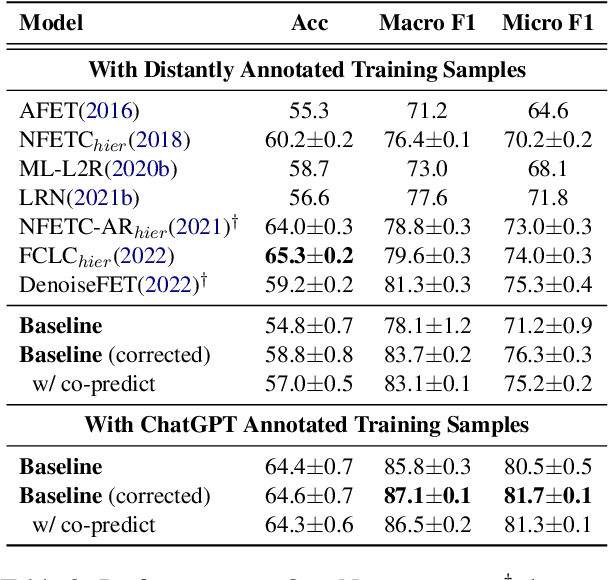
Fine-grained entity typing (FET) is an essential task in natural language processing that aims to assign semantic types to entities in text. However, FET poses a major challenge known as the noise labeling problem, whereby current methods rely on estimating noise distribution to identify noisy labels but are confused by diverse noise distribution deviation. To address this limitation, we introduce Co-Prediction Prompt Tuning for noise correction in FET, which leverages multiple prediction results to identify and correct noisy labels. Specifically, we integrate prediction results to recall labeled labels and utilize a differentiated margin to identify inaccurate labels. Moreover, we design an optimization objective concerning divergent co-predictions during fine-tuning, ensuring that the model captures sufficient information and maintains robustness in noise identification. Experimental results on three widely-used FET datasets demonstrate that our noise correction approach significantly enhances the quality of various types of training samples, including those annotated using distant supervision, ChatGPT, and crowdsourcing.
A Boundary Offset Prediction Network for Named Entity Recognition
Oct 23, 2023Named entity recognition (NER) is a fundamental task in natural language processing that aims to identify and classify named entities in text. However, span-based methods for NER typically assign entity types to text spans, resulting in an imbalanced sample space and neglecting the connections between non-entity and entity spans. To address these issues, we propose a novel approach for NER, named the Boundary Offset Prediction Network (BOPN), which predicts the boundary offsets between candidate spans and their nearest entity spans. By leveraging the guiding semantics of boundary offsets, BOPN establishes connections between non-entity and entity spans, enabling non-entity spans to function as additional positive samples for entity detection. Furthermore, our method integrates entity type and span representations to generate type-aware boundary offsets instead of using entity types as detection targets. We conduct experiments on eight widely-used NER datasets, and the results demonstrate that our proposed BOPN outperforms previous state-of-the-art methods.