 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS2CDR: Smoothing-Sharpening Process Model for Cross-Domain Recommendation
Mar 03, 2026User cold-start problem is a long-standing challenge in recommendation systems. Fortunately, cross-domain recommendation (CDR) has emerged as a highly effective remedy for the user cold-start challenge, with recently developed diffusion models (DMs) demonstrating exceptional performance. However, these DMs-based CDR methods focus on dealing with user-item interactions, overlooking correlations between items across the source and target domains. Meanwhile, the Gaussian noise added in the forward process of diffusion models would hurt user's personalized preference, leading to the difficulty in transferring user preference across domains. To this end, we propose a novel paradigm of Smoothing-Sharpening Process Model for CDR to cold-start users, termed as S2CDR which features a corruption-recovery architecture and is solved with respect to ordinary differential equations (ODEs). Specifically, the smoothing process gradually corrupts the original user-item/item-item interaction matrices derived from both domains into smoothed preference signals in a noise-free manner, and the sharpening process iteratively sharpens the preference signals to recover the unknown interactions for cold-start users. Wherein, for the smoothing process, we introduce the heat equation on the item-item similarity graph to better capture the correlations between items across domains, and further build the tailor-designed low-pass filter to filter out the high-frequency noise information for capturing user's intrinsic preference, in accordance with the graph signal processing (GSP) theory. Extensive experiments on three real-world CDR scenarios confirm that our S2CDR significantly outperforms previous SOTA methods in a training-free manner.
Hyperbolic-PDE GNN: Spectral Graph Neural Networks in the Perspective of A System of Hyperbolic Partial Differential Equations
May 29, 2025Graph neural networks (GNNs) leverage message passing mechanisms to learn the topological features of graph data. Traditional GNNs learns node features in a spatial domain unrelated to the topology, which can hardly ensure topological features. In this paper, we formulates message passing as a system of hyperbolic partial differential equations (hyperbolic PDEs), constituting a dynamical system that explicitly maps node representations into a particular solution space. This solution space is spanned by a set of eigenvectors describing the topological structure of graphs. Within this system, for any moment in time, a node features can be decomposed into a superposition of the basis of eigenvectors. This not only enhances the interpretability of message passing but also enables the explicit extraction of fundamental characteristics about the topological structure. Furthermore, by solving this system of hyperbolic partial differential equations, we establish a connection with spectral graph neural networks (spectral GNNs), serving as a message passing enhancement paradigm for spectral GNNs.We further introduce polynomials to approximate arbitrary filter functions. Extensive experiments demonstrate that the paradigm of hyperbolic PDEs not only exhibits strong flexibility but also significantly enhances the performance of various spectral GNNs across diverse graph tasks.
* 18 pages, 2 figures, published to ICML 2025
Mitigating Modality Bias in Multi-modal Entity Alignment from a Causal Perspective
Apr 29, 2025



Multi-Modal Entity Alignment (MMEA) aims to retrieve equivalent entities from different Multi-Modal Knowledge Graphs (MMKGs), a critical information retrieval task. Existing studies have explored various fusion paradigms and consistency constraints to improve the alignment of equivalent entities, while overlooking that the visual modality may not always contribute positively. Empirically, entities with low-similarity images usually generate unsatisfactory performance, highlighting the limitation of overly relying on visual features. We believe the model can be biased toward the visual modality, leading to a shortcut image-matching task. To address this, we propose a counterfactual debiasing framework for MMEA, termed CDMEA, which investigates visual modality bias from a causal perspective. Our approach aims to leverage both visual and graph modalities to enhance MMEA while suppressing the direct causal effect of the visual modality on model predictions. By estimating the Total Effect (TE) of both modalities and excluding the Natural Direct Effect (NDE) of the visual modality, we ensure that the model predicts based on the Total Indirect Effect (TIE), effectively utilizing both modalities and reducing visual modality bias. Extensive experiments on 9 benchmark datasets show that CDMEA outperforms 14 state-of-the-art methods, especially in low-similarity, high-noise, and low-resource data scenarios.
LoginMEA: Local-to-Global Interaction Network for Multi-modal Entity Alignment
Jul 29, 2024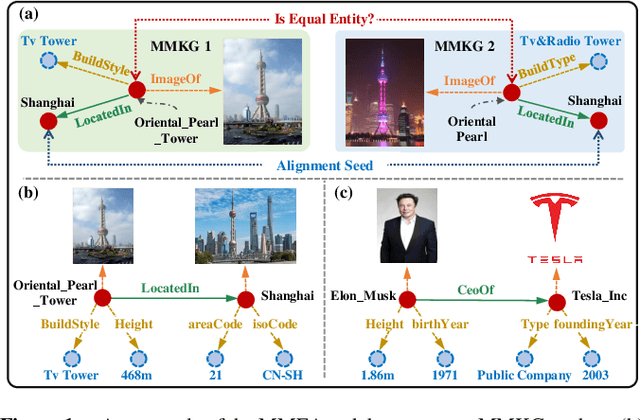
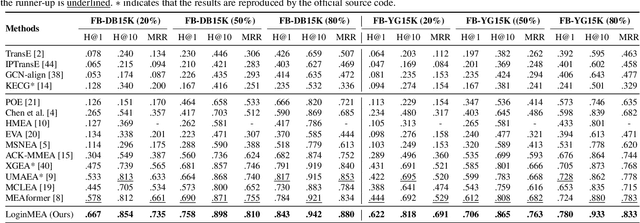
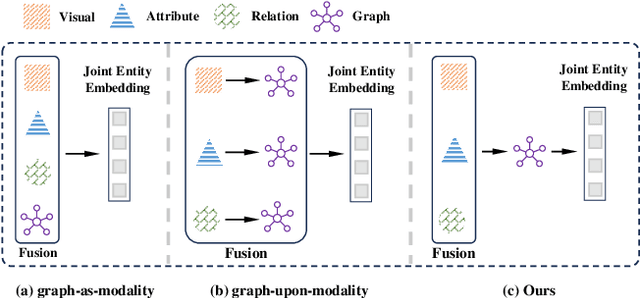
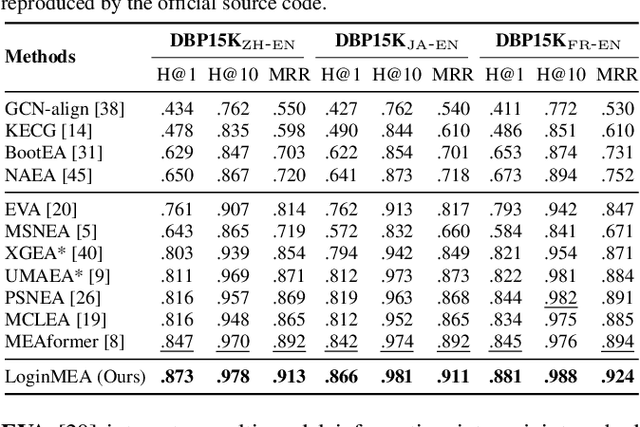
Multi-modal entity alignment (MMEA) aims to identify equivalent entities between two multi-modal knowledge graphs (MMKGs), whose entities can be associated with relational triples and related images. Most previous studies treat the graph structure as a special modality, and fuse different modality information with separate uni-modal encoders, neglecting valuable relational associations in modalities. Other studies refine each uni-modal information with graph structures, but may introduce unnecessary relations in specific modalities. To this end, we propose a novel local-to-global interaction network for MMEA, termed as LoginMEA. Particularly, we first fuse local multi-modal interactions to generate holistic entity semantics and then refine them with global relational interactions of entity neighbors. In this design, the uni-modal information is fused adaptively, and can be refined with relations accordingly. To enrich local interactions of multi-modal entity information, we device modality weights and low-rank interactive fusion, allowing diverse impacts and element-level interactions among modalities. To capture global interactions of graph structures, we adopt relation reflection graph attention networks, which fully capture relational associations between entities. Extensive experiments demonstrate superior results of our method over 5 cross-KG or bilingual benchmark datasets, indicating the effectiveness of capturing local and global interactions.
IBMEA: Exploring Variational Information Bottleneck for Multi-modal Entity Alignment
Jul 27, 2024



Multi-modal entity alignment (MMEA) aims to identify equivalent entities between multi-modal knowledge graphs (MMKGs), where the entities can be associated with related images. Most existing studies integrate multi-modal information heavily relying on the automatically-learned fusion module, rarely suppressing the redundant information for MMEA explicitly. To this end, we explore variational information bottleneck for multi-modal entity alignment (IBMEA), which emphasizes the alignment-relevant information and suppresses the alignment-irrelevant information in generating entity representations. Specifically, we devise multi-modal variational encoders to generate modal-specific entity representations as probability distributions. Then, we propose four modal-specific information bottleneck regularizers, limiting the misleading clues in refining modal-specific entity representations. Finally, we propose a modal-hybrid information contrastive regularizer to integrate all the refined modal-specific representations, enhancing the entity similarity between MMKGs to achieve MMEA. We conduct extensive experiments on two cross-KG and three bilingual MMEA datasets. Experimental results demonstrate that our model consistently outperforms previous state-of-the-art methods, and also shows promising and robust performance in low-resource and high-noise data scenarios.