 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoginMEA: Local-to-Global Interaction Network for Multi-modal Entity Alignment
Paper and Code
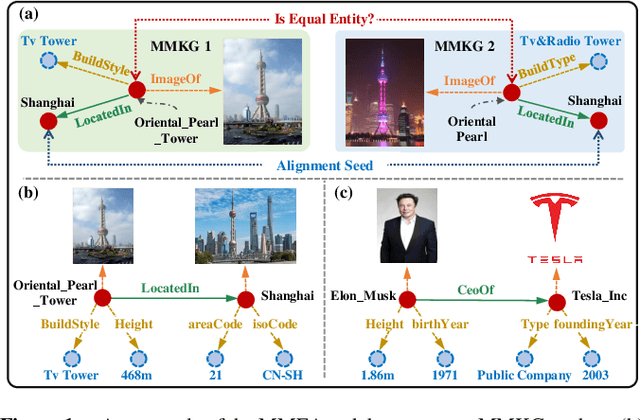
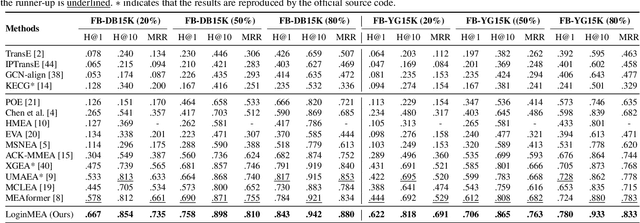
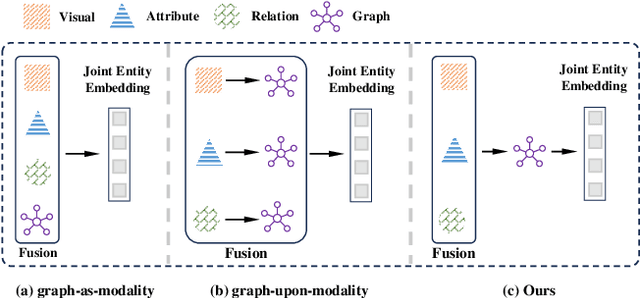
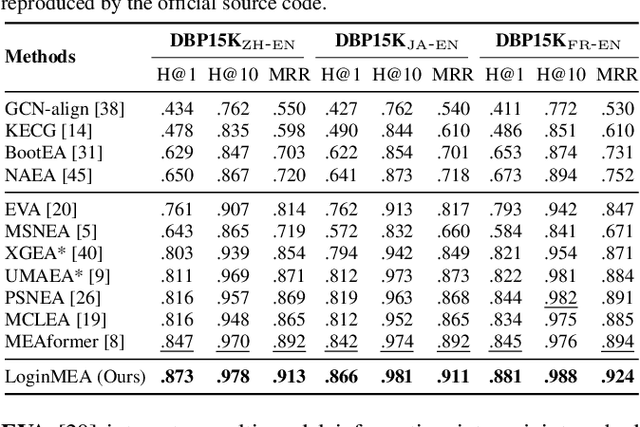
Multi-modal entity alignment (MMEA) aims to identify equivalent entities between two multi-modal knowledge graphs (MMKGs), whose entities can be associated with relational triples and related images. Most previous studies treat the graph structure as a special modality, and fuse different modality information with separate uni-modal encoders, neglecting valuable relational associations in modalities. Other studies refine each uni-modal information with graph structures, but may introduce unnecessary relations in specific modalities. To this end, we propose a novel local-to-global interaction network for MMEA, termed as LoginMEA. Particularly, we first fuse local multi-modal interactions to generate holistic entity semantics and then refine them with global relational interactions of entity neighbors. In this design, the uni-modal information is fused adaptively, and can be refined with relations accordingly. To enrich local interactions of multi-modal entity information, we device modality weights and low-rank interactive fusion, allowing diverse impacts and element-level interactions among modalities. To capture global interactions of graph structures, we adopt relation reflection graph attention networks, which fully capture relational associations between entities. Extensive experiments demonstrate superior results of our method over 5 cross-KG or bilingual benchmark datasets, indicating the effectiveness of capturing local and global interactions.