 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevealing the Challenge of Detecting Character Knowledge Errors in LLM Role-Playing
Sep 18, 2024



Large language model (LLM) role-playing has gained widespread attention, where the authentic character knowledge is crucial for constructing realistic LLM role-playing agents. However, existing works usually overlook the exploration of LLMs' ability to detect characters' known knowledge errors (KKE) and unknown knowledge errors (UKE) while playing roles, which would lead to low-quality automatic construction of character trainable corpus. In this paper, we propose a probing dataset to evaluate LLMs' ability to detect errors in KKE and UKE. The results indicate that even the latest LLMs struggle to effectively detect these two types of errors, especially when it comes to familiar knowledge. We experimented with various reasoning strategies and propose an agent-based reasoning method, Self-Recollection and Self-Doubt (S2RD), to further explore the potential for improving error detection capabilities. Experiments show that our method effectively improves the LLMs' ability to detect error character knowledge, but it remains an issue that requires ongoing attention.
Don't Half-listen: Capturing Key-part Information in Continual Instruction Tuning
Mar 15, 2024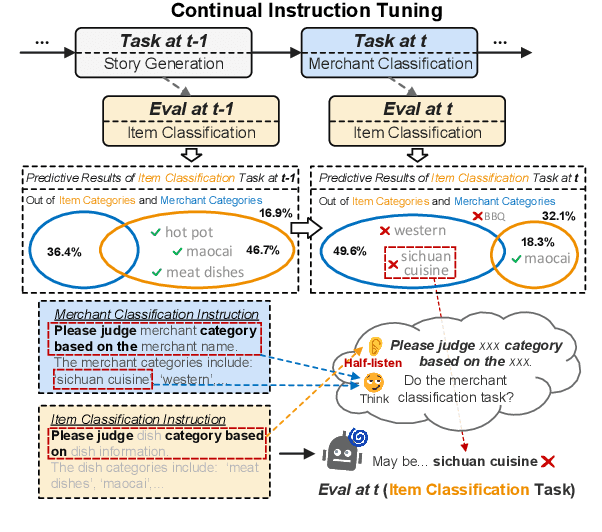



Instruction tuning for large language models (LLMs) can drive them to produce results consistent with human goals in specific downstream tasks. However, the process of continual instruction tuning (CIT) for LLMs may bring about the catastrophic forgetting (CF) problem, where previously learned abilities are degraded. Recent methods try to alleviate the CF problem by modifying models or replaying data, which may only remember the surface-level pattern of instructions and get confused on held-out tasks. In this paper, we propose a novel continual instruction tuning method based on Key-part Information Gain (KPIG). Our method computes the information gain on masked parts to dynamically replay data and refine the training objective, which enables LLMs to capture task-aware information relevant to the correct response and alleviate overfitting to general descriptions in instructions. In addition, we propose two metrics, P-score and V-score, to measure the generalization and instruction-following abilities of LLMs. Experiments demonstrate our method achieves superior performance on both seen and held-out tasks.
Two-stage Generative Question Answering on Temporal Knowledge Graph Using Large Language Models
Feb 26, 2024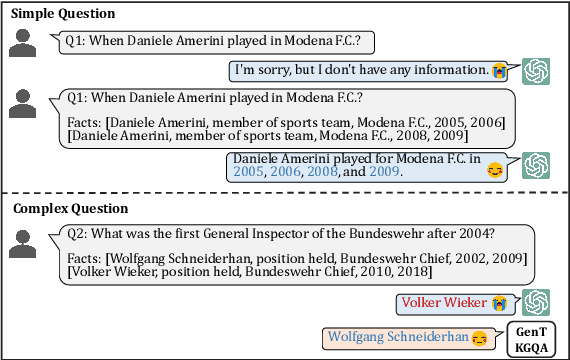
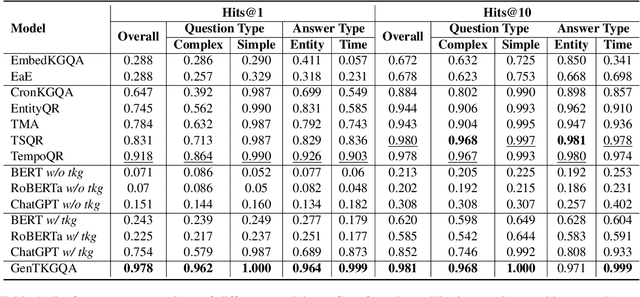
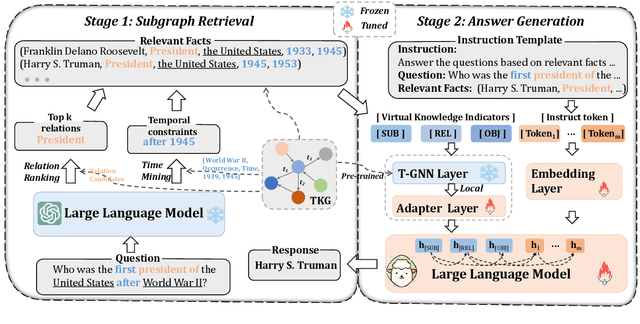
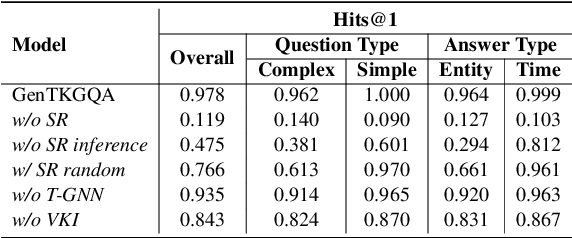
Temporal knowledge graph question answering (TKGQA) poses a significant challenge task, due to the temporal constraints hidden in questions and the answers sought from dynamic structured knowledge. Although large language models (LLMs) have made considerable progress in their reasoning ability over structured data, their application to the TKGQA task is a relatively unexplored area. This paper first proposes a novel generative temporal knowledge graph question answering framework, GenTKGQA, which guides LLMs to answer temporal questions through two phases: Subgraph Retrieval and Answer Generation. First, we exploit LLM's intrinsic knowledge to mine temporal constraints and structural links in the questions without extra training, thus narrowing down the subgraph search space in both temporal and structural dimensions. Next, we design virtual knowledge indicators to fuse the graph neural network signals of the subgraph and the text representations of the LLM in a non-shallow way, which helps the open-source LLM deeply understand the temporal order and structural dependencies among the retrieved facts through instruction tuning. Experimental results demonstrate that our model outperforms state-of-the-art baselines, even achieving 100\% on the metrics for the simple question type.
VN Network: Embedding Newly Emerging Entities with Virtual Neighbors
Feb 21, 2024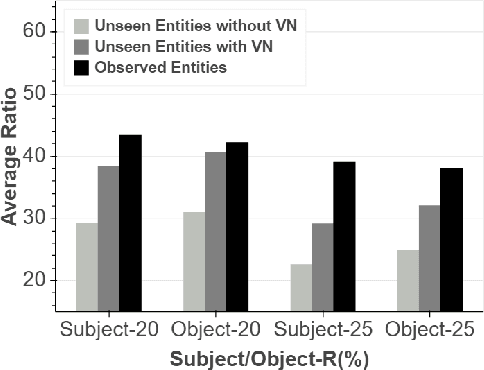



Embedding entities and relations into continuous vector spaces has attracted a surge of interest in recent years. Most embedding methods assume that all test entities are available during training, which makes it time-consuming to retrain embeddings for newly emerging entities. To address this issue, recent works apply the graph neural network on the existing neighbors of the unseen entities. In this paper, we propose a novel framework, namely Virtual Neighbor (VN) network, to address three key challenges. Firstly, to reduce the neighbor sparsity problem, we introduce the concept of the virtual neighbors inferred by rules. And we assign soft labels to these neighbors by solving a rule-constrained problem, rather than simply regarding them as unquestionably true. Secondly, many existing methods only use one-hop or two-hop neighbors for aggregation and ignore the distant information that may be helpful. Instead, we identify both logic and symmetric path rules to capture complex patterns. Finally, instead of one-time injection of rules, we employ an iterative learning scheme between the embedding method and virtual neighbor prediction to capture the interactions within. Experimental results on two knowledge graph completion tasks demonstrate that our VN network significantly outperforms state-of-the-art baselines. Furthermore, results on Subject/Object-R show that our proposed VN network is highly robust to the neighbor sparsity problem.
* 10 pages, 5 figures
HIP Network: Historical Information Passing Network for Extrapolation Reasoning on Temporal Knowledge Graph
Feb 19, 2024In recent years, temporal knowledge graph (TKG) reasoning has received significant attention. Most existing methods assume that all timestamps and corresponding graphs are available during training, which makes it difficult to predict future events. To address this issue, recent works learn to infer future events based on historical information. However, these methods do not comprehensively consider the latent patterns behind temporal changes, to pass historical information selectively, update representations appropriately and predict events accurately. In this paper, we propose the Historical Information Passing (HIP) network to predict future events. HIP network passes information from temporal, structural and repetitive perspectives, which are used to model the temporal evolution of events, the interactions of events at the same time step, and the known events respectively. In particular, our method considers the updating of relation representations and adopts three scoring functions corresponding to the above dimensions. Experimental results on five benchmark datasets show the superiority of HIP network, and the significant improvements on Hits@1 prove that our method can more accurately predict what is going to happen.
* 7 pages, 3 figures
A Boundary Offset Prediction Network for Named Entity Recognition
Oct 23, 2023Named entity recognition (NER) is a fundamental task in natural language processing that aims to identify and classify named entities in text. However, span-based methods for NER typically assign entity types to text spans, resulting in an imbalanced sample space and neglecting the connections between non-entity and entity spans. To address these issues, we propose a novel approach for NER, named the Boundary Offset Prediction Network (BOPN), which predicts the boundary offsets between candidate spans and their nearest entity spans. By leveraging the guiding semantics of boundary offsets, BOPN establishes connections between non-entity and entity spans, enabling non-entity spans to function as additional positive samples for entity detection. Furthermore, our method integrates entity type and span representations to generate type-aware boundary offsets instead of using entity types as detection targets. We conduct experiments on eight widely-used NER datasets, and the results demonstrate that our proposed BOPN outperforms previous state-of-the-art methods.
Learning to Correct Noisy Labels for Fine-Grained Entity Typing via Co-Prediction Prompt Tuning
Oct 23, 2023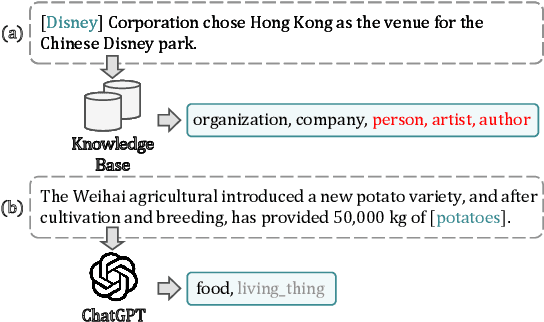
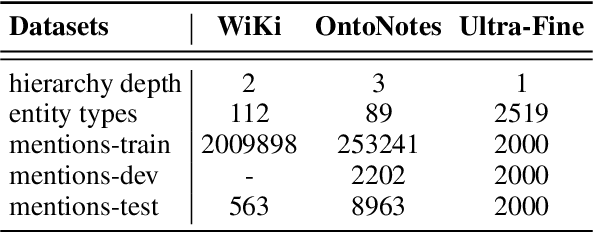
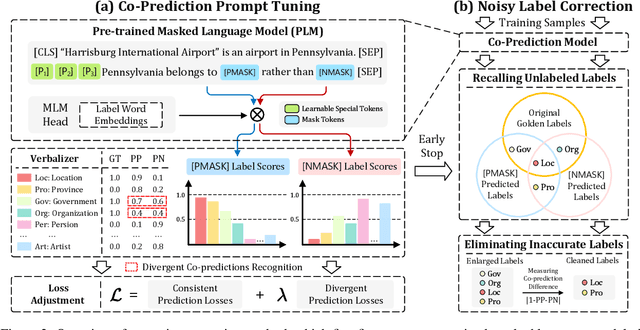
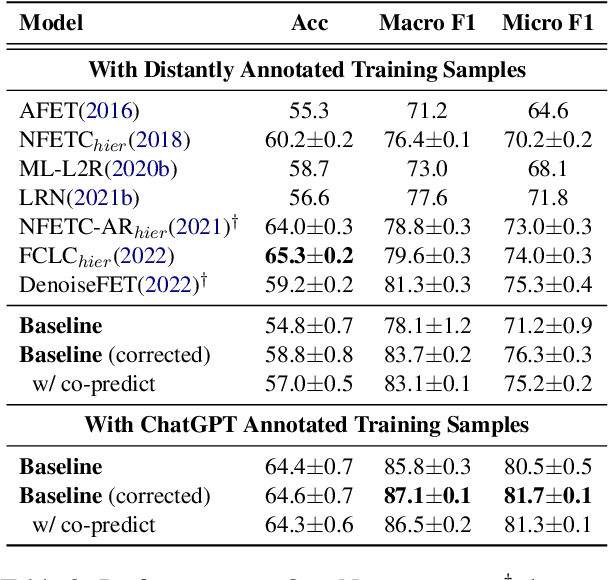
Fine-grained entity typing (FET) is an essential task in natural language processing that aims to assign semantic types to entities in text. However, FET poses a major challenge known as the noise labeling problem, whereby current methods rely on estimating noise distribution to identify noisy labels but are confused by diverse noise distribution deviation. To address this limitation, we introduce Co-Prediction Prompt Tuning for noise correction in FET, which leverages multiple prediction results to identify and correct noisy labels. Specifically, we integrate prediction results to recall labeled labels and utilize a differentiated margin to identify inaccurate labels. Moreover, we design an optimization objective concerning divergent co-predictions during fine-tuning, ensuring that the model captures sufficient information and maintains robustness in noise identification. Experimental results on three widely-used FET datasets demonstrate that our noise correction approach significantly enhances the quality of various types of training samples, including those annotated using distant supervision, ChatGPT, and crowdsourcing.
Iteratively Learning Representations for Unseen Entities with Inter-Rule Correlations
May 17, 2023Recent work on knowledge graph completion (KGC) focused on learning embeddings of entities and relations in knowledge graphs. These embedding methods require that all test entities are observed at training time, resulting in a time-consuming retraining process for out-of-knowledge-graph (OOKG) entities. To address this issue, current inductive knowledge embedding methods employ graph neural networks (GNNs) to represent unseen entities by aggregating information of known neighbors. They face three important challenges: (i) data sparsity, (ii) the presence of complex patterns in knowledge graphs (e.g., inter-rule correlations), and (iii) the presence of interactions among rule mining, rule inference, and embedding. In this paper, we propose a virtual neighbor network with inter-rule correlations (VNC) that consists of three stages: (i) rule mining, (ii) rule inference, and (iii) embedding. In the rule mining process, to identify complex patterns in knowledge graphs, both logic rules and inter-rule correlations are extracted from knowledge graphs based on operations over relation embeddings. To reduce data sparsity, virtual neighbors for OOKG entities are predicted and assigned soft labels by optimizing a rule-constrained problem. We also devise an iterative framework to capture the underlying relations between rule learning and embedding learning. In our experiments, results on both link prediction and triple classification tasks show that the proposed VNC framework achieves state-of-the-art performance on four widely-used knowledge graphs. Further analysis reveals that VNC is robust to the proportion of unseen entities and effectively mitigates data sparsity.
Subgraph Neighboring Relations Infomax for Inductive Link Prediction on Knowledge Graphs
Jul 28, 2022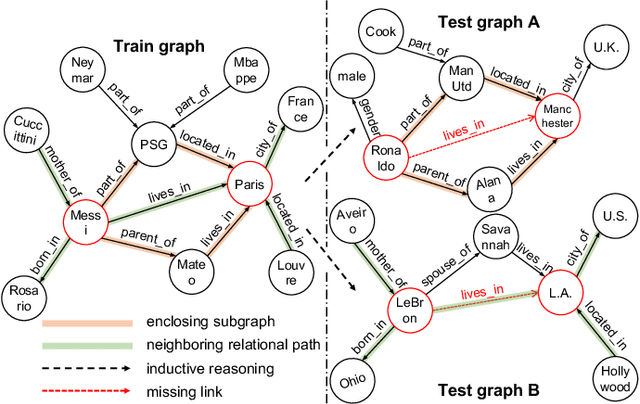

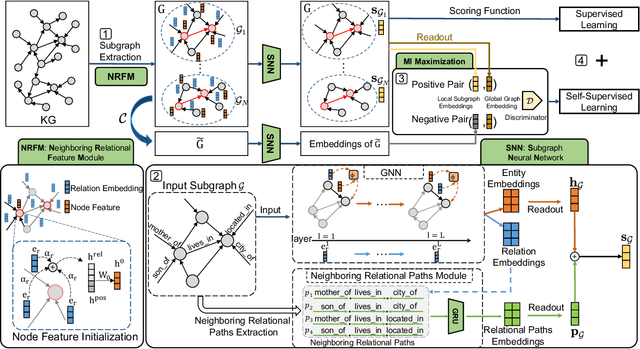
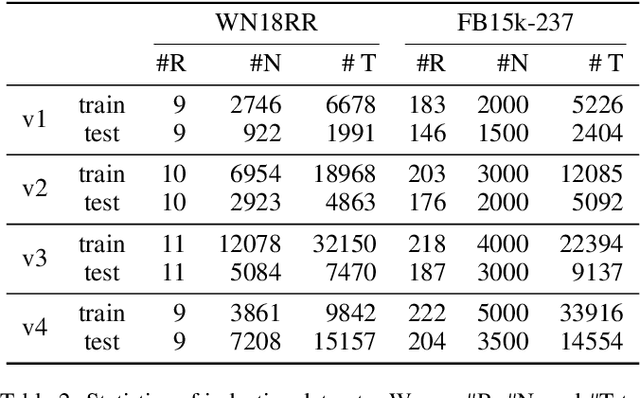
Inductive link prediction for knowledge graph aims at predicting missing links between unseen entities, those not shown in training stage. Most previous works learn entity-specific embeddings of entities, which cannot handle unseen entities. Recent several methods utilize enclosing subgraph to obtain inductive ability. However, all these works only consider the enclosing part of subgraph without complete neighboring relations, which leads to the issue that partial neighboring relations are neglected, and sparse subgraphs are hard to be handled. To address that, we propose Subgraph Neighboring Relations Infomax, SNRI, which sufficiently exploits complete neighboring relations from two aspects: neighboring relational feature for node feature and neighboring relational path for sparse subgraph. To further model neighboring relations in a global way, we innovatively apply mutual information (MI) maximization for knowledge graph. Experiments show that SNRI outperforms existing state-of-art methods by a large margin on inductive link prediction task, and verify the effectiveness of exploring complete neighboring relations in a global way to characterize node features and reason on sparse subgraphs.