 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Player to Master: Enhancing Test-Time Learning of LLM Agents via Reinforcement Learning over Memory
Jun 07, 2026Large language model (LLM) agents are increasingly deployed in long-running settings where improving through experience at test time becomes important. A common approach is to update an explicit memory after each interaction to guide future decisions. However, most existing methods rely on hand-designed prompting rules, making it difficult to align memory updates with downstream objectives over multi-step horizons consistently. We propose MemoPilot, a plug-in memory copilot that explicitly trains the memory update process to improve a frozen LLM's performance across sequential interactions. We formulate memory updating as a multi-turn decision problem and optimize it end-to-end with multi-turn GRPO. Our training recipe introduces (i) a turn-wise reward signal and (ii) a context-independent, turn-level advantage estimation across rollouts, enabling finer-grained credit assignment and more stable training in multi-turn settings. We evaluate MemoPilot on two testbeds: multi-round Rock-Paper-Scissors (RPS) and Limit Texas Hold'em (LHE). Across both environments, MemoPilot substantially improves test-time learning of a frozen player over strong baselines, ranking first in Elo ratings on both games (1762 on LHE and 1590 on RPS) and outperforming all baseline memory methods and proprietary models, including DeepSeek-V3.2.
GLM-5: from Vibe Coding to Agentic Engineering
Feb 17, 2026We present GLM-5, a next-generation foundation model designed to transition the paradigm of vibe coding to agentic engineering. Building upon the agentic, reasoning, and coding (ARC) capabilities of its predecessor, GLM-5 adopts DSA to significantly reduce training and inference costs while maintaining long-context fidelity. To advance model alignment and autonomy, we implement a new asynchronous reinforcement learning infrastructure that drastically improves post-training efficiency by decoupling generation from training. Furthermore, we propose novel asynchronous agent RL algorithms that further improve RL quality, enabling the model to learn from complex, long-horizon interactions more effectively. Through these innovations, GLM-5 achieves state-of-the-art performance on major open benchmarks. Most critically, GLM-5 demonstrates unprecedented capability in real-world coding tasks, surpassing previous baselines in handling end-to-end software engineering challenges. Code, models, and more information are available at https://github.com/zai-org/GLM-5.
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
Aug 08, 2025We present GLM-4.5, an open-source Mixture-of-Experts (MoE) large language model with 355B total parameters and 32B activated parameters, featuring a hybrid reasoning method that supports both thinking and direct response modes. Through multi-stage training on 23T tokens and comprehensive post-training with expert model iteration and reinforcement learning, GLM-4.5 achieves strong performance across agentic, reasoning, and coding (ARC) tasks, scoring 70.1% on TAU-Bench, 91.0% on AIME 24, and 64.2% on SWE-bench Verified. With much fewer parameters than several competitors, GLM-4.5 ranks 3rd overall among all evaluated models and 2nd on agentic benchmarks. We release both GLM-4.5 (355B parameters) and a compact version, GLM-4.5-Air (106B parameters), to advance research in reasoning and agentic AI systems. Code, models, and more information are available at https://github.com/zai-org/GLM-4.5.
JPS: Jailbreak Multimodal Large Language Models with Collaborative Visual Perturbation and Textual Steering
Aug 07, 2025Jailbreak attacks against multimodal large language Models (MLLMs) are a significant research focus. Current research predominantly focuses on maximizing attack success rate (ASR), often overlooking whether the generated responses actually fulfill the attacker's malicious intent. This oversight frequently leads to low-quality outputs that bypass safety filters but lack substantial harmful content. To address this gap, we propose JPS, \underline{J}ailbreak MLLMs with collaborative visual \underline{P}erturbation and textual \underline{S}teering, which achieves jailbreaks via corporation of visual image and textually steering prompt. Specifically, JPS utilizes target-guided adversarial image perturbations for effective safety bypass, complemented by "steering prompt" optimized via a multi-agent system to specifically guide LLM responses fulfilling the attackers' intent. These visual and textual components undergo iterative co-optimization for enhanced performance. To evaluate the quality of attack outcomes, we propose the Malicious Intent Fulfillment Rate (MIFR) metric, assessed using a Reasoning-LLM-based evaluator. Our experiments show JPS sets a new state-of-the-art in both ASR and MIFR across various MLLMs and benchmarks, with analyses confirming its efficacy. Codes are available at \href{https://github.com/thu-coai/JPS}{https://github.com/thu-coai/JPS}. \color{warningcolor}{Warning: This paper contains potentially sensitive contents.}
GLM-4.1V-Thinking: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning
Jul 02, 2025



We present GLM-4.1V-Thinking, a vision-language model (VLM) designed to advance general-purpose multimodal understanding and reasoning. In this report, we share our key findings in the development of the reasoning-centric training framework. We first develop a capable vision foundation model with significant potential through large-scale pre-training, which arguably sets the upper bound for the final performance. We then propose Reinforcement Learning with Curriculum Sampling (RLCS) to unlock the full potential of the model, leading to comprehensive capability enhancement across a diverse range of tasks, including STEM problem solving, video understanding, content recognition, coding, grounding, GUI-based agents, and long document understanding. We open-source GLM-4.1V-9B-Thinking, which achieves state-of-the-art performance among models of comparable size. In a comprehensive evaluation across 28 public benchmarks, our model outperforms Qwen2.5-VL-7B on nearly all tasks and achieves comparable or even superior performance on 18 benchmarks relative to the significantly larger Qwen2.5-VL-72B. Notably, GLM-4.1V-9B-Thinking also demonstrates competitive or superior performance compared to closed-source models such as GPT-4o on challenging tasks including long document understanding and STEM reasoning, further underscoring its strong capabilities. Code, models and more information are released at https://github.com/THUDM/GLM-4.1V-Thinking.
Don't Half-listen: Capturing Key-part Information in Continual Instruction Tuning
Mar 15, 2024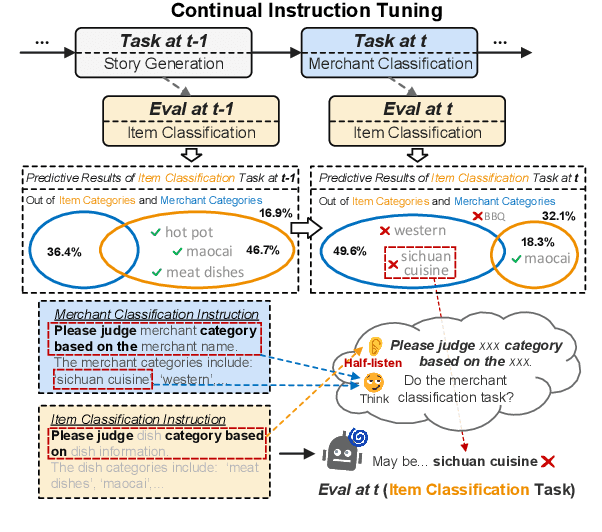



Instruction tuning for large language models (LLMs) can drive them to produce results consistent with human goals in specific downstream tasks. However, the process of continual instruction tuning (CIT) for LLMs may bring about the catastrophic forgetting (CF) problem, where previously learned abilities are degraded. Recent methods try to alleviate the CF problem by modifying models or replaying data, which may only remember the surface-level pattern of instructions and get confused on held-out tasks. In this paper, we propose a novel continual instruction tuning method based on Key-part Information Gain (KPIG). Our method computes the information gain on masked parts to dynamically replay data and refine the training objective, which enables LLMs to capture task-aware information relevant to the correct response and alleviate overfitting to general descriptions in instructions. In addition, we propose two metrics, P-score and V-score, to measure the generalization and instruction-following abilities of LLMs. Experiments demonstrate our method achieves superior performance on both seen and held-out tasks.
Prompt Gating: A Parameter Efficient Tuning Method for Zero-Shot Multi-Source Translation
Dec 19, 2022Multi-source translation (MST), which typically receives multiple source sentences of the same meaning in different languages, has been shown superior to single-source translation. As the quantity of multi-source parallel data is limited, taking full advantage of single-source data and limited multi-source data to make models perform well when receiving as many as possible sources remains a challenge. Unlike previous work mostly devoted to supervised scenarios, we focus on zero-shot MST: expecting models to be able to process unseen combinations of multiple sources, e.g., unseen language combinations, during inference. We propose a simple yet effective parameter efficient method, named Prompt Gating, which appends prompts to the model inputs and attaches gates on the extended hidden states for each encoder layer. It shows strong zero-shot transferability (+9.0 BLEU points maximally) and remarkable compositionality (+15.6 BLEU points maximally) on MST, and also shows its superiorities over baselines on lexically constrained translation.
CUGE: A Chinese Language Understanding and Generation Evaluation Benchmark
Dec 27, 2021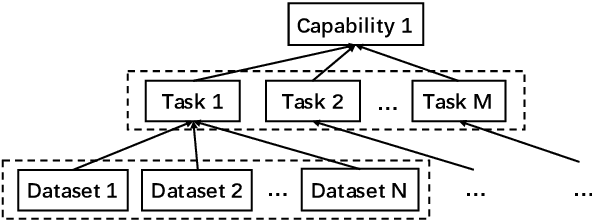
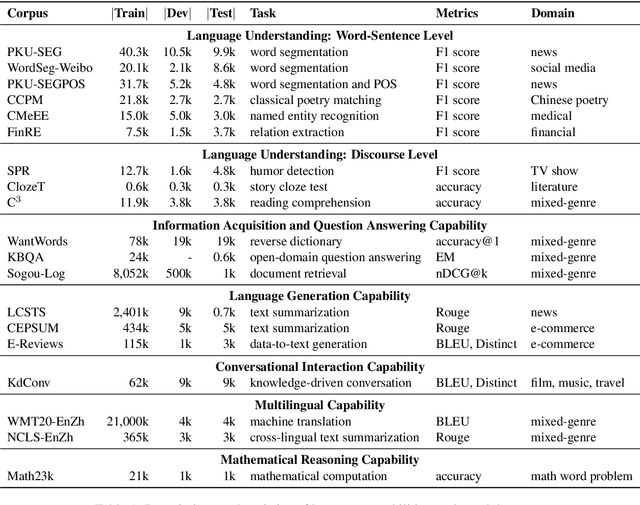


Realizing general-purpose language intelligence has been a longstanding goal for natural language processing, where standard evaluation benchmarks play a fundamental and guiding role. We argue that for general-purpose language intelligence evaluation, the benchmark itself needs to be comprehensive and systematic. To this end, we propose CUGE, a Chinese Language Understanding and Generation Evaluation benchmark with the following features: (1) Hierarchical benchmark framework, where datasets are principally selected and organized with a language capability-task-dataset hierarchy. (2) Multi-level scoring strategy, where different levels of model performance are provided based on the hierarchical framework. To facilitate CUGE, we provide a public leaderboard that can be customized to support flexible model judging criteria. Evaluation results on representative pre-trained language models indicate ample room for improvement towards general-purpose language intelligence. CUGE is publicly available at cuge.baai.ac.cn.
Transfer Learning for Sequence Generation: from Single-source to Multi-source
May 31, 2021
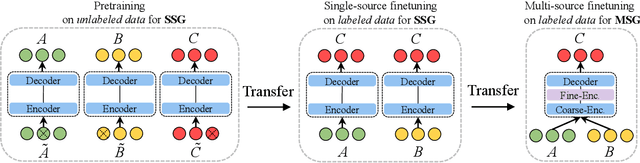
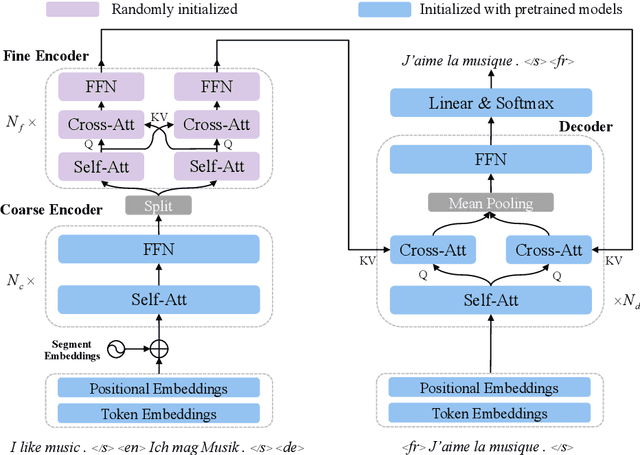
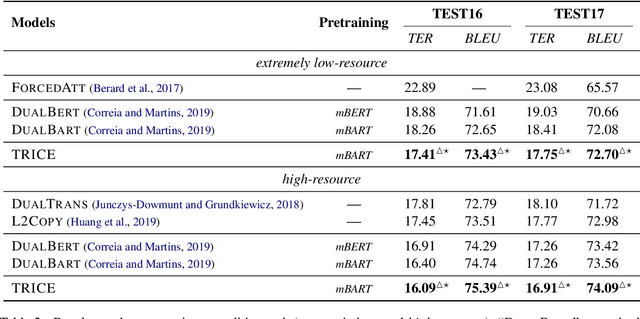
Multi-source sequence generation (MSG) is an important kind of sequence generation tasks that takes multiple sources, including automatic post-editing, multi-source translation, multi-document summarization, etc. As MSG tasks suffer from the data scarcity problem and recent pretrained models have been proven to be effective for low-resource downstream tasks, transferring pretrained sequence-to-sequence models to MSG tasks is essential. Although directly finetuning pretrained models on MSG tasks and concatenating multiple sources into a single long sequence is regarded as a simple method to transfer pretrained models to MSG tasks, we conjecture that the direct finetuning method leads to catastrophic forgetting and solely relying on pretrained self-attention layers to capture cross-source information is not sufficient. Therefore, we propose a two-stage finetuning method to alleviate the pretrain-finetune discrepancy and introduce a novel MSG model with a fine encoder to learn better representations in MSG tasks. Experiments show that our approach achieves new state-of-the-art results on the WMT17 APE task and multi-source translation task using the WMT14 test set. When adapted to document-level translation, our framework outperforms strong baselines significantly.
Neural Machine Translation: A Review of Methods, Resources, and Tools
Dec 31, 2020


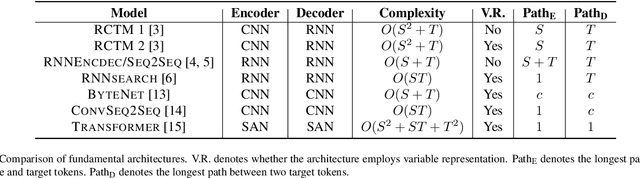
Machine translation (MT) is an important sub-field of natural language processing that aims to translate natural languages using computers. In recent years, end-to-end neural machine translation (NMT) has achieved great success and has become the new mainstream method in practical MT systems. In this article, we first provide a broad review of the methods for NMT and focus on methods relating to architectures, decoding, and data augmentation. Then we summarize the resources and tools that are useful for researchers. Finally, we conclude with a discussion of possible future research directions.