 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransfer Learning for Sequence Generation: from Single-source to Multi-source
May 31, 2021
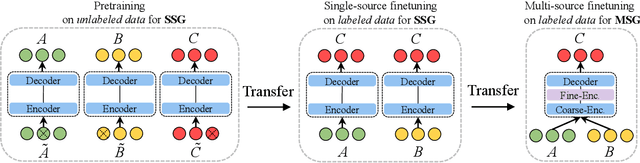
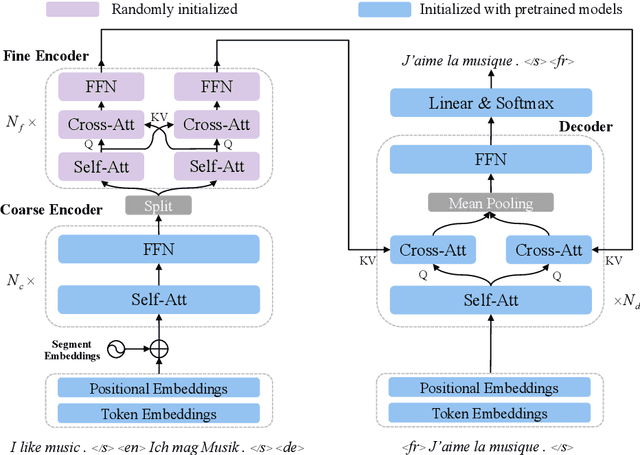
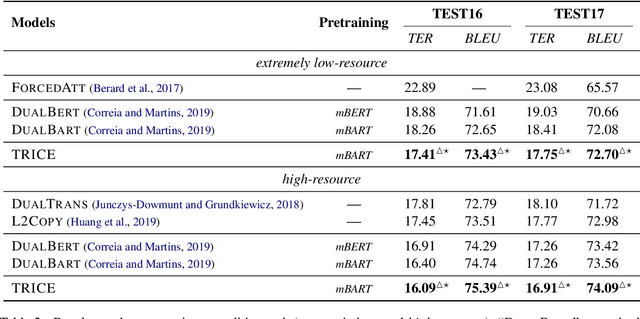
Multi-source sequence generation (MSG) is an important kind of sequence generation tasks that takes multiple sources, including automatic post-editing, multi-source translation, multi-document summarization, etc. As MSG tasks suffer from the data scarcity problem and recent pretrained models have been proven to be effective for low-resource downstream tasks, transferring pretrained sequence-to-sequence models to MSG tasks is essential. Although directly finetuning pretrained models on MSG tasks and concatenating multiple sources into a single long sequence is regarded as a simple method to transfer pretrained models to MSG tasks, we conjecture that the direct finetuning method leads to catastrophic forgetting and solely relying on pretrained self-attention layers to capture cross-source information is not sufficient. Therefore, we propose a two-stage finetuning method to alleviate the pretrain-finetune discrepancy and introduce a novel MSG model with a fine encoder to learn better representations in MSG tasks. Experiments show that our approach achieves new state-of-the-art results on the WMT17 APE task and multi-source translation task using the WMT14 test set. When adapted to document-level translation, our framework outperforms strong baselines significantly.
ComQA:Compositional Question Answering via Hierarchical Graph Neural Networks
Jan 16, 2021

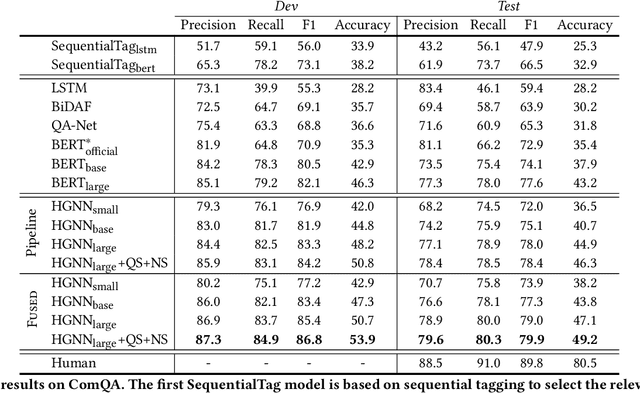
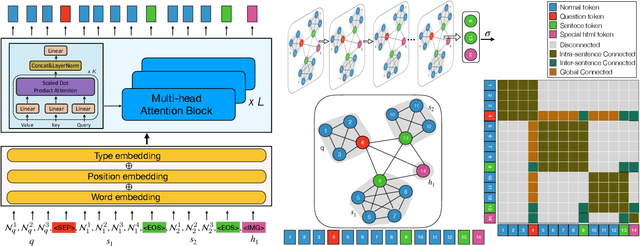
With the development of deep learning techniques and large scale datasets, the question answering (QA) systems have been quickly improved, providing more accurate and satisfying answers. However, current QA systems either focus on the sentence-level answer, i.e., answer selection, or phrase-level answer, i.e., machine reading comprehension. How to produce compositional answers has not been throughout investigated. In compositional question answering, the systems should assemble several supporting evidence from the document to generate the final answer, which is more difficult than sentence-level or phrase-level QA. In this paper, we present a large-scale compositional question answering dataset containing more than 120k human-labeled questions. The answer in this dataset is composed of discontiguous sentences in the corresponding document. To tackle the ComQA problem, we proposed a hierarchical graph neural networks, which represents the document from the low-level word to the high-level sentence. We also devise a question selection and node selection task for pre-training. Our proposed model achieves a significant improvement over previous machine reading comprehension methods and pre-training methods. Codes and dataset can be found at \url{https://github.com/benywon/ComQA}.
Modeling Voting for System Combination in Machine Translation
Jul 14, 2020
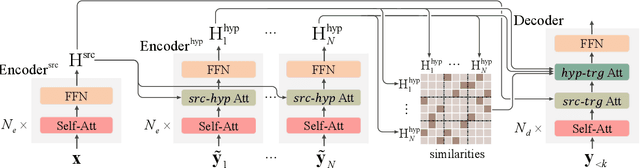
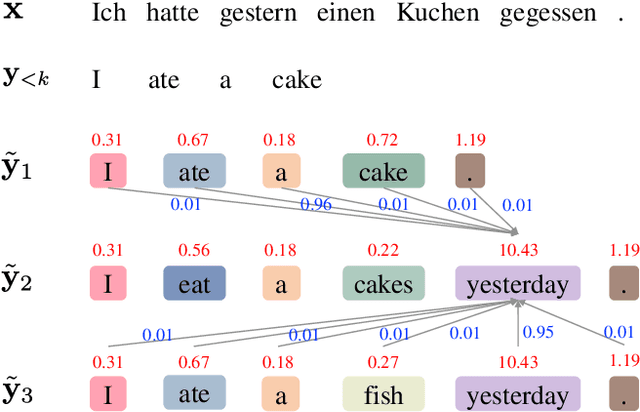
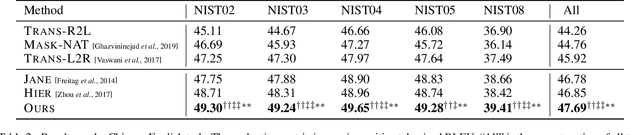
System combination is an important technique for combining the hypotheses of different machine translation systems to improve translation performance. Although early statistical approaches to system combination have been proven effective in analyzing the consensus between hypotheses, they suffer from the error propagation problem due to the use of pipelines. While this problem has been alleviated by end-to-end training of multi-source sequence-to-sequence models recently, these neural models do not explicitly analyze the relations between hypotheses and fail to capture their agreement because the attention to a word in a hypothesis is calculated independently, ignoring the fact that the word might occur in multiple hypotheses. In this work, we propose an approach to modeling voting for system combination in machine translation. The basic idea is to enable words in hypotheses from different systems to vote on words that are representative and should get involved in the generation process. This can be done by quantifying the influence of each voter and its preference for each candidate. Our approach combines the advantages of statistical and neural methods since it can not only analyze the relations between hypotheses but also allow for end-to-end training. Experiments show that our approach is capable of better taking advantage of the consensus between hypotheses and achieves significant improvements over state-of-the-art baselines on Chinese-English and English-German machine translation tasks.
ReCO: A Large Scale Chinese Reading Comprehension Dataset on Opinion
Jun 22, 2020

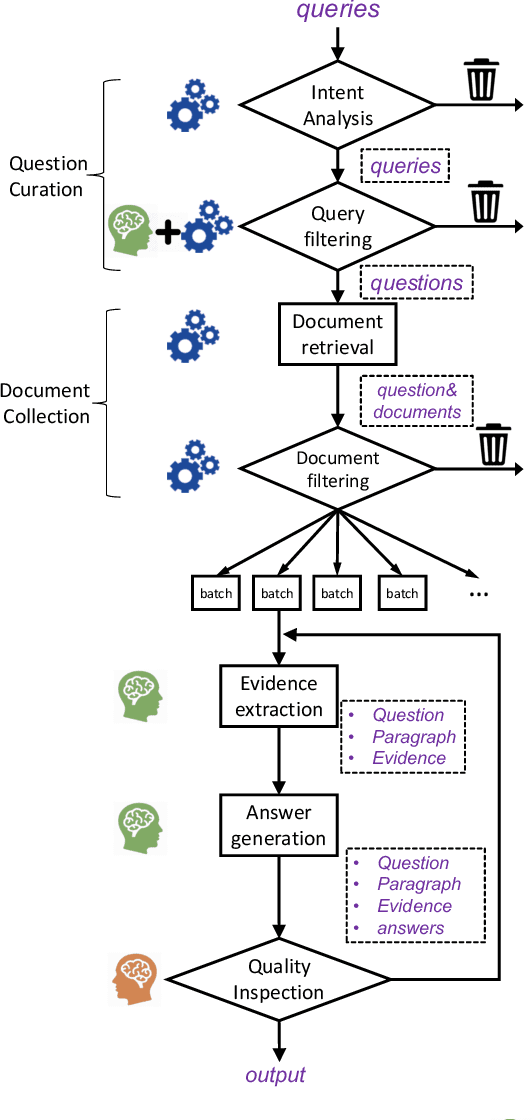
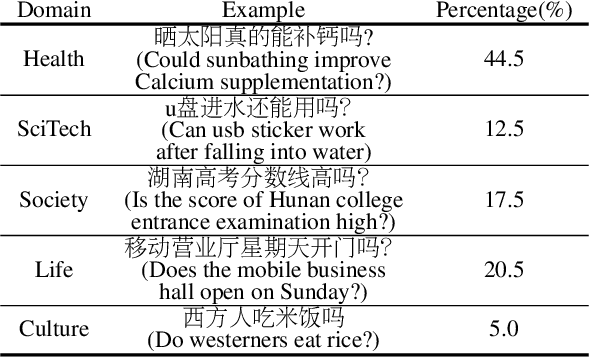
This paper presents the ReCO, a human-curated ChineseReading Comprehension dataset on Opinion. The questions in ReCO are opinion based queries issued to the commercial search engine. The passages are provided by the crowdworkers who extract the support snippet from the retrieved documents. Finally, an abstractive yes/no/uncertain answer was given by the crowdworkers. The release of ReCO consists of 300k questions that to our knowledge is the largest in Chinese reading comprehension. A prominent characteristic of ReCO is that in addition to the original context paragraph, we also provided the support evidence that could be directly used to answer the question. Quality analysis demonstrates the challenge of ReCO that requires various types of reasoning skills, such as causal inference, logical reasoning, etc. Current QA models that perform very well on many question answering problems, such as BERT, only achieve 77% accuracy on this dataset, a large margin behind humans nearly 92% performance, indicating ReCO presents a good challenge for machine reading comprehension. The codes, datasets are freely available at https://github.com/benywon/ReCO.
A Self-Training Method for Machine Reading Comprehension with Soft Evidence Extraction
May 11, 2020
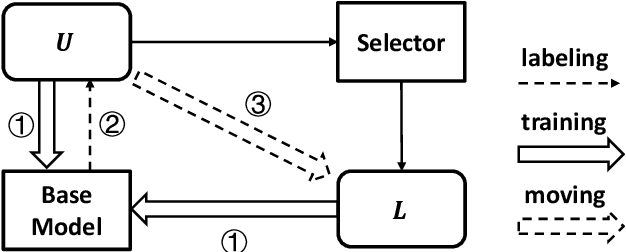
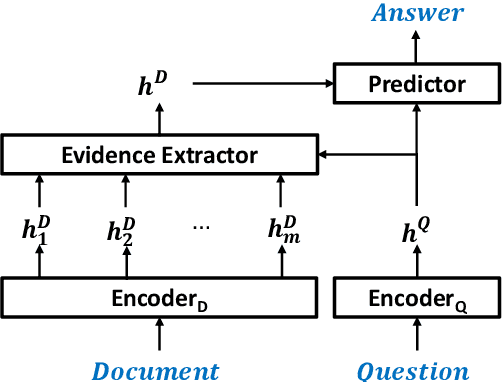
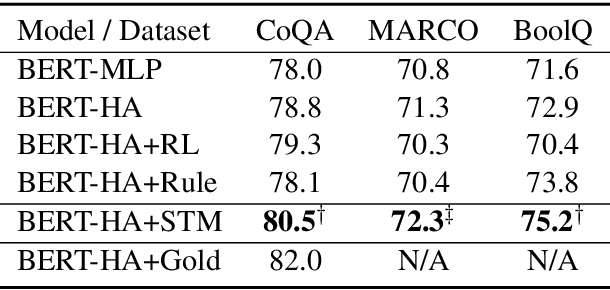
Neural models have achieved great success on machine reading comprehension (MRC), many of which typically consist of two components: an evidence extractor and an answer predictor. The former seeks the most relevant information from a reference text, while the latter is to locate or generate answers from the extracted evidence. Despite the importance of evidence labels for training the evidence extractor, they are not cheaply accessible, particularly in many non-extractive MRC tasks such as YES/NO question answering and multi-choice MRC. To address this problem, we present a Self-Training method (STM), which supervises the evidence extractor with auto-generated evidence labels in an iterative process. At each iteration, a base MRC model is trained with golden answers and noisy evidence labels. The trained model will predict pseudo evidence labels as extra supervision in the next iteration. We evaluate STM on seven datasets over three MRC tasks. Experimental results demonstrate the improvement on existing MRC models, and we also analyze how and why such a self-training method works in MRC.
Neural Machine Translation with Explicit Phrase Alignment
Nov 28, 2019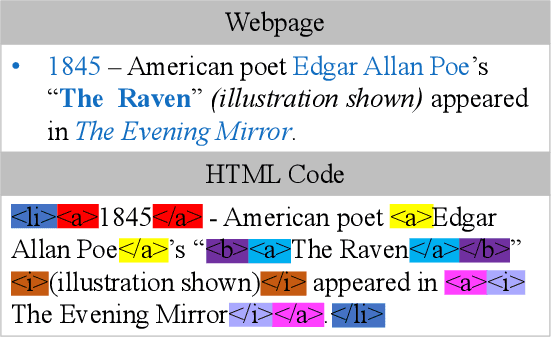
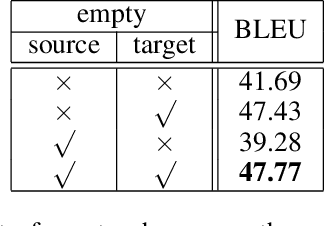

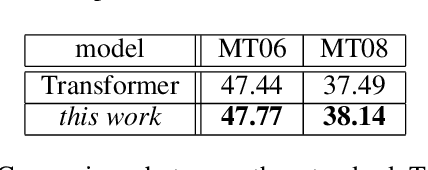
While neural machine translation (NMT) has achieved state-of-the-art translation performance, it is unable to capture the alignment between the input and output during the translation process. The lack of alignment in NMT models leads to three problems: it is hard to (1) interpret the translation process, (2) impose lexical constraints, and (3) impose structural constraints. To alleviate these problems, we propose to introduce explicit phrase alignment into the translation process of arbitrary NMT models. The key idea is to build a search space similar to that of phrase-based statistical machine translation for NMT where phrase alignment is readily available. We design a new decoding algorithm that can easily impose lexical and structural constraints. Experiments show that our approach makes the translation process of NMT more interpretable without sacrificing translation quality. In addition, our approach achieves significant improvements in lexically and structurally constrained translation tasks.
Learning to Copy for Automatic Post-Editing
Nov 09, 2019
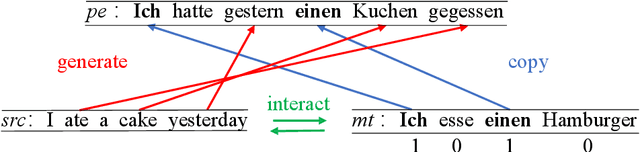
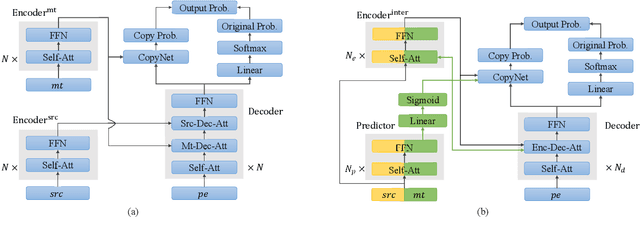
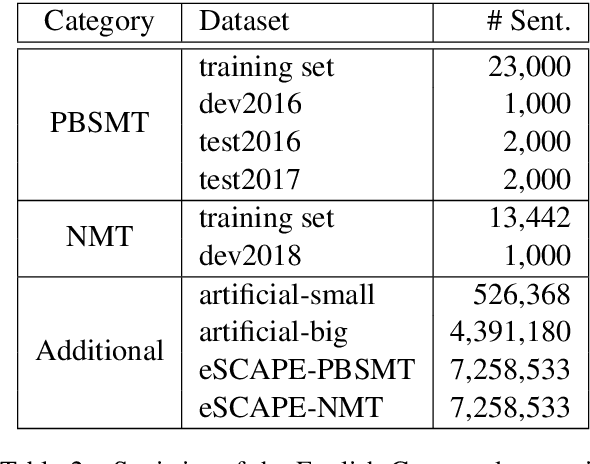
Automatic post-editing (APE), which aims to correct errors in the output of machine translation systems in a post-processing step, is an important task in natural language processing. While recent work has achieved considerable performance gains by using neural networks, how to model the copying mechanism for APE remains a challenge. In this work, we propose a new method for modeling copying for APE. To better identify translation errors, our method learns the representations of source sentences and system outputs in an interactive way. These representations are used to explicitly indicate which words in the system outputs should be copied, which is useful to help CopyNet (Gu et al., 2016) better generate post-edited translations. Experiments on the datasets of the WMT 2016-2017 APE shared tasks show that our approach outperforms all best published results.
Adversarial Examples with Difficult Common Words for Paraphrase Identification
Sep 06, 2019
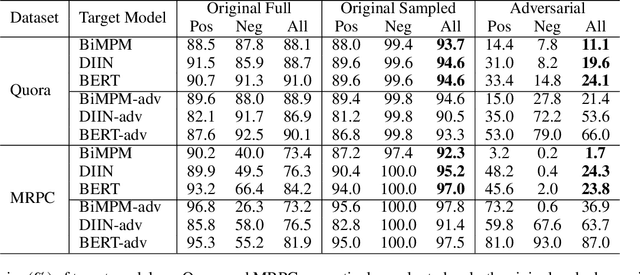


Despite the success of deep models for paraphrase identification on benchmark datasets, these models are still vulnerable to adversarial examples. In this paper, we propose a novel algorithm to generate a new type of adversarial examples to study the robustness of deep paraphrase identification models. We first sample an original sentence pair from the corpus and then adversarially replace some word pairs with difficult common words. We take multiple steps and use beam search to find a modification solution that makes the target model fail, and thereby obtain an adversarial example. The word replacement is also constrained by heuristic rules and a language model, to preserve the label and grammaticality of the example during modification. Experiments show that our algorithm can generate adversarial examples on which the performance of the target model drops dramatically. Meanwhile, human annotators are much less affected, and the generated sentences retain a good grammaticality. We also show that adversarial training with generated adversarial examples can improve model robustness.
Prior Knowledge Integration for Neural Machine Translation using Posterior Regularization
Nov 02, 2018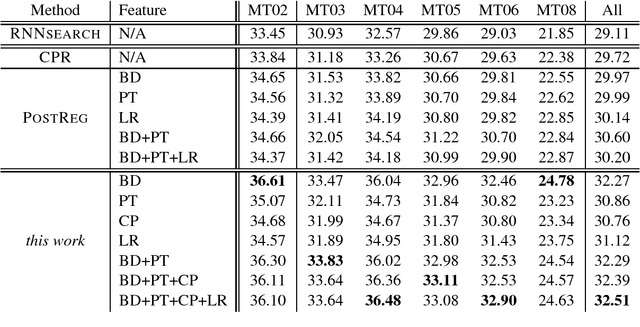
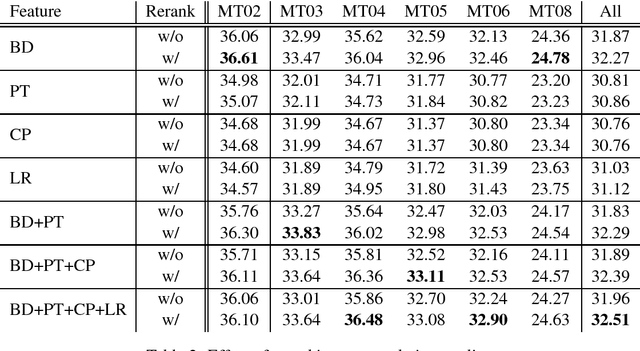
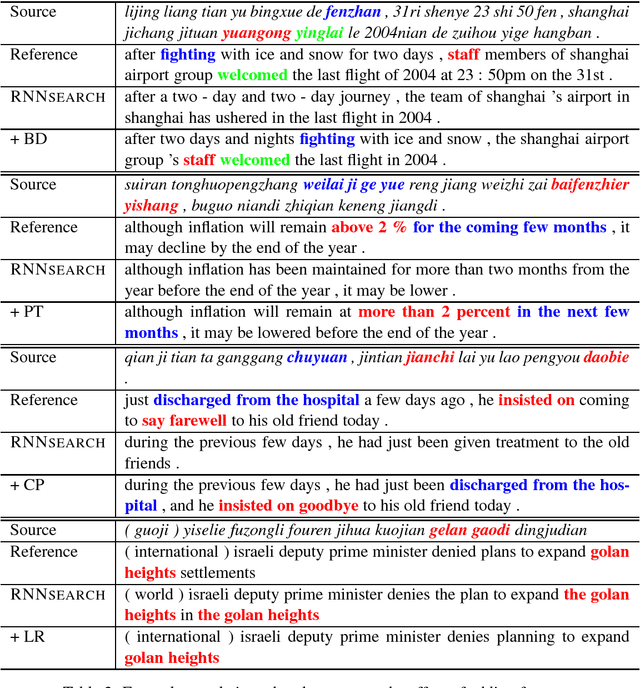
Although neural machine translation has made significant progress recently, how to integrate multiple overlapping, arbitrary prior knowledge sources remains a challenge. In this work, we propose to use posterior regularization to provide a general framework for integrating prior knowledge into neural machine translation. We represent prior knowledge sources as features in a log-linear model, which guides the learning process of the neural translation model. Experiments on Chinese-English translation show that our approach leads to significant improvements.
Improving the Transformer Translation Model with Document-Level Context
Oct 08, 2018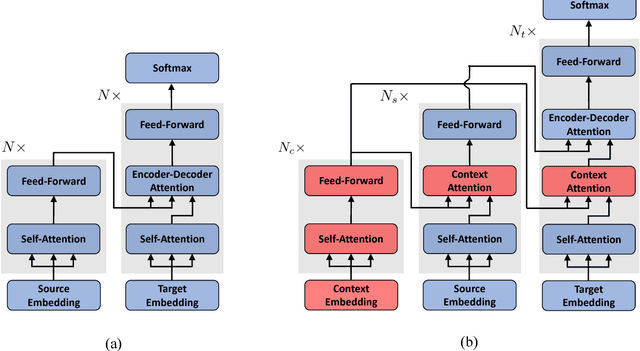


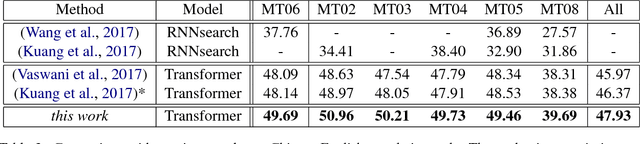
Although the Transformer translation model (Vaswani et al., 2017) has achieved state-of-the-art performance in a variety of translation tasks, how to use document-level context to deal with discourse phenomena problematic for Transformer still remains a challenge. In this work, we extend the Transformer model with a new context encoder to represent document-level context, which is then incorporated into the original encoder and decoder. As large-scale document-level parallel corpora are usually not available, we introduce a two-step training method to take full advantage of abundant sentence-level parallel corpora and limited document-level parallel corpora. Experiments on the NIST Chinese-English datasets and the IWSLT French-English datasets show that our approach improves over Transformer significantly.