 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Machine Translation with Explicit Phrase Alignment
Nov 28, 2019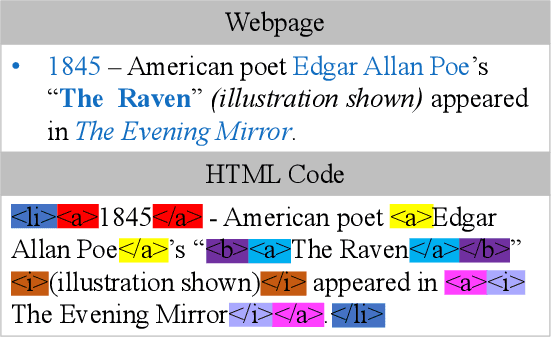

While neural machine translation (NMT) has achieved state-of-the-art translation performance, it is unable to capture the alignment between the input and output during the translation process. The lack of alignment in NMT models leads to three problems: it is hard to (1) interpret the translation process, (2) impose lexical constraints, and (3) impose structural constraints. To alleviate these problems, we propose to introduce explicit phrase alignment into the translation process of arbitrary NMT models. The key idea is to build a search space similar to that of phrase-based statistical machine translation for NMT where phrase alignment is readily available. We design a new decoding algorithm that can easily impose lexical and structural constraints. Experiments show that our approach makes the translation process of NMT more interpretable without sacrificing translation quality. In addition, our approach achieves significant improvements in lexically and structurally constrained translation tasks.
Improving the Transformer Translation Model with Document-Level Context
Oct 08, 2018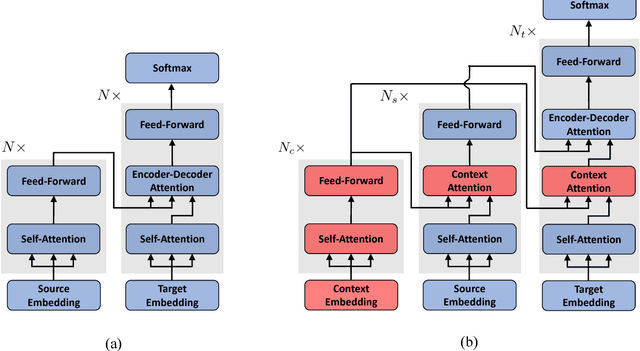


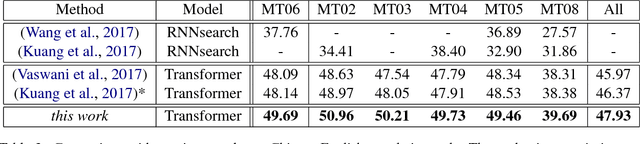
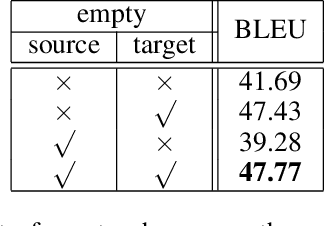
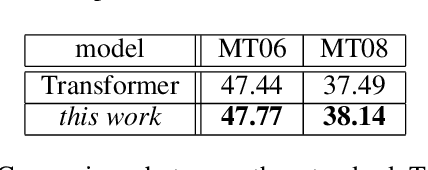
Although the Transformer translation model (Vaswani et al., 2017) has achieved state-of-the-art performance in a variety of translation tasks, how to use document-level context to deal with discourse phenomena problematic for Transformer still remains a challenge. In this work, we extend the Transformer model with a new context encoder to represent document-level context, which is then incorporated into the original encoder and decoder. As large-scale document-level parallel corpora are usually not available, we introduce a two-step training method to take full advantage of abundant sentence-level parallel corpora and limited document-level parallel corpora. Experiments on the NIST Chinese-English datasets and the IWSLT French-English datasets show that our approach improves over Transformer significantly.