 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReCO: A Large Scale Chinese Reading Comprehension Dataset on Opinion
Paper and Code


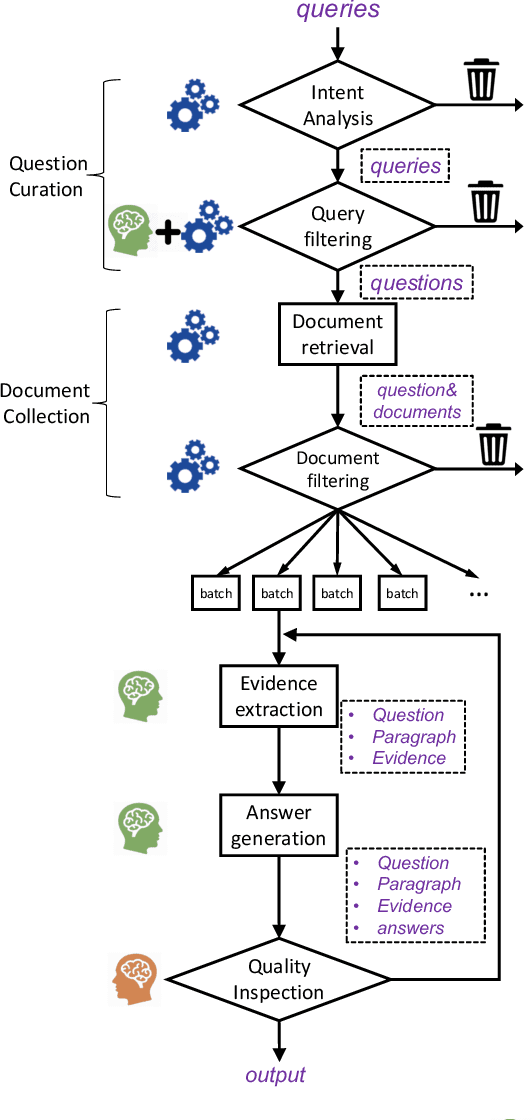
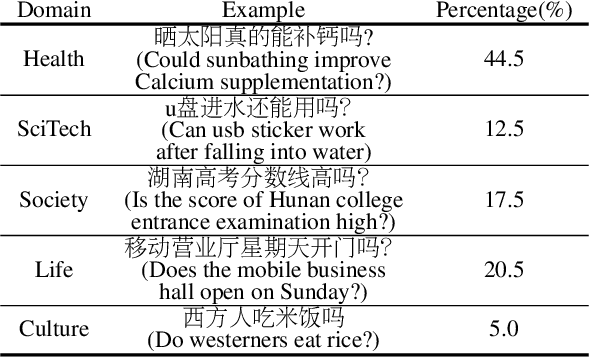
This paper presents the ReCO, a human-curated ChineseReading Comprehension dataset on Opinion. The questions in ReCO are opinion based queries issued to the commercial search engine. The passages are provided by the crowdworkers who extract the support snippet from the retrieved documents. Finally, an abstractive yes/no/uncertain answer was given by the crowdworkers. The release of ReCO consists of 300k questions that to our knowledge is the largest in Chinese reading comprehension. A prominent characteristic of ReCO is that in addition to the original context paragraph, we also provided the support evidence that could be directly used to answer the question. Quality analysis demonstrates the challenge of ReCO that requires various types of reasoning skills, such as causal inference, logical reasoning, etc. Current QA models that perform very well on many question answering problems, such as BERT, only achieve 77% accuracy on this dataset, a large margin behind humans nearly 92% performance, indicating ReCO presents a good challenge for machine reading comprehension. The codes, datasets are freely available at https://github.com/benywon/ReCO.