 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBaichuan-M3: Modeling Clinical Inquiry for Reliable Medical Decision-Making
Feb 06, 2026We introduce Baichuan-M3, a medical-enhanced large language model engineered to shift the paradigm from passive question-answering to active, clinical-grade decision support. Addressing the limitations of existing systems in open-ended consultations, Baichuan-M3 utilizes a specialized training pipeline to model the systematic workflow of a physician. Key capabilities include: (i) proactive information acquisition to resolve ambiguity; (ii) long-horizon reasoning that unifies scattered evidence into coherent diagnoses; and (iii) adaptive hallucination suppression to ensure factual reliability. Empirical evaluations demonstrate that Baichuan-M3 achieves state-of-the-art results on HealthBench, the newly introduced HealthBench-Hallu and ScanBench, significantly outperforming GPT-5.2 in clinical inquiry, advisory and safety. The models are publicly available at https://huggingface.co/collections/baichuan-inc/baichuan-m3.
CUS3D :CLIP-based Unsupervised 3D Segmentation via Object-level Denoise
Sep 21, 2024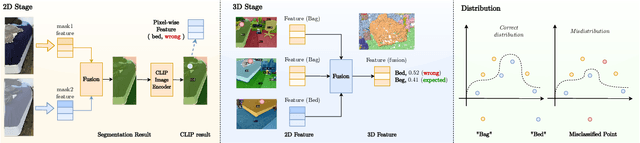
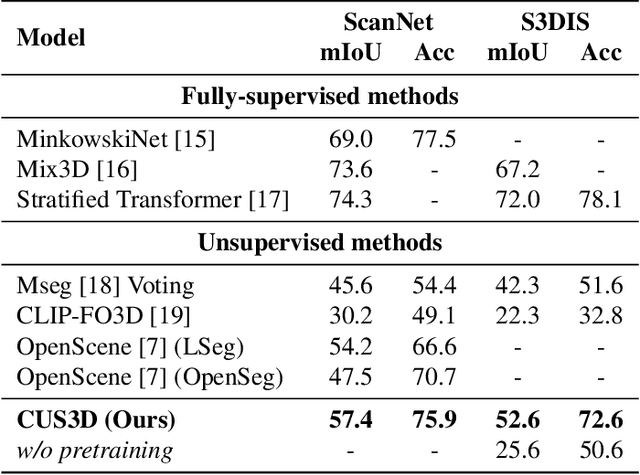

To ease the difficulty of acquiring annotation labels in 3D data, a common method is using unsupervised and open-vocabulary semantic segmentation, which leverage 2D CLIP semantic knowledge. In this paper, unlike previous research that ignores the ``noise'' raised during feature projection from 2D to 3D, we propose a novel distillation learning framework named CUS3D. In our approach, an object-level denosing projection module is designed to screen out the ``noise'' and ensure more accurate 3D feature. Based on the obtained features, a multimodal distillation learning module is designed to align the 3D feature with CLIP semantic feature space with object-centered constrains to achieve advanced unsupervised semantic segmentation. We conduct comprehensive experiments in both unsupervised and open-vocabulary segmentation, and the results consistently showcase the superiority of our model in achieving advanced unsupervised segmentation results and its effectiveness in open-vocabulary segmentation.
Augmentation-based Unsupervised Cross-Domain Functional MRI Adaptation for Major Depressive Disorder Identification
May 31, 2024



Major depressive disorder (MDD) is a common mental disorder that typically affects a person's mood, cognition, behavior, and physical health. Resting-state functional magnetic resonance imaging (rs-fMRI) data are widely used for computer-aided diagnosis of MDD. While multi-site fMRI data can provide more data for training reliable diagnostic models, significant cross-site data heterogeneity would result in poor model generalizability. Many domain adaptation methods are designed to reduce the distributional differences between sites to some extent, but usually ignore overfitting problem of the model on the source domain. Intuitively, target data augmentation can alleviate the overfitting problem by forcing the model to learn more generalized features and reduce the dependence on source domain data. In this work, we propose a new augmentation-based unsupervised cross-domain fMRI adaptation (AUFA) framework for automatic diagnosis of MDD. The AUFA consists of 1) a graph representation learning module for extracting rs-fMRI features with spatial attention, 2) a domain adaptation module for feature alignment between source and target data, 3) an augmentation-based self-optimization module for alleviating model overfitting on the source domain, and 4) a classification module. Experimental results on 1,089 subjects suggest that AUFA outperforms several state-of-the-art methods in MDD identification. Our approach not only reduces data heterogeneity between different sites, but also localizes disease-related functional connectivity abnormalities and provides interpretability for the model.
Baichuan 2: Open Large-scale Language Models
Sep 20, 2023Large language models (LLMs) have demonstrated remarkable performance on a variety of natural language tasks based on just a few examples of natural language instructions, reducing the need for extensive feature engineering. However, most powerful LLMs are closed-source or limited in their capability for languages other than English. In this technical report, we present Baichuan 2, a series of large-scale multilingual language models containing 7 billion and 13 billion parameters, trained from scratch, on 2.6 trillion tokens. Baichuan 2 matches or outperforms other open-source models of similar size on public benchmarks like MMLU, CMMLU, GSM8K, and HumanEval. Furthermore, Baichuan 2 excels in vertical domains such as medicine and law. We will release all pre-training model checkpoints to benefit the research community in better understanding the training dynamics of Baichuan 2.
MQENet: A Mesh Quality Evaluation Neural Network Based on Dynamic Graph Attention
Sep 03, 2023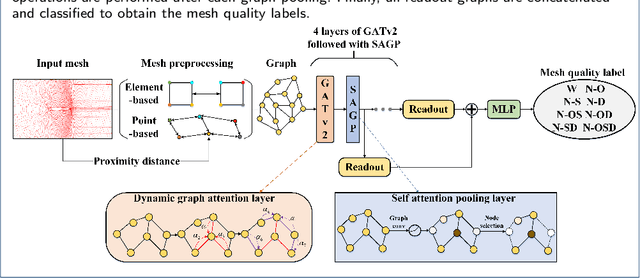

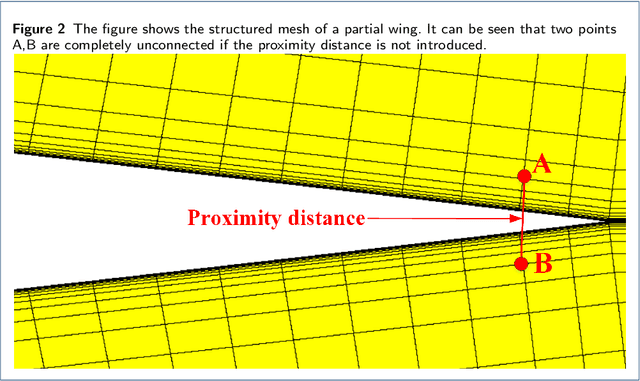

With the development of computational fluid dynamics, the requirements for the fluid simulation accuracy in industrial applications have also increased. The quality of the generated mesh directly affects the simulation accuracy. However, previous mesh quality metrics and models cannot evaluate meshes comprehensively and objectively. To this end, we propose MQENet, a structured mesh quality evaluation neural network based on dynamic graph attention. MQENet treats the mesh evaluation task as a graph classification task for classifying the quality of the input structured mesh. To make graphs generated from structured meshes more informative, MQENet introduces two novel structured mesh preprocessing algorithms. These two algorithms can also improve the conversion efficiency of structured mesh data. Experimental results on the benchmark structured mesh dataset NACA-Market show the effectiveness of MQENet in the mesh quality evaluation task.
Preserving Specificity in Federated Graph Learning for fMRI-based Neurological Disorder Identification
Aug 20, 2023



Resting-state functional magnetic resonance imaging (rs-fMRI) offers a non-invasive approach to examining abnormal brain connectivity associated with brain disorders. Graph neural network (GNN) gains popularity in fMRI representation learning and brain disorder analysis with powerful graph representation capabilities. Training a general GNN often necessitates a large-scale dataset from multiple imaging centers/sites, but centralizing multi-site data generally faces inherent challenges related to data privacy, security, and storage burden. Federated Learning (FL) enables collaborative model training without centralized multi-site fMRI data. Unfortunately, previous FL approaches for fMRI analysis often ignore site-specificity, including demographic factors such as age, gender, and education level. To this end, we propose a specificity-aware federated graph learning (SFGL) framework for rs-fMRI analysis and automated brain disorder identification, with a server and multiple clients/sites for federated model aggregation and prediction. At each client, our model consists of a shared and a personalized branch, where parameters of the shared branch are sent to the server while those of the personalized branch remain local. This can facilitate knowledge sharing among sites and also helps preserve site specificity. In the shared branch, we employ a spatio-temporal attention graph isomorphism network to learn dynamic fMRI representations. In the personalized branch, we integrate vectorized demographic information (i.e., age, gender, and education years) and functional connectivity networks to preserve site-specific characteristics. Representations generated by the two branches are then fused for classification. Experimental results on two fMRI datasets with a total of 1,218 subjects suggest that SFGL outperforms several state-of-the-art approaches.
ComQA:Compositional Question Answering via Hierarchical Graph Neural Networks
Jan 16, 2021

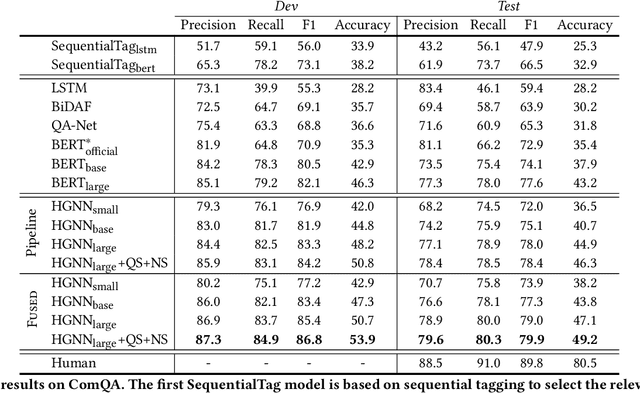
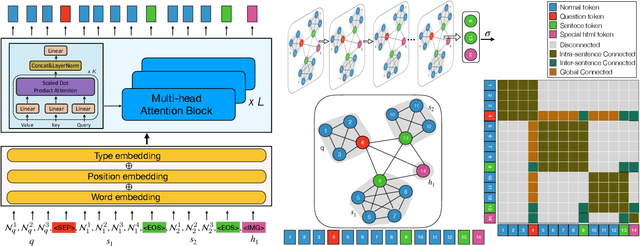
With the development of deep learning techniques and large scale datasets, the question answering (QA) systems have been quickly improved, providing more accurate and satisfying answers. However, current QA systems either focus on the sentence-level answer, i.e., answer selection, or phrase-level answer, i.e., machine reading comprehension. How to produce compositional answers has not been throughout investigated. In compositional question answering, the systems should assemble several supporting evidence from the document to generate the final answer, which is more difficult than sentence-level or phrase-level QA. In this paper, we present a large-scale compositional question answering dataset containing more than 120k human-labeled questions. The answer in this dataset is composed of discontiguous sentences in the corresponding document. To tackle the ComQA problem, we proposed a hierarchical graph neural networks, which represents the document from the low-level word to the high-level sentence. We also devise a question selection and node selection task for pre-training. Our proposed model achieves a significant improvement over previous machine reading comprehension methods and pre-training methods. Codes and dataset can be found at \url{https://github.com/benywon/ComQA}.
ReCO: A Large Scale Chinese Reading Comprehension Dataset on Opinion
Jun 22, 2020

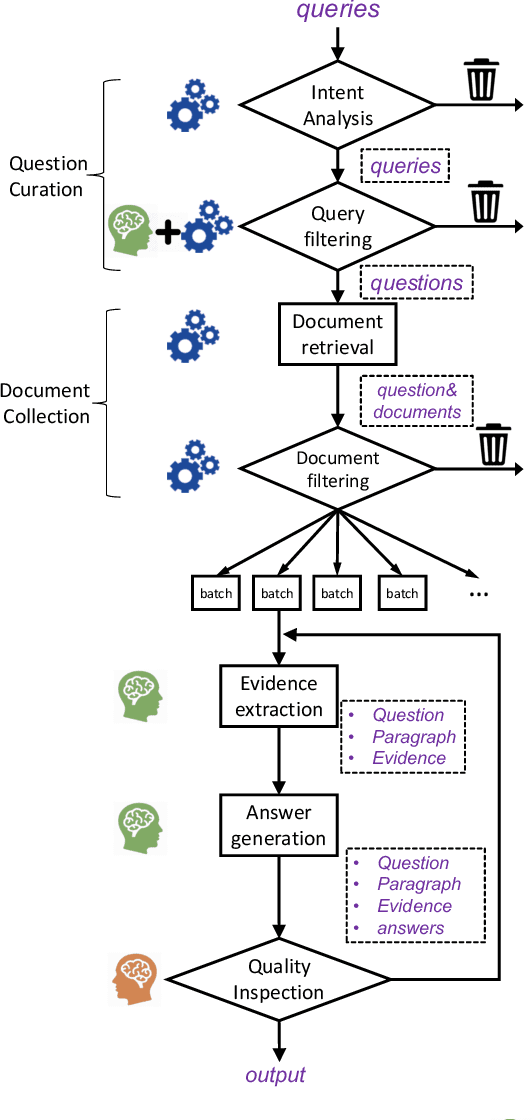
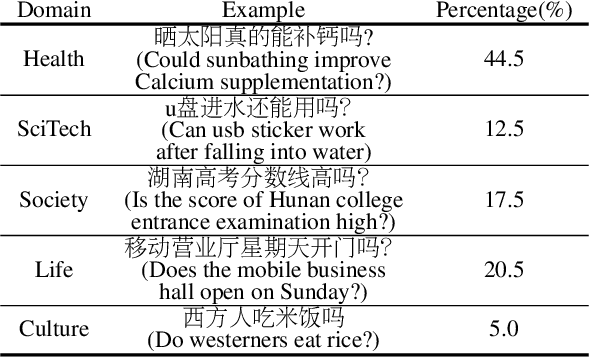
This paper presents the ReCO, a human-curated ChineseReading Comprehension dataset on Opinion. The questions in ReCO are opinion based queries issued to the commercial search engine. The passages are provided by the crowdworkers who extract the support snippet from the retrieved documents. Finally, an abstractive yes/no/uncertain answer was given by the crowdworkers. The release of ReCO consists of 300k questions that to our knowledge is the largest in Chinese reading comprehension. A prominent characteristic of ReCO is that in addition to the original context paragraph, we also provided the support evidence that could be directly used to answer the question. Quality analysis demonstrates the challenge of ReCO that requires various types of reasoning skills, such as causal inference, logical reasoning, etc. Current QA models that perform very well on many question answering problems, such as BERT, only achieve 77% accuracy on this dataset, a large margin behind humans nearly 92% performance, indicating ReCO presents a good challenge for machine reading comprehension. The codes, datasets are freely available at https://github.com/benywon/ReCO.