 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCUS3D :CLIP-based Unsupervised 3D Segmentation via Object-level Denoise
Sep 21, 2024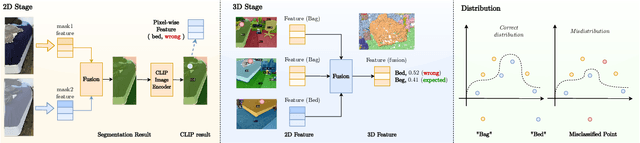
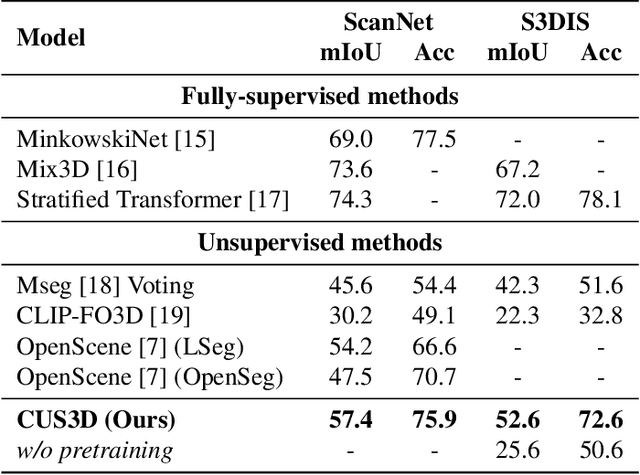
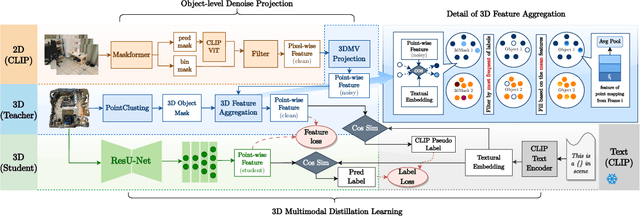

To ease the difficulty of acquiring annotation labels in 3D data, a common method is using unsupervised and open-vocabulary semantic segmentation, which leverage 2D CLIP semantic knowledge. In this paper, unlike previous research that ignores the ``noise'' raised during feature projection from 2D to 3D, we propose a novel distillation learning framework named CUS3D. In our approach, an object-level denosing projection module is designed to screen out the ``noise'' and ensure more accurate 3D feature. Based on the obtained features, a multimodal distillation learning module is designed to align the 3D feature with CLIP semantic feature space with object-centered constrains to achieve advanced unsupervised semantic segmentation. We conduct comprehensive experiments in both unsupervised and open-vocabulary segmentation, and the results consistently showcase the superiority of our model in achieving advanced unsupervised segmentation results and its effectiveness in open-vocabulary segmentation.