 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMQENet: A Mesh Quality Evaluation Neural Network Based on Dynamic Graph Attention
Sep 03, 2023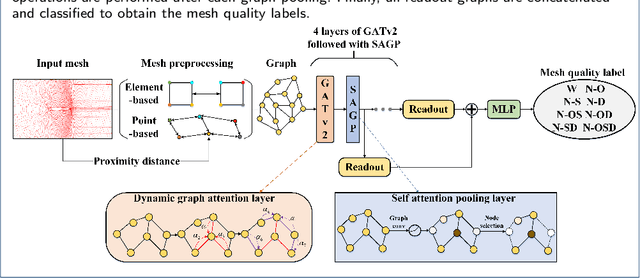

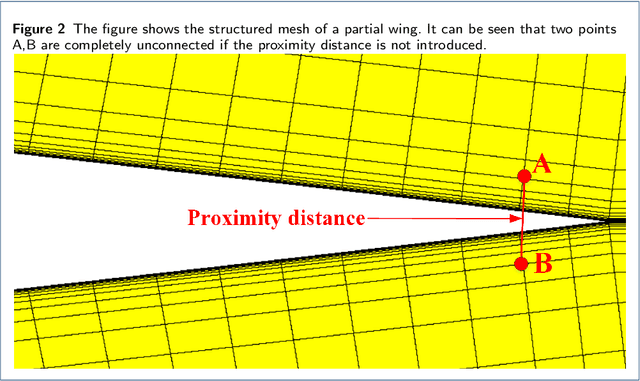

With the development of computational fluid dynamics, the requirements for the fluid simulation accuracy in industrial applications have also increased. The quality of the generated mesh directly affects the simulation accuracy. However, previous mesh quality metrics and models cannot evaluate meshes comprehensively and objectively. To this end, we propose MQENet, a structured mesh quality evaluation neural network based on dynamic graph attention. MQENet treats the mesh evaluation task as a graph classification task for classifying the quality of the input structured mesh. To make graphs generated from structured meshes more informative, MQENet introduces two novel structured mesh preprocessing algorithms. These two algorithms can also improve the conversion efficiency of structured mesh data. Experimental results on the benchmark structured mesh dataset NACA-Market show the effectiveness of MQENet in the mesh quality evaluation task.
Boundary Guided Semantic Learning for Real-time COVID-19 Lung Infection Segmentation System
Sep 07, 2022
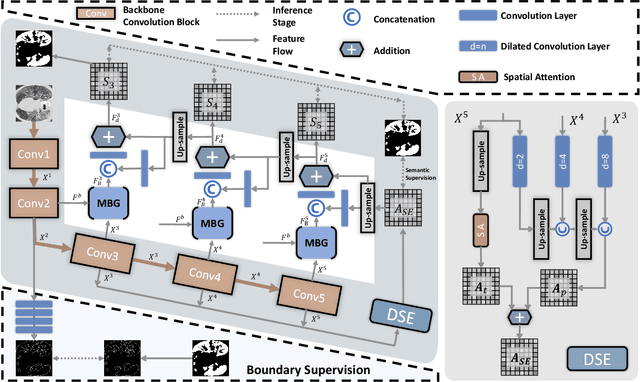
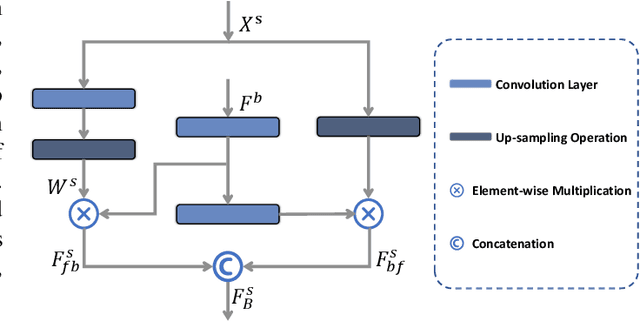
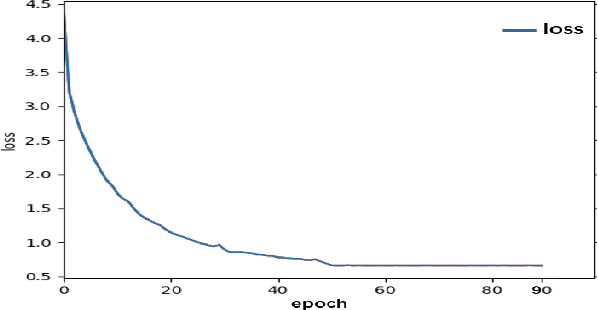
The coronavirus disease 2019 (COVID-19) continues to have a negative impact on healthcare systems around the world, though the vaccines have been developed and national vaccination coverage rate is steadily increasing. At the current stage, automatically segmenting the lung infection area from CT images is essential for the diagnosis and treatment of COVID-19. Thanks to the development of deep learning technology, some deep learning solutions for lung infection segmentation have been proposed. However, due to the scattered distribution, complex background interference and blurred boundaries, the accuracy and completeness of the existing models are still unsatisfactory. To this end, we propose a boundary guided semantic learning network (BSNet) in this paper. On the one hand, the dual-branch semantic enhancement module that combines the top-level semantic preservation and progressive semantic integration is designed to model the complementary relationship between different high-level features, thereby promoting the generation of more complete segmentation results. On the other hand, the mirror-symmetric boundary guidance module is proposed to accurately detect the boundaries of the lesion regions in a mirror-symmetric way. Experiments on the publicly available dataset demonstrate that our BSNet outperforms the existing state-of-the-art competitors and achieves a real-time inference speed of 44 FPS.
BCS-Net: Boundary, Context and Semantic for Automatic COVID-19 Lung Infection Segmentation from CT Images
Jul 17, 2022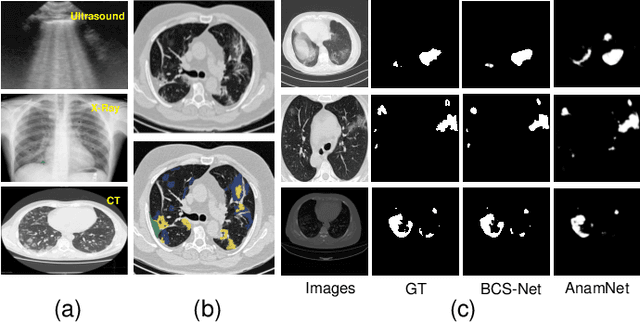
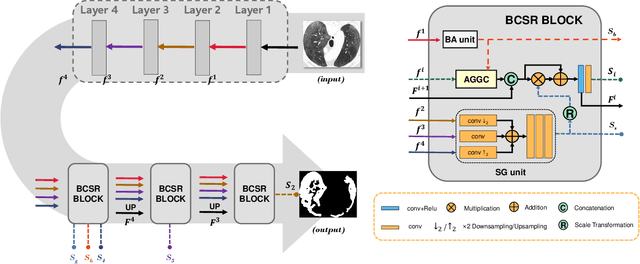
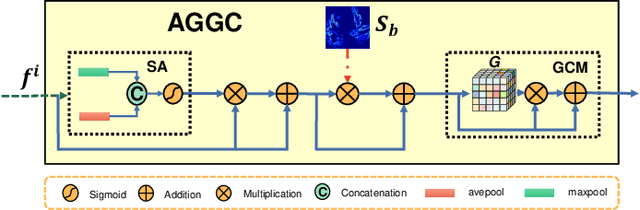
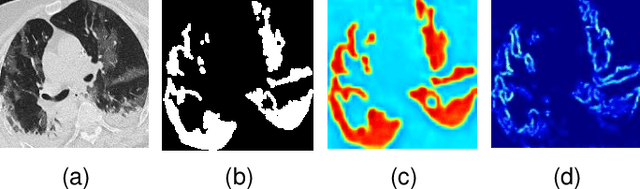
The spread of COVID-19 has brought a huge disaster to the world, and the automatic segmentation of infection regions can help doctors to make diagnosis quickly and reduce workload. However, there are several challenges for the accurate and complete segmentation, such as the scattered infection area distribution, complex background noises, and blurred segmentation boundaries. To this end, in this paper, we propose a novel network for automatic COVID-19 lung infection segmentation from CT images, named BCS-Net, which considers the boundary, context, and semantic attributes. The BCS-Net follows an encoder-decoder architecture, and more designs focus on the decoder stage that includes three progressively Boundary-Context-Semantic Reconstruction (BCSR) blocks. In each BCSR block, the attention-guided global context (AGGC) module is designed to learn the most valuable encoder features for decoder by highlighting the important spatial and boundary locations and modeling the global context dependence. Besides, a semantic guidance (SG) unit generates the semantic guidance map to refine the decoder features by aggregating multi-scale high-level features at the intermediate resolution. Extensive experiments demonstrate that our proposed framework outperforms the existing competitors both qualitatively and quantitatively.
Efficient Light Field Reconstruction via Spatio-Angular Dense Network
Aug 08, 2021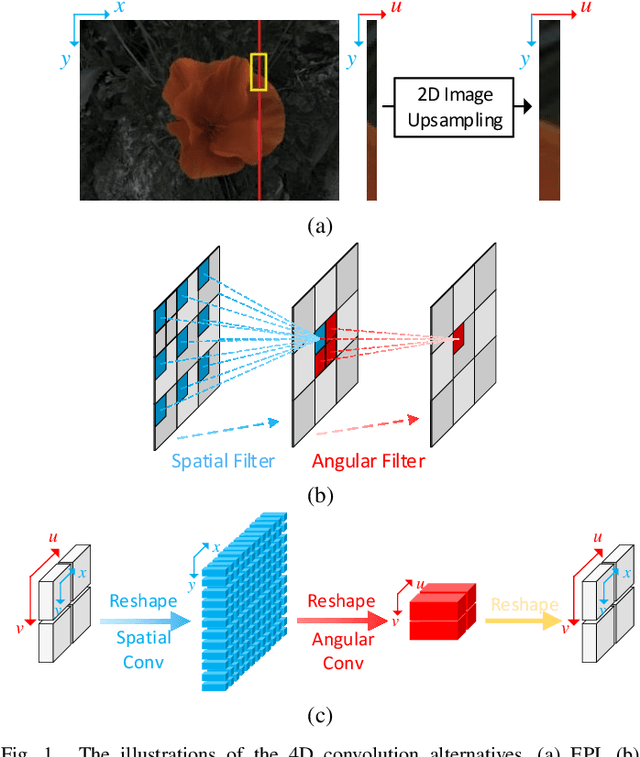
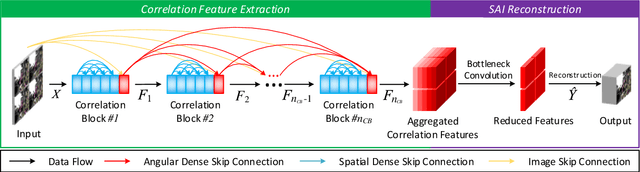
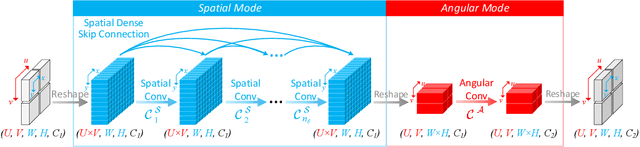

As an image sensing instrument, light field images can supply extra angular information compared with monocular images and have facilitated a wide range of measurement applications. Light field image capturing devices usually suffer from the inherent trade-off between the angular and spatial resolutions. To tackle this problem, several methods, such as light field reconstruction and light field super-resolution, have been proposed but leaving two problems unaddressed, namely domain asymmetry and efficient information flow. In this paper, we propose an end-to-end Spatio-Angular Dense Network (SADenseNet) for light field reconstruction with two novel components, namely correlation blocks and spatio-angular dense skip connections to address them. The former performs effective modeling of the correlation information in a way that conforms with the domain asymmetry. And the latter consists of three kinds of connections enhancing the information flow within two domains. Extensive experiments on both real-world and synthetic datasets have been conducted to demonstrate that the proposed SADenseNet's state-of-the-art performance at significantly reduced costs in memory and computation. The qualitative results show that the reconstructed light field images are sharp with correct details and can serve as pre-processing to improve the accuracy of related measurement applications.
Vision-Based Food Analysis for Automatic Dietary Assessment
Aug 06, 2021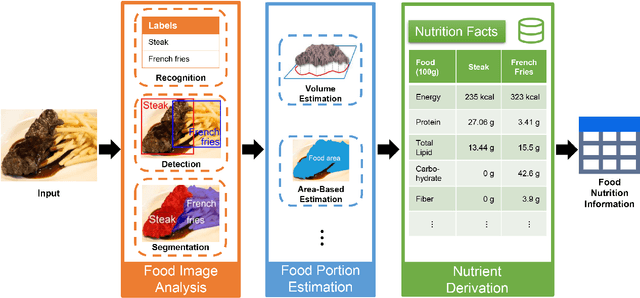

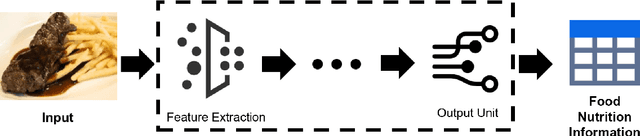
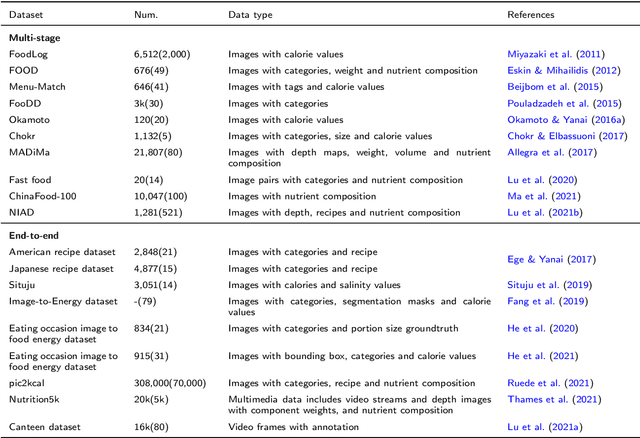
Background: Maintaining a healthy diet is vital to avoid health-related issues, e.g., undernutrition, obesity and many non-communicable diseases. An indispensable part of the health diet is dietary assessment. Traditional manual recording methods are burdensome and contain substantial biases and errors. Recent advances in Artificial Intelligence, especially computer vision technologies, have made it possible to develop automatic dietary assessment solutions, which are more convenient, less time-consuming and even more accurate to monitor daily food intake. Scope and approach: This review presents one unified Vision-Based Dietary Assessment (VBDA) framework, which generally consists of three stages: food image analysis, volume estimation and nutrient derivation. Vision-based food analysis methods, including food recognition, detection and segmentation, are systematically summarized, and methods of volume estimation and nutrient derivation are also given. The prosperity of deep learning makes VBDA gradually move to an end-to-end implementation, which applies food images to a single network to directly estimate the nutrition. The recently proposed end-to-end methods are also discussed. We further analyze existing dietary assessment datasets, indicating that one large-scale benchmark is urgently needed, and finally highlight key challenges and future trends for VBDA. Key findings and conclusions: After thorough exploration, we find that multi-task end-to-end deep learning approaches are one important trend of VBDA. Despite considerable research progress, many challenges remain for VBDA due to the meal complexity. We also provide the latest ideas for future development of VBDA, e.g., fine-grained food analysis and accurate volume estimation. This survey aims to encourage researchers to propose more practical solutions for VBDA.
Shape retrieval of non-rigid 3d human models
Mar 01, 2020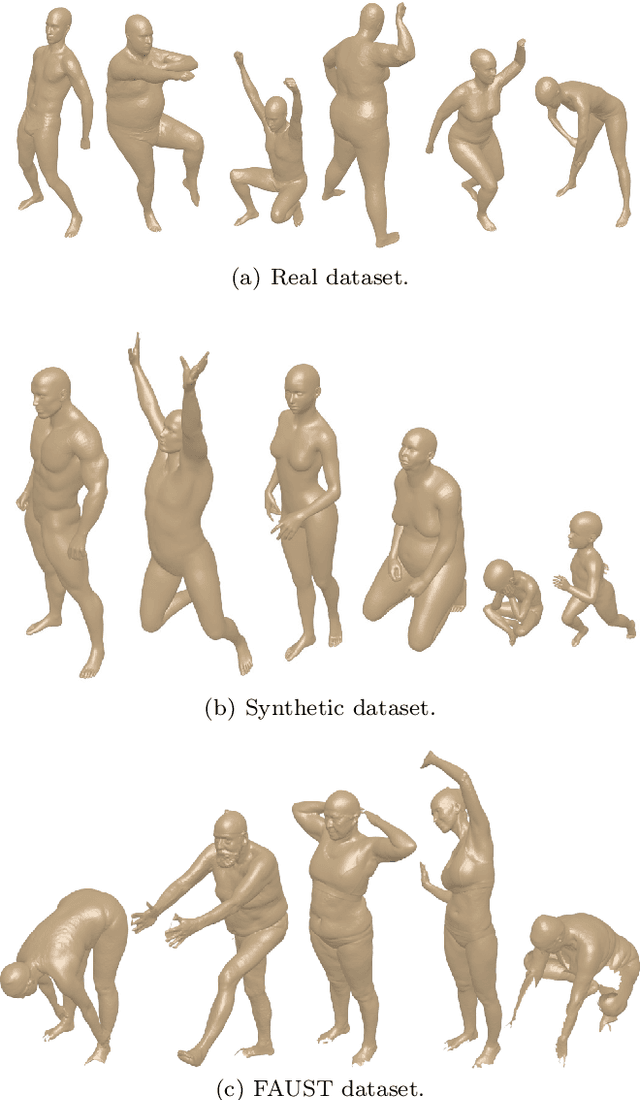
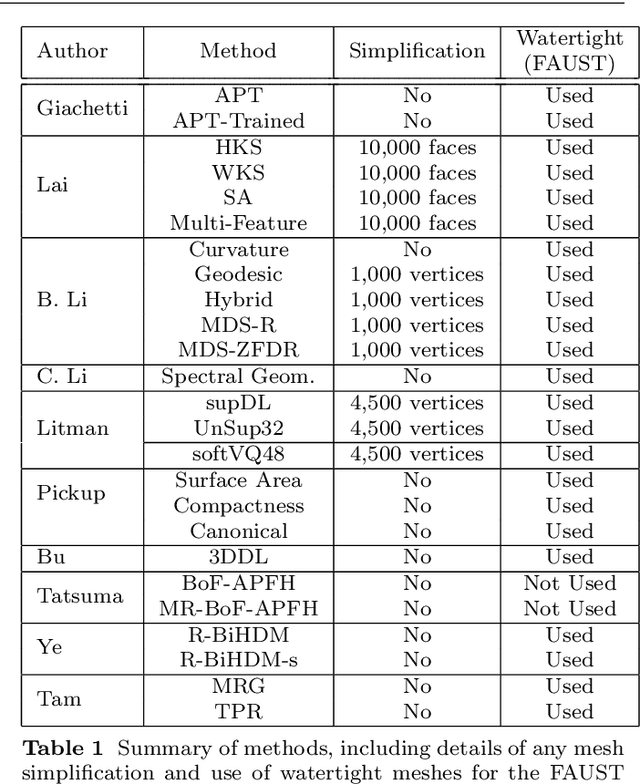
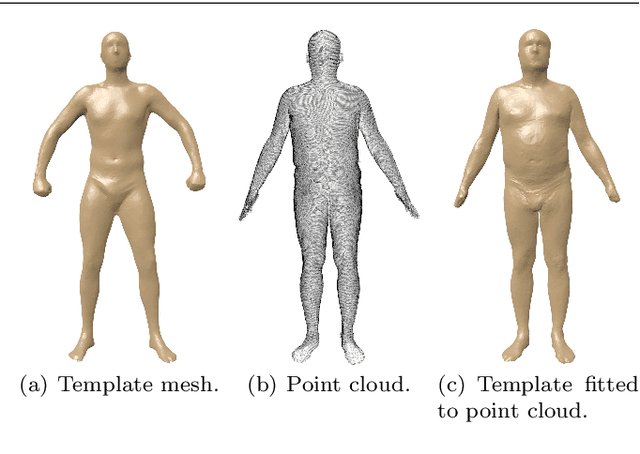
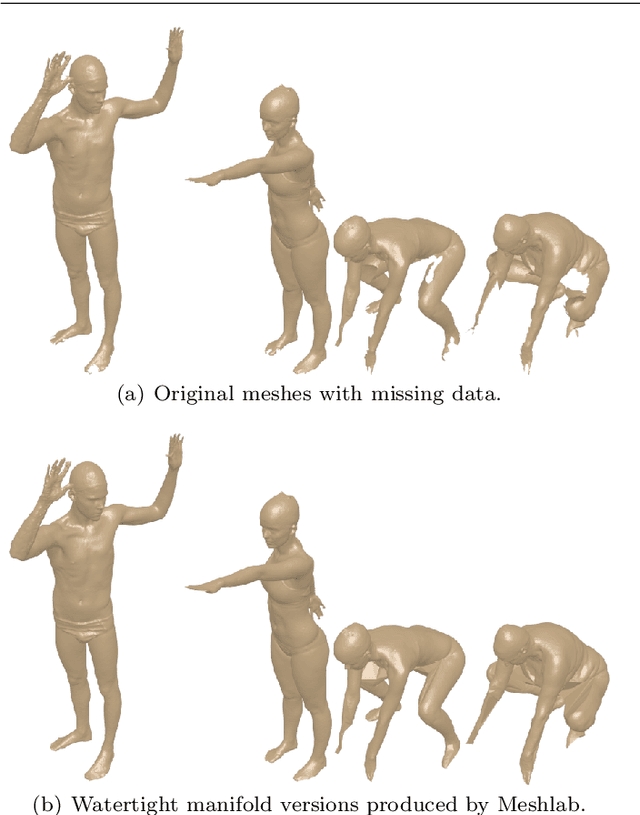
3D models of humans are commonly used within computer graphics and vision, and so the ability to distinguish between body shapes is an important shape retrieval problem. We extend our recent paper which provided a benchmark for testing non-rigid 3D shape retrieval algorithms on 3D human models. This benchmark provided a far stricter challenge than previous shape benchmarks. We have added 145 new models for use as a separate training set, in order to standardise the training data used and provide a fairer comparison. We have also included experiments with the FAUST dataset of human scans. All participants of the previous benchmark study have taken part in the new tests reported here, many providing updated results using the new data. In addition, further participants have also taken part, and we provide extra analysis of the retrieval results. A total of 25 different shape retrieval methods.
Explaining the Predictions of Any Image Classifier via Decision Trees
Nov 04, 2019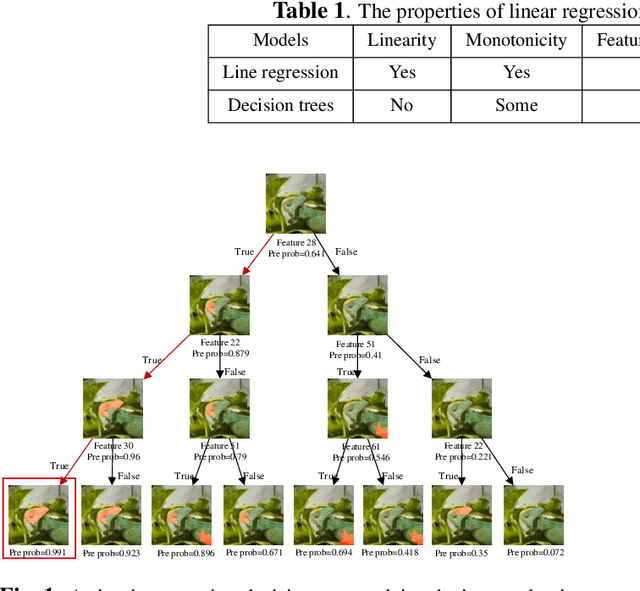
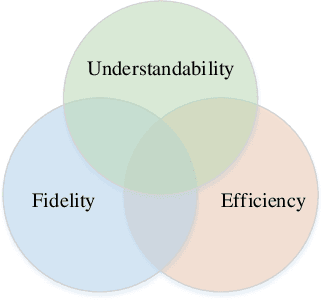


Despite outstanding contribution to the significant progress of Artificial Intelligence (AI), deep learning models remain mostly black boxes, which are extremely weak in explainability of the reasoning process and prediction results. Explainability is not only a gateway between AI and society but also a powerful tool to detect flaws in the model and biases in the data. Local Interpretable Model-agnostic Explanation (LIME) is a recent approach that uses a linear regression model to form a local explanation for the individual prediction result. However, being so restricted and usually oversimplifying the relationships, linear models fail in situations where nonlinear associations and interactions exist among features and prediction results. This paper proposes an extended Decision Tree-based LIME (TLIME) approach, which uses a decision tree model to form an interpretable representation that is locally faithful to the original model. The new approach can capture nonlinear interactions among features in the data and creates plausible explanations. Various experiments show that the TLIME explanation of multiple blackbox models can achieve more reliable performance in terms of understandability, fidelity, and efficiency.