 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Fine-Grained Geometry for Sparse-View Splatting via Cascade Depth Loss
May 28, 2025Novel view synthesis is a fundamental task in 3D computer vision that aims to reconstruct realistic images from a set of posed input views. However, reconstruction quality degrades significantly under sparse-view conditions due to limited geometric cues. Existing methods, such as Neural Radiance Fields (NeRF) and the more recent 3D Gaussian Splatting (3DGS), often suffer from blurred details and structural artifacts when trained with insufficient views. Recent works have identified the quality of rendered depth as a key factor in mitigating these artifacts, as it directly affects geometric accuracy and view consistency. In this paper, we address these challenges by introducing Hierarchical Depth-Guided Splatting (HDGS), a depth supervision framework that progressively refines geometry from coarse to fine levels. Central to HDGS is a novel Cascade Pearson Correlation Loss (CPCL), which aligns rendered and estimated monocular depths across multiple spatial scales. By enforcing multi-scale depth consistency, our method substantially improves structural fidelity in sparse-view scenarios. Extensive experiments on the LLFF and DTU benchmarks demonstrate that HDGS achieves state-of-the-art performance under sparse-view settings while maintaining efficient and high-quality rendering
NVS-SQA: Exploring Self-Supervised Quality Representation Learning for Neurally Synthesized Scenes without References
Jan 11, 2025



Neural View Synthesis (NVS), such as NeRF and 3D Gaussian Splatting, effectively creates photorealistic scenes from sparse viewpoints, typically evaluated by quality assessment methods like PSNR, SSIM, and LPIPS. However, these full-reference methods, which compare synthesized views to reference views, may not fully capture the perceptual quality of neurally synthesized scenes (NSS), particularly due to the limited availability of dense reference views. Furthermore, the challenges in acquiring human perceptual labels hinder the creation of extensive labeled datasets, risking model overfitting and reduced generalizability. To address these issues, we propose NVS-SQA, a NSS quality assessment method to learn no-reference quality representations through self-supervision without reliance on human labels. Traditional self-supervised learning predominantly relies on the "same instance, similar representation" assumption and extensive datasets. However, given that these conditions do not apply in NSS quality assessment, we employ heuristic cues and quality scores as learning objectives, along with a specialized contrastive pair preparation process to improve the effectiveness and efficiency of learning. The results show that NVS-SQA outperforms 17 no-reference methods by a large margin (i.e., on average 109.5% in SRCC, 98.6% in PLCC, and 91.5% in KRCC over the second best) and even exceeds 16 full-reference methods across all evaluation metrics (i.e., 22.9% in SRCC, 19.1% in PLCC, and 18.6% in KRCC over the second best).
NeRF-NQA: No-Reference Quality Assessment for Scenes Generated by NeRF and Neural View Synthesis Methods
Dec 11, 2024Neural View Synthesis (NVS) has demonstrated efficacy in generating high-fidelity dense viewpoint videos using a image set with sparse views. However, existing quality assessment methods like PSNR, SSIM, and LPIPS are not tailored for the scenes with dense viewpoints synthesized by NVS and NeRF variants, thus, they often fall short in capturing the perceptual quality, including spatial and angular aspects of NVS-synthesized scenes. Furthermore, the lack of dense ground truth views makes the full reference quality assessment on NVS-synthesized scenes challenging. For instance, datasets such as LLFF provide only sparse images, insufficient for complete full-reference assessments. To address the issues above, we propose NeRF-NQA, the first no-reference quality assessment method for densely-observed scenes synthesized from the NVS and NeRF variants. NeRF-NQA employs a joint quality assessment strategy, integrating both viewwise and pointwise approaches, to evaluate the quality of NVS-generated scenes. The viewwise approach assesses the spatial quality of each individual synthesized view and the overall inter-views consistency, while the pointwise approach focuses on the angular qualities of scene surface points and their compound inter-point quality. Extensive evaluations are conducted to compare NeRF-NQA with 23 mainstream visual quality assessment methods (from fields of image, video, and light-field assessment). The results demonstrate NeRF-NQA outperforms the existing assessment methods significantly and it shows substantial superiority on assessing NVS-synthesized scenes without references. An implementation of this paper are available at https://github.com/VincentQQu/NeRF-NQA.
EvRepSL: Event-Stream Representation via Self-Supervised Learning for Event-Based Vision
Dec 10, 2024



Event-stream representation is the first step for many computer vision tasks using event cameras. It converts the asynchronous event-streams into a formatted structure so that conventional machine learning models can be applied easily. However, most of the state-of-the-art event-stream representations are manually designed and the quality of these representations cannot be guaranteed due to the noisy nature of event-streams. In this paper, we introduce a data-driven approach aiming at enhancing the quality of event-stream representations. Our approach commences with the introduction of a new event-stream representation based on spatial-temporal statistics, denoted as EvRep. Subsequently, we theoretically derive the intrinsic relationship between asynchronous event-streams and synchronous video frames. Building upon this theoretical relationship, we train a representation generator, RepGen, in a self-supervised learning manner accepting EvRep as input. Finally, the event-streams are converted to high-quality representations, termed as EvRepSL, by going through the learned RepGen (without the need of fine-tuning or retraining). Our methodology is rigorously validated through extensive evaluations on a variety of mainstream event-based classification and optical flow datasets (captured with various types of event cameras). The experimental results highlight not only our approach's superior performance over existing event-stream representations but also its versatility, being agnostic to different event cameras and tasks.
* Published on IEEE Transactions on Image Processing
Beyond Gaussians: Fast and High-Fidelity 3D Splatting with Linear Kernels
Nov 20, 2024



Recent advancements in 3D Gaussian Splatting (3DGS) have substantially improved novel view synthesis, enabling high-quality reconstruction and real-time rendering. However, blurring artifacts, such as floating primitives and over-reconstruction, remain challenging. Current methods address these issues by refining scene structure, enhancing geometric representations, addressing blur in training images, improving rendering consistency, and optimizing density control, yet the role of kernel design remains underexplored. We identify the soft boundaries of Gaussian ellipsoids as one of the causes of these artifacts, limiting detail capture in high-frequency regions. To bridge this gap, we introduce 3D Linear Splatting (3DLS), which replaces Gaussian kernels with linear kernels to achieve sharper and more precise results, particularly in high-frequency regions. Through evaluations on three datasets, 3DLS demonstrates state-of-the-art fidelity and accuracy, along with a 30% FPS improvement over baseline 3DGS. The implementation will be made publicly available upon acceptance.
Efficient Multi-disparity Transformer for Light Field Image Super-resolution
Jul 22, 2024This paper presents the Multi-scale Disparity Transformer (MDT), a novel Transformer tailored for light field image super-resolution (LFSR) that addresses the issues of computational redundancy and disparity entanglement caused by the indiscriminate processing of sub-aperture images inherent in conventional methods. MDT features a multi-branch structure, with each branch utilising independent disparity self-attention (DSA) to target specific disparity ranges, effectively reducing computational complexity and disentangling disparities. Building on this architecture, we present LF-MDTNet, an efficient LFSR network. Experimental results demonstrate that LF-MDTNet outperforms existing state-of-the-art methods by 0.37 dB and 0.41 dB PSNR at the 2x and 4x scales, achieving superior performance with fewer parameters and higher speed.
E2HQV: High-Quality Video Generation from Event Camera via Theory-Inspired Model-Aided Deep Learning
Jan 16, 2024



The bio-inspired event cameras or dynamic vision sensors are capable of asynchronously capturing per-pixel brightness changes (called event-streams) in high temporal resolution and high dynamic range. However, the non-structural spatial-temporal event-streams make it challenging for providing intuitive visualization with rich semantic information for human vision. It calls for events-to-video (E2V) solutions which take event-streams as input and generate high quality video frames for intuitive visualization. However, current solutions are predominantly data-driven without considering the prior knowledge of the underlying statistics relating event-streams and video frames. It highly relies on the non-linearity and generalization capability of the deep neural networks, thus, is struggling on reconstructing detailed textures when the scenes are complex. In this work, we propose \textbf{E2HQV}, a novel E2V paradigm designed to produce high-quality video frames from events. This approach leverages a model-aided deep learning framework, underpinned by a theory-inspired E2V model, which is meticulously derived from the fundamental imaging principles of event cameras. To deal with the issue of state-reset in the recurrent components of E2HQV, we also design a temporal shift embedding module to further improve the quality of the video frames. Comprehensive evaluations on the real world event camera datasets validate our approach, with E2HQV, notably outperforming state-of-the-art approaches, e.g., surpassing the second best by over 40\% for some evaluation metrics.
LFACon: Introducing Anglewise Attention to No-Reference Quality Assessment in Light Field Space
Mar 20, 2023



Light field imaging can capture both the intensity information and the direction information of light rays. It naturally enables a six-degrees-of-freedom viewing experience and deep user engagement in virtual reality. Compared to 2D image assessment, light field image quality assessment (LFIQA) needs to consider not only the image quality in the spatial domain but also the quality consistency in the angular domain. However, there is a lack of metrics to effectively reflect the angular consistency and thus the angular quality of a light field image (LFI). Furthermore, the existing LFIQA metrics suffer from high computational costs due to the excessive data volume of LFIs. In this paper, we propose a novel concept of "anglewise attention" by introducing a multihead self-attention mechanism to the angular domain of an LFI. This mechanism better reflects the LFI quality. In particular, we propose three new attention kernels, including anglewise self-attention, anglewise grid attention, and anglewise central attention. These attention kernels can realize angular self-attention, extract multiangled features globally or selectively, and reduce the computational cost of feature extraction. By effectively incorporating the proposed kernels, we further propose our light field attentional convolutional neural network (LFACon) as an LFIQA metric. Our experimental results show that the proposed LFACon metric significantly outperforms the state-of-the-art LFIQA metrics. For the majority of distortion types, LFACon attains the best performance with lower complexity and less computational time.
Texture-enhanced Light Field Super-resolution with Spatio-Angular Decomposition Kernels
Nov 07, 2021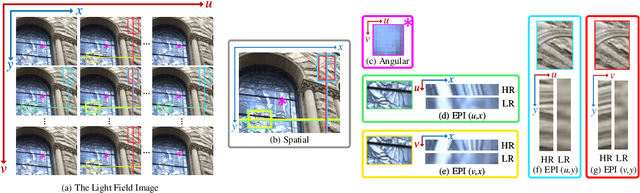
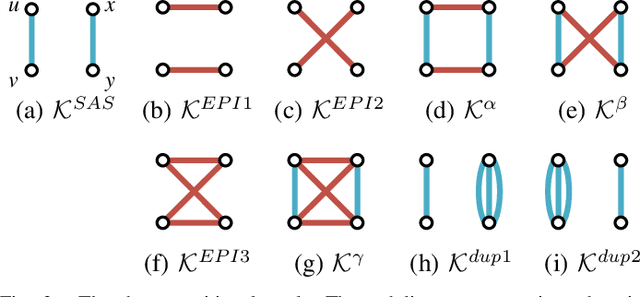
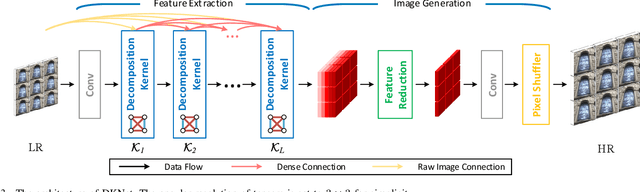

Despite the recent progress in light field super-resolution (LFSR) achieved by convolutional neural networks, the correlation information of light field (LF) images has not been sufficiently studied and exploited due to the complexity of 4D LF data. To cope with such high-dimensional LF data, most of the existing LFSR methods resorted to decomposing it into lower dimensions and subsequently performing optimization on the decomposed sub-spaces. However, these methods are inherently limited as they neglected the characteristics of the decomposition operations and only utilized a limited set of LF sub-spaces ending up failing to comprehensively extract spatio-angular features and leading to a performance bottleneck. To overcome these limitations, in this paper, we thoroughly discover the potentials of LF decomposition and propose a novel concept of decomposition kernels. In particular, we systematically unify the decomposition operations of various sub-spaces into a series of such decomposition kernels, which are incorporated into our proposed Decomposition Kernel Network (DKNet) for comprehensive spatio-angular feature extraction. The proposed DKNet is experimentally verified to achieve substantial improvements by 1.35 dB, 0.83 dB, and 1.80 dB PSNR in 2x, 3x and 4x LFSR scales, respectively, when compared with the state-of-the-art methods. To further improve DKNet in producing more visually pleasing LFSR results, based on the VGG network, we propose a LFVGG loss to guide the Texture-Enhanced DKNet (TE-DKNet) to generate rich authentic textures and enhance LF images' visual quality significantly. We also propose an indirect evaluation metric by taking advantage of LF material recognition to objectively assess the perceptual enhancement brought by the LFVGG loss.
Efficient Light Field Reconstruction via Spatio-Angular Dense Network
Aug 08, 2021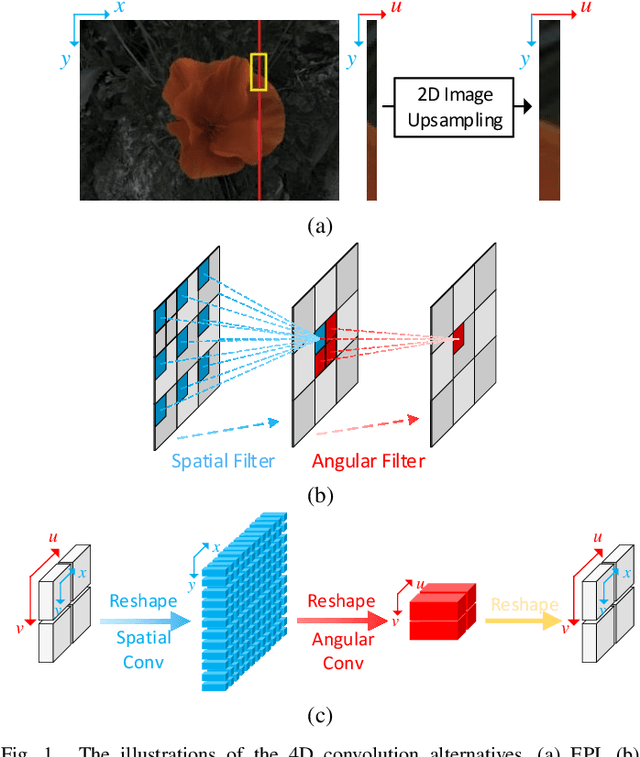
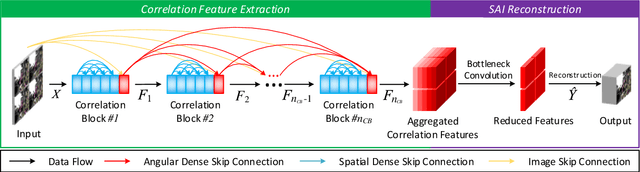
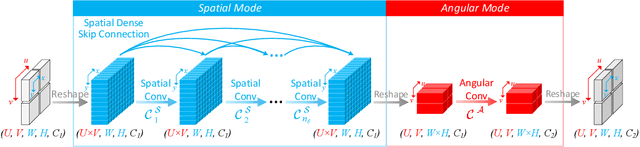

As an image sensing instrument, light field images can supply extra angular information compared with monocular images and have facilitated a wide range of measurement applications. Light field image capturing devices usually suffer from the inherent trade-off between the angular and spatial resolutions. To tackle this problem, several methods, such as light field reconstruction and light field super-resolution, have been proposed but leaving two problems unaddressed, namely domain asymmetry and efficient information flow. In this paper, we propose an end-to-end Spatio-Angular Dense Network (SADenseNet) for light field reconstruction with two novel components, namely correlation blocks and spatio-angular dense skip connections to address them. The former performs effective modeling of the correlation information in a way that conforms with the domain asymmetry. And the latter consists of three kinds of connections enhancing the information flow within two domains. Extensive experiments on both real-world and synthetic datasets have been conducted to demonstrate that the proposed SADenseNet's state-of-the-art performance at significantly reduced costs in memory and computation. The qualitative results show that the reconstructed light field images are sharp with correct details and can serve as pre-processing to improve the accuracy of related measurement applications.