 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePocket-Dentist: On-Device Dental Image Understanding via Efficient Multimodal Large Language Models
May 28, 2026Evaluations of dental vision-language models remain fragmented across datasets, task definitions and metrics, and often ignore their computational cost. This limits their widespread deployment for dental screening outside specialist centres, where timely inference, limited hardware, and local handling of patient images are vital for practical, privacy-preserving clinical prescreening. Here we present Pocket-Dentist, an efficiency-aware benchmark for dental multimodal question answering that brings together three datasets spanning approximately 1,159 patients, five task types and seven metrics. Across typical 14 VLMs, our results reveals an interesting observation: compact VLMs (e.g., 2B-parameter models) outperform larger VLMs in accuracy while requiring substantially lower computational costs in dental image understanding. Deployed locally on an iPhone 17 Pro, our finetuned compact VLM Pocket-Dentist-2B processed each sample in 4.31 s, reducing latency by 4.9-fold and memory use by 2.3-fold compared with a 7B baseline.
CreBench: Human-Aligned Creativity Evaluation from Idea to Process to Product
Nov 17, 2025Human-defined creativity is highly abstract, posing a challenge for multimodal large language models (MLLMs) to comprehend and assess creativity that aligns with human judgments. The absence of an existing benchmark further exacerbates this dilemma. To this end, we propose CreBench, which consists of two key components: 1) an evaluation benchmark covering the multiple dimensions from creative idea to process to products; 2) CreMIT (Creativity Multimodal Instruction Tuning dataset), a multimodal creativity evaluation dataset, consisting of 2.2K diverse-sourced multimodal data, 79.2K human feedbacks and 4.7M multi-typed instructions. Specifically, to ensure MLLMs can handle diverse creativity-related queries, we prompt GPT to refine these human feedbacks to activate stronger creativity assessment capabilities. CreBench serves as a foundation for building MLLMs that understand human-aligned creativity. Based on the CreBench, we fine-tune open-source general MLLMs, resulting in CreExpert, a multimodal creativity evaluation expert model. Extensive experiments demonstrate that the proposed CreExpert models achieve significantly better alignment with human creativity evaluation compared to state-of-the-art MLLMs, including the most advanced GPT-4V and Gemini-Pro-Vision.
Preference-Based Learning in Audio Applications: A Systematic Analysis
Nov 17, 2025



Despite the parallel challenges that audio and text domains face in evaluating generative model outputs, preference learning remains remarkably underexplored in audio applications. Through a PRISMA-guided systematic review of approximately 500 papers, we find that only 30 (6%) apply preference learning to audio tasks. Our analysis reveals a field in transition: pre-2021 works focused on emotion recognition using traditional ranking methods (rankSVM), while post-2021 studies have pivoted toward generation tasks employing modern RLHF frameworks. We identify three critical patterns: (1) the emergence of multi-dimensional evaluation strategies combining synthetic, automated, and human preferences; (2) inconsistent alignment between traditional metrics (WER, PESQ) and human judgments across different contexts; and (3) convergence on multi-stage training pipelines that combine reward signals. Our findings suggest that while preference learning shows promise for audio, particularly in capturing subjective qualities like naturalness and musicality, the field requires standardized benchmarks, higher-quality datasets, and systematic investigation of how temporal factors unique to audio impact preference learning frameworks.
In-context Ranking Preference Optimization
Apr 21, 2025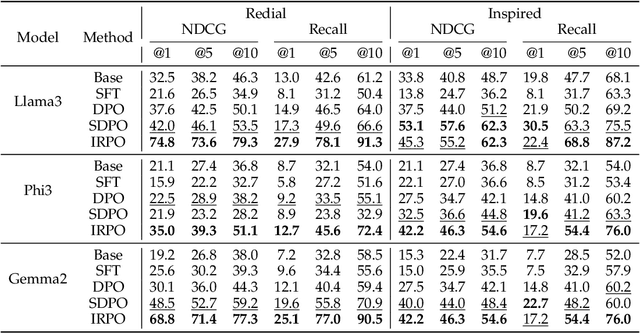
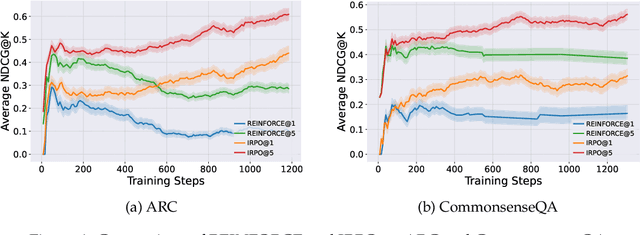
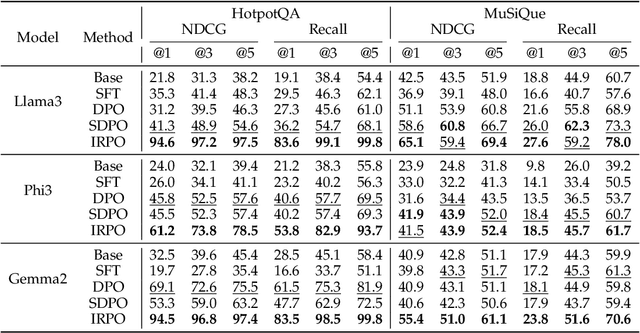
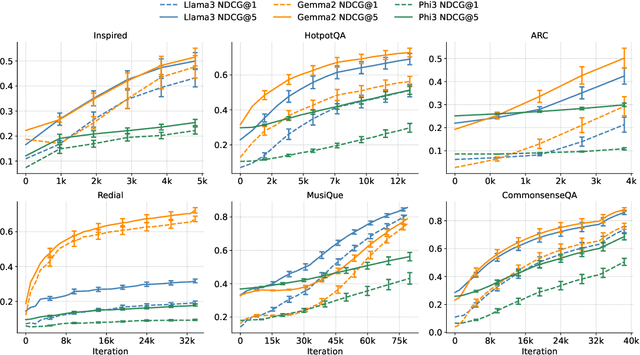
Recent developments in Direct Preference Optimization (DPO) allow large language models (LLMs) to function as implicit ranking models by maximizing the margin between preferred and non-preferred responses. In practice, user feedback on such lists typically involves identifying a few relevant items in context rather than providing detailed pairwise comparisons for every possible item pair. Moreover, many complex information retrieval tasks, such as conversational agents and summarization systems, critically depend on ranking the highest-quality outputs at the top, emphasizing the need to support natural and flexible forms of user feedback. To address the challenge of limited and sparse pairwise feedback in the in-context setting, we propose an In-context Ranking Preference Optimization (IRPO) framework that directly optimizes LLMs based on ranking lists constructed during inference. To further capture flexible forms of feedback, IRPO extends the DPO objective by incorporating both the relevance of items and their positions in the list. Modeling these aspects jointly is non-trivial, as ranking metrics are inherently discrete and non-differentiable, making direct optimization difficult. To overcome this, IRPO introduces a differentiable objective based on positional aggregation of pairwise item preferences, enabling effective gradient-based optimization of discrete ranking metrics. We further provide theoretical insights showing that IRPO (i) automatically emphasizes items with greater disagreement between the model and the reference ranking, and (ii) links its gradient to an importance sampling estimator, yielding an unbiased estimator with reduced variance. Empirical results show IRPO outperforms standard DPO approaches in ranking performance, highlighting its effectiveness in aligning LLMs with direct in-context ranking preferences.
A Survey on Personalized and Pluralistic Preference Alignment in Large Language Models
Apr 09, 2025Personalized preference alignment for large language models (LLMs), the process of tailoring LLMs to individual users' preferences, is an emerging research direction spanning the area of NLP and personalization. In this survey, we present an analysis of works on personalized alignment and modeling for LLMs. We introduce a taxonomy of preference alignment techniques, including training time, inference time, and additionally, user-modeling based methods. We provide analysis and discussion on the strengths and limitations of each group of techniques and then cover evaluation, benchmarks, as well as open problems in the field.
Ev-Layout: A Large-scale Event-based Multi-modal Dataset for Indoor Layout Estimation and Tracking
Mar 11, 2025This paper presents Ev-Layout, a novel large-scale event-based multi-modal dataset designed for indoor layout estimation and tracking. Ev-Layout makes key contributions to the community by: Utilizing a hybrid data collection platform (with a head-mounted display and VR interface) that integrates both RGB and bio-inspired event cameras to capture indoor layouts in motion. Incorporating time-series data from inertial measurement units (IMUs) and ambient lighting conditions recorded during data collection to highlight the potential impact of motion speed and lighting on layout estimation accuracy. The dataset consists of 2.5K sequences, including over 771.3K RGB images and 10 billion event data points. Of these, 39K images are annotated with indoor layouts, enabling research in both event-based and video-based indoor layout estimation. Based on the dataset, we propose an event-based layout estimation pipeline with a novel event-temporal distribution feature module to effectively aggregate the spatio-temporal information from events. Additionally, we introduce a spatio-temporal feature fusion module that can be easily integrated into a transformer module for fusion purposes. Finally, we conduct benchmarking and extensive experiments on the Ev-Layout dataset, demonstrating that our approach significantly improves the accuracy of dynamic indoor layout estimation compared to existing event-based methods.
NVS-SQA: Exploring Self-Supervised Quality Representation Learning for Neurally Synthesized Scenes without References
Jan 11, 2025



Neural View Synthesis (NVS), such as NeRF and 3D Gaussian Splatting, effectively creates photorealistic scenes from sparse viewpoints, typically evaluated by quality assessment methods like PSNR, SSIM, and LPIPS. However, these full-reference methods, which compare synthesized views to reference views, may not fully capture the perceptual quality of neurally synthesized scenes (NSS), particularly due to the limited availability of dense reference views. Furthermore, the challenges in acquiring human perceptual labels hinder the creation of extensive labeled datasets, risking model overfitting and reduced generalizability. To address these issues, we propose NVS-SQA, a NSS quality assessment method to learn no-reference quality representations through self-supervision without reliance on human labels. Traditional self-supervised learning predominantly relies on the "same instance, similar representation" assumption and extensive datasets. However, given that these conditions do not apply in NSS quality assessment, we employ heuristic cues and quality scores as learning objectives, along with a specialized contrastive pair preparation process to improve the effectiveness and efficiency of learning. The results show that NVS-SQA outperforms 17 no-reference methods by a large margin (i.e., on average 109.5% in SRCC, 98.6% in PLCC, and 91.5% in KRCC over the second best) and even exceeds 16 full-reference methods across all evaluation metrics (i.e., 22.9% in SRCC, 19.1% in PLCC, and 18.6% in KRCC over the second best).
NeRF-NQA: No-Reference Quality Assessment for Scenes Generated by NeRF and Neural View Synthesis Methods
Dec 11, 2024Neural View Synthesis (NVS) has demonstrated efficacy in generating high-fidelity dense viewpoint videos using a image set with sparse views. However, existing quality assessment methods like PSNR, SSIM, and LPIPS are not tailored for the scenes with dense viewpoints synthesized by NVS and NeRF variants, thus, they often fall short in capturing the perceptual quality, including spatial and angular aspects of NVS-synthesized scenes. Furthermore, the lack of dense ground truth views makes the full reference quality assessment on NVS-synthesized scenes challenging. For instance, datasets such as LLFF provide only sparse images, insufficient for complete full-reference assessments. To address the issues above, we propose NeRF-NQA, the first no-reference quality assessment method for densely-observed scenes synthesized from the NVS and NeRF variants. NeRF-NQA employs a joint quality assessment strategy, integrating both viewwise and pointwise approaches, to evaluate the quality of NVS-generated scenes. The viewwise approach assesses the spatial quality of each individual synthesized view and the overall inter-views consistency, while the pointwise approach focuses on the angular qualities of scene surface points and their compound inter-point quality. Extensive evaluations are conducted to compare NeRF-NQA with 23 mainstream visual quality assessment methods (from fields of image, video, and light-field assessment). The results demonstrate NeRF-NQA outperforms the existing assessment methods significantly and it shows substantial superiority on assessing NVS-synthesized scenes without references. An implementation of this paper are available at https://github.com/VincentQQu/NeRF-NQA.
EvRepSL: Event-Stream Representation via Self-Supervised Learning for Event-Based Vision
Dec 10, 2024



Event-stream representation is the first step for many computer vision tasks using event cameras. It converts the asynchronous event-streams into a formatted structure so that conventional machine learning models can be applied easily. However, most of the state-of-the-art event-stream representations are manually designed and the quality of these representations cannot be guaranteed due to the noisy nature of event-streams. In this paper, we introduce a data-driven approach aiming at enhancing the quality of event-stream representations. Our approach commences with the introduction of a new event-stream representation based on spatial-temporal statistics, denoted as EvRep. Subsequently, we theoretically derive the intrinsic relationship between asynchronous event-streams and synchronous video frames. Building upon this theoretical relationship, we train a representation generator, RepGen, in a self-supervised learning manner accepting EvRep as input. Finally, the event-streams are converted to high-quality representations, termed as EvRepSL, by going through the learned RepGen (without the need of fine-tuning or retraining). Our methodology is rigorously validated through extensive evaluations on a variety of mainstream event-based classification and optical flow datasets (captured with various types of event cameras). The experimental results highlight not only our approach's superior performance over existing event-stream representations but also its versatility, being agnostic to different event cameras and tasks.
* Published on IEEE Transactions on Image Processing
PDSR: A Privacy-Preserving Diversified Service Recommendation Method on Distributed Data
Aug 28, 2024



The last decade has witnessed a tremendous growth of service computing, while efficient service recommendation methods are desired to recommend high-quality services to users. It is well known that collaborative filtering is one of the most popular methods for service recommendation based on QoS, and many existing proposals focus on improving recommendation accuracy, i.e., recommending high-quality redundant services. Nevertheless, users may have different requirements on QoS, and hence diversified recommendation has been attracting increasing attention in recent years to fulfill users' diverse demands and to explore potential services. Unfortunately, the recommendation performances relies on a large volume of data (e.g., QoS data), whereas the data may be distributed across multiple platforms. Therefore, to enable data sharing across the different platforms for diversified service recommendation, we propose a Privacy-preserving Diversified Service Recommendation (PDSR) method. Specifically, we innovate in leveraging the Locality-Sensitive Hashing (LSH) mechanism such that privacy-preserved data sharing across different platforms is enabled to construct a service similarity graph. Based on the similarity graph, we propose a novel accuracy-diversity metric and design a $2$-approximation algorithm to select $K$ services to recommend by maximizing the accuracy-diversity measure. Extensive experiments on real datasets are conducted to verify the efficacy of our PDSR method.