 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSLIM-Brain: A Data- and Training-Efficient Foundation Model for fMRI Data Analysis
Dec 26, 2025Foundation models are emerging as a powerful paradigm for fMRI analysis, but current approaches face a dual bottleneck of data- and training-efficiency. Atlas-based methods aggregate voxel signals into fixed regions of interest, reducing data dimensionality but discarding fine-grained spatial details, and requiring extremely large cohorts to train effectively as general-purpose foundation models. Atlas-free methods, on the other hand, operate directly on voxel-level information - preserving spatial fidelity but are prohibitively memory- and compute-intensive, making large-scale pre-training infeasible. We introduce SLIM-Brain (Sample-efficient, Low-memory fMRI Foundation Model for Human Brain), a new atlas-free foundation model that simultaneously improves both data- and training-efficiency. SLIM-Brain adopts a two-stage adaptive design: (i) a lightweight temporal extractor captures global context across full sequences and ranks data windows by saliency, and (ii) a 4D hierarchical encoder (Hiera-JEPA) learns fine-grained voxel-level representations only from the top-$k$ selected windows, while deleting about 70% masked patches. Extensive experiments across seven public benchmarks show that SLIM-Brain establishes new state-of-the-art performance on diverse tasks, while requiring only 4 thousand pre-training sessions and approximately 30% of GPU memory comparing to traditional voxel-level methods.
AIReg-Bench: Benchmarking Language Models That Assess AI Regulation Compliance
Oct 01, 2025As governments move to regulate AI, there is growing interest in using Large Language Models (LLMs) to assess whether or not an AI system complies with a given AI Regulation (AIR). However, there is presently no way to benchmark the performance of LLMs at this task. To fill this void, we introduce AIReg-Bench: the first benchmark dataset designed to test how well LLMs can assess compliance with the EU AI Act (AIA). We created this dataset through a two-step process: (1) by prompting an LLM with carefully structured instructions, we generated 120 technical documentation excerpts (samples), each depicting a fictional, albeit plausible, AI system - of the kind an AI provider might produce to demonstrate their compliance with AIR; (2) legal experts then reviewed and annotated each sample to indicate whether, and in what way, the AI system described therein violates specific Articles of the AIA. The resulting dataset, together with our evaluation of whether frontier LLMs can reproduce the experts' compliance labels, provides a starting point to understand the opportunities and limitations of LLM-based AIR compliance assessment tools and establishes a benchmark against which subsequent LLMs can be compared. The dataset and evaluation code are available at https://github.com/camlsys/aireg-bench.
HiLight: A Hierarchical Reinforcement Learning Framework with Global Adversarial Guidance for Large-Scale Traffic Signal Control
Jun 17, 2025Efficient traffic signal control (TSC) is essential for mitigating urban congestion, yet existing reinforcement learning (RL) methods face challenges in scaling to large networks while maintaining global coordination. Centralized RL suffers from scalability issues, while decentralized approaches often lack unified objectives, resulting in limited network-level efficiency. In this paper, we propose HiLight, a hierarchical reinforcement learning framework with global adversarial guidance for large-scale TSC. HiLight consists of a high-level Meta-Policy, which partitions the traffic network into subregions and generates sub-goals using a Transformer-LSTM architecture, and a low-level Sub-Policy, which controls individual intersections with global awareness. To improve the alignment between global planning and local execution, we introduce an adversarial training mechanism, where the Meta-Policy generates challenging yet informative sub-goals, and the Sub-Policy learns to surpass these targets, leading to more effective coordination. We evaluate HiLight across both synthetic and real-world benchmarks, and additionally construct a large-scale Manhattan network with diverse traffic conditions, including peak transitions, adverse weather, and holiday surges. Experimental results show that HiLight exhibits significant advantages in large-scale scenarios and remains competitive across standard benchmarks of varying sizes.
MixSignGraph: A Sign Sequence is Worth Mixed Graphs of Nodes
Apr 16, 2025Recent advances in sign language research have benefited from CNN-based backbones, which are primarily transferred from traditional computer vision tasks (\eg object identification, image recognition). However, these CNN-based backbones usually excel at extracting features like contours and texture, but may struggle with capturing sign-related features. In fact, sign language tasks require focusing on sign-related regions, including the collaboration between different regions (\eg left hand region and right hand region) and the effective content in a single region. To capture such region-related features, we introduce MixSignGraph, which represents sign sequences as a group of mixed graphs and designs the following three graph modules for feature extraction, \ie Local Sign Graph (LSG) module, Temporal Sign Graph (TSG) module and Hierarchical Sign Graph (HSG) module. Specifically, the LSG module learns the correlation of intra-frame cross-region features within one frame, \ie focusing on spatial features. The TSG module tracks the interaction of inter-frame cross-region features among adjacent frames, \ie focusing on temporal features. The HSG module aggregates the same-region features from different-granularity feature maps of a frame, \ie focusing on hierarchical features. In addition, to further improve the performance of sign language tasks without gloss annotations, we propose a simple yet counter-intuitive Text-driven CTC Pre-training (TCP) method, which generates pseudo gloss labels from text labels for model pre-training. Extensive experiments conducted on current five public sign language datasets demonstrate the superior performance of the proposed model. Notably, our model surpasses the SOTA models on multiple sign language tasks across several datasets, without relying on any additional cues.
No More Adam: Learning Rate Scaling at Initialization is All You Need
Dec 17, 2024In this work, we question the necessity of adaptive gradient methods for training deep neural networks. SGD-SaI is a simple yet effective enhancement to stochastic gradient descent with momentum (SGDM). SGD-SaI performs learning rate Scaling at Initialization (SaI) to distinct parameter groups, guided by their respective gradient signal-to-noise ratios (g-SNR). By adjusting learning rates without relying on adaptive second-order momentum, SGD-SaI helps prevent training imbalances from the very first iteration and cuts the optimizer's memory usage by half compared to AdamW. Despite its simplicity and efficiency, SGD-SaI consistently matches or outperforms AdamW in training a variety of Transformer-based tasks, effectively overcoming a long-standing challenge of using SGD for training Transformers. SGD-SaI excels in ImageNet-1K classification with Vision Transformers(ViT) and GPT-2 pretraining for large language models (LLMs, transformer decoder-only), demonstrating robustness to hyperparameter variations and practicality for diverse applications. We further tested its robustness on tasks like LoRA fine-tuning for LLMs and diffusion models, where it consistently outperforms state-of-the-art optimizers. From a memory efficiency perspective, SGD-SaI achieves substantial memory savings for optimizer states, reducing memory usage by 5.93 GB for GPT-2 (1.5B parameters) and 25.15 GB for Llama2-7B compared to AdamW in full-precision training settings.
Federated Learning for Traffic Flow Prediction with Synthetic Data Augmentation
Dec 11, 2024



Deep-learning based traffic prediction models require vast amounts of data to learn embedded spatial and temporal dependencies. The inherent privacy and commercial sensitivity of such data has encouraged a shift towards decentralised data-driven methods, such as Federated Learning (FL). Under a traditional Machine Learning paradigm, traffic flow prediction models can capture spatial and temporal relationships within centralised data. In reality, traffic data is likely distributed across separate data silos owned by multiple stakeholders. In this work, a cross-silo FL setting is motivated to facilitate stakeholder collaboration for optimal traffic flow prediction applications. This work introduces an FL framework, referred to as FedTPS, to generate synthetic data to augment each client's local dataset by training a diffusion-based trajectory generation model through FL. The proposed framework is evaluated on a large-scale real world ride-sharing dataset using various FL methods and Traffic Flow Prediction models, including a novel prediction model we introduce, which leverages Temporal and Graph Attention mechanisms to learn the Spatio-Temporal dependencies embedded within regional traffic flow data. Experimental results show that FedTPS outperforms multiple other FL baselines with respect to global model performance.
AdaFlow: Opportunistic Inference on Asynchronous Mobile Data with Generalized Affinity Control
Oct 31, 2024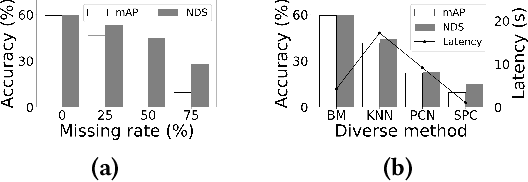


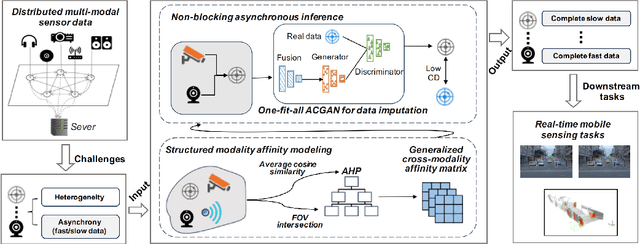
The rise of mobile devices equipped with numerous sensors, such as LiDAR and cameras, has spurred the adoption of multi-modal deep intelligence for distributed sensing tasks, such as smart cabins and driving assistance. However, the arrival times of mobile sensory data vary due to modality size and network dynamics, which can lead to delays (if waiting for slower data) or accuracy decline (if inference proceeds without waiting). Moreover, the diversity and dynamic nature of mobile systems exacerbate this challenge. In response, we present a shift to \textit{opportunistic} inference for asynchronous distributed multi-modal data, enabling inference as soon as partial data arrives. While existing methods focus on optimizing modality consistency and complementarity, known as modal affinity, they lack a \textit{computational} approach to control this affinity in open-world mobile environments. AdaFlow pioneers the formulation of structured cross-modality affinity in mobile contexts using a hierarchical analysis-based normalized matrix. This approach accommodates the diversity and dynamics of modalities, generalizing across different types and numbers of inputs. Employing an affinity attention-based conditional GAN (ACGAN), AdaFlow facilitates flexible data imputation, adapting to various modalities and downstream tasks without retraining. Experiments show that AdaFlow significantly reduces inference latency by up to 79.9\% and enhances accuracy by up to 61.9\%, outperforming status quo approaches.
TrajWeaver: Trajectory Recovery with State Propagation Diffusion Model
Sep 01, 2024



With the proliferation of location-aware devices, large amount of trajectories have been generated when agents such as people, vehicles and goods flow around the urban environment. These raw trajectories, typically collected from various sources such as GPS in cars, personal mobile devices, and public transport, are often sparse and fragmented due to limited sampling rates, infrastructure coverage and data loss. In this context, trajectory recovery aims to reconstruct such sparse raw trajectories into their dense and continuous counterparts, so that fine-grained movement of agents across space and time can be captured faithfully. Existing trajectory recovery approaches typically rely on the prior knowledge of travel mode or motion patterns, and often fail in densely populated urban areas where accurate maps are absent. In this paper, we present a new recovery framework called TrajWeaver based on probabilistic diffusion models, which is able to recover dense and refined trajectories from the sparse raw ones, conditioned on various auxiliary features such as Areas of Interest along the way, user identity and waybill information. The core of TrajWeaver is a novel State Propagation Diffusion Model (SPDM), which introduces a new state propagation mechanism on top of the standard diffusion models, so that knowledge computed in earlier diffusion steps can be reused later, improving the recovery performance while reducing the number of steps needed. Extensive experiments show that the proposed TrajWeaver can recover from raw trajectories of various lengths, sparsity levels and heterogeneous travel modes, and outperform the state-of-the-art baselines significantly in recovery accuracy. Our code is available at: https://anonymous.4open.science/r/TrajWeaver/
Fast Inference Through The Reuse Of Attention Maps In Diffusion Models
Dec 13, 2023



Text-to-image diffusion models have demonstrated unprecedented abilities at flexible and realistic image synthesis. However, the iterative process required to produce a single image is costly and incurs a high latency, prompting researchers to further investigate its efficiency. Typically, improvements in latency have been achieved in two ways: (1) training smaller models through knowledge distillation (KD); and (2) adopting techniques from ODE-theory to facilitate larger step sizes. In contrast, we propose a training-free approach that does not alter the step-size of the sampler. Specifically, we find the repeated calculation of attention maps to be both costly and redundant; therefore, we propose a structured reuse of attention maps during sampling. Our initial reuse policy is motivated by rudimentary ODE-theory, which suggests that reuse is most suitable late in the sampling procedure. After noting a number of limitations in this theoretical approach, we empirically search for a better policy. Unlike methods that rely on KD, our reuse policies can easily be adapted to a variety of setups in a plug-and-play manner. Furthermore, when applied to Stable Diffusion-1.5, our reuse policies reduce latency with minimal repercussions on sample quality.
How Much Is Hidden in the NAS Benchmarks? Few-Shot Adaptation of a NAS Predictor
Nov 30, 2023
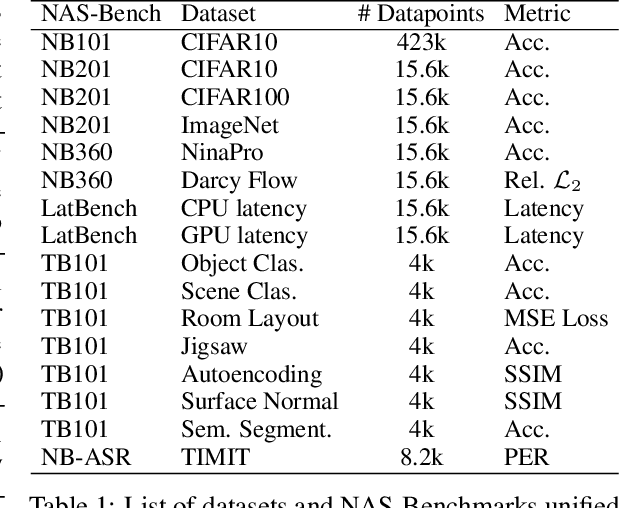
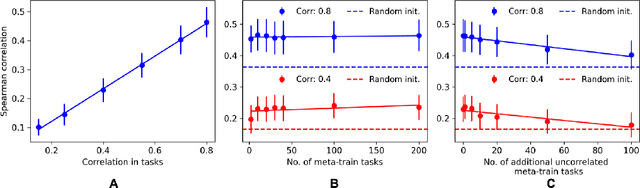
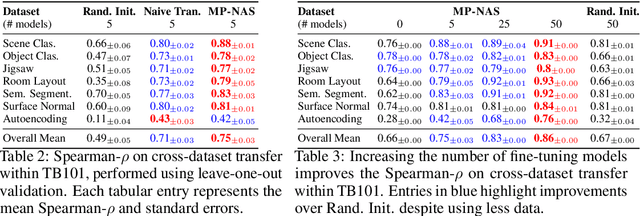
Neural architecture search has proven to be a powerful approach to designing and refining neural networks, often boosting their performance and efficiency over manually-designed variations, but comes with computational overhead. While there has been a considerable amount of research focused on lowering the cost of NAS for mainstream tasks, such as image classification, a lot of those improvements stem from the fact that those tasks are well-studied in the broader context. Consequently, applicability of NAS to emerging and under-represented domains is still associated with a relatively high cost and/or uncertainty about the achievable gains. To address this issue, we turn our focus towards the recent growth of publicly available NAS benchmarks in an attempt to extract general NAS knowledge, transferable across different tasks and search spaces. We borrow from the rich field of meta-learning for few-shot adaptation and carefully study applicability of those methods to NAS, with a special focus on the relationship between task-level correlation (domain shift) and predictor transferability; which we deem critical for improving NAS on diverse tasks. In our experiments, we use 6 NAS benchmarks in conjunction, spanning in total 16 NAS settings -- our meta-learning approach not only shows superior (or matching) performance in the cross-validation experiments but also successful extrapolation to a new search space and tasks.