 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNo More Adam: Learning Rate Scaling at Initialization is All You Need
Dec 17, 2024



In this work, we question the necessity of adaptive gradient methods for training deep neural networks. SGD-SaI is a simple yet effective enhancement to stochastic gradient descent with momentum (SGDM). SGD-SaI performs learning rate Scaling at Initialization (SaI) to distinct parameter groups, guided by their respective gradient signal-to-noise ratios (g-SNR). By adjusting learning rates without relying on adaptive second-order momentum, SGD-SaI helps prevent training imbalances from the very first iteration and cuts the optimizer's memory usage by half compared to AdamW. Despite its simplicity and efficiency, SGD-SaI consistently matches or outperforms AdamW in training a variety of Transformer-based tasks, effectively overcoming a long-standing challenge of using SGD for training Transformers. SGD-SaI excels in ImageNet-1K classification with Vision Transformers(ViT) and GPT-2 pretraining for large language models (LLMs, transformer decoder-only), demonstrating robustness to hyperparameter variations and practicality for diverse applications. We further tested its robustness on tasks like LoRA fine-tuning for LLMs and diffusion models, where it consistently outperforms state-of-the-art optimizers. From a memory efficiency perspective, SGD-SaI achieves substantial memory savings for optimizer states, reducing memory usage by 5.93 GB for GPT-2 (1.5B parameters) and 25.15 GB for Llama2-7B compared to AdamW in full-precision training settings.
Temporal Kernel Consistency for Blind Video Super-Resolution
Aug 18, 2021
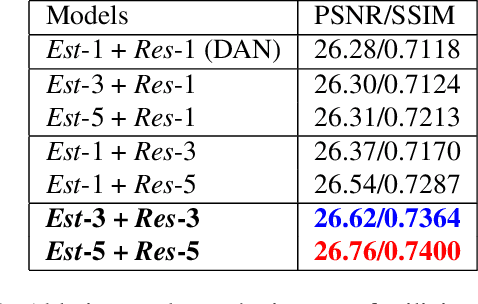

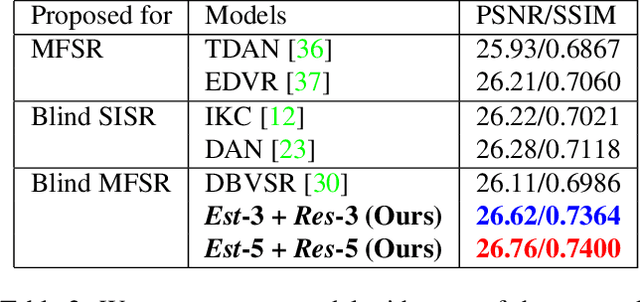
Deep learning-based blind super-resolution (SR) methods have recently achieved unprecedented performance in upscaling frames with unknown degradation. These models are able to accurately estimate the unknown downscaling kernel from a given low-resolution (LR) image in order to leverage the kernel during restoration. Although these approaches have largely been successful, they are predominantly image-based and therefore do not exploit the temporal properties of the kernels across multiple video frames. In this paper, we investigated the temporal properties of the kernels and highlighted its importance in the task of blind video super-resolution. Specifically, we measured the kernel temporal consistency of real-world videos and illustrated how the estimated kernels might change per frame in videos of varying dynamicity of the scene and its objects. With this new insight, we revisited previous popular video SR approaches, and showed that previous assumptions of using a fixed kernel throughout the restoration process can lead to visual artifacts when upscaling real-world videos. In order to counteract this, we tailored existing single-image and video SR techniques to leverage kernel consistency during both kernel estimation and video upscaling processes. Extensive experiments on synthetic and real-world videos show substantial restoration gains quantitatively and qualitatively, achieving the new state-of-the-art in blind video SR and underlining the potential of exploiting kernel temporal consistency.
Zero-Cost Proxies Meet Differentiable Architecture Search
Jun 12, 2021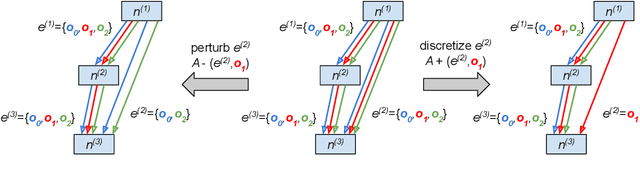

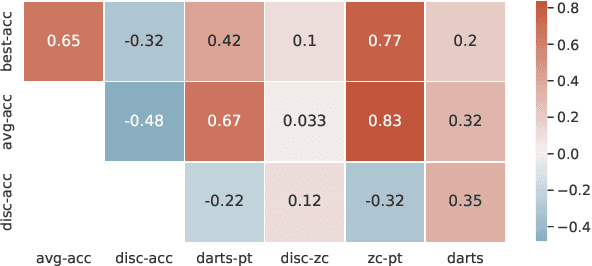

Differentiable neural architecture search (NAS) has attracted significant attention in recent years due to its ability to quickly discover promising architectures of deep neural networks even in very large search spaces. Despite its success, DARTS lacks robustness in certain cases, e.g. it may degenerate to trivial architectures with excessive parametric-free operations such as skip connection or random noise, leading to inferior performance. In particular, operation selection based on the magnitude of architectural parameters was recently proven to be fundamentally wrong showcasing the need to rethink this aspect. On the other hand, zero-cost proxies have been recently studied in the context of sample-based NAS showing promising results -- speeding up the search process drastically in some cases but also failing on some of the large search spaces typical for differentiable NAS. In this work we propose a novel operation selection paradigm in the context of differentiable NAS which utilises zero-cost proxies. Our perturbation-based zero-cost operation selection (Zero-Cost-PT) improves searching time and, in many cases, accuracy compared to the best available differentiable architecture search, regardless of the search space size. Specifically, we are able to find comparable architectures to DARTS-PT on the DARTS CNN search space while being over 40x faster (total searching time 25 minutes on a single GPU).