 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptable Butterfly Accelerator for Attention-based NNs via Hardware and Algorithm Co-design
Sep 20, 2022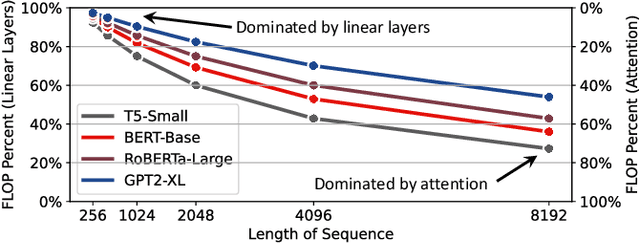
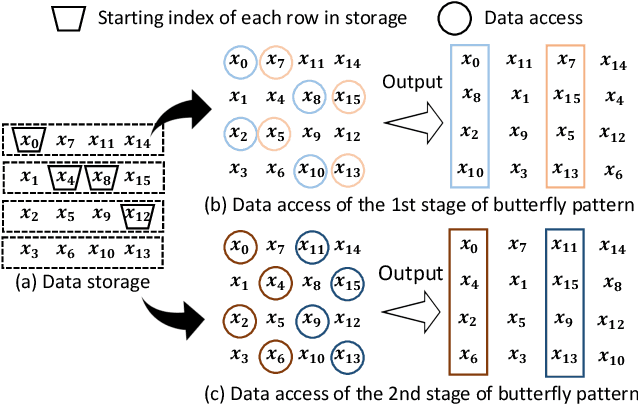
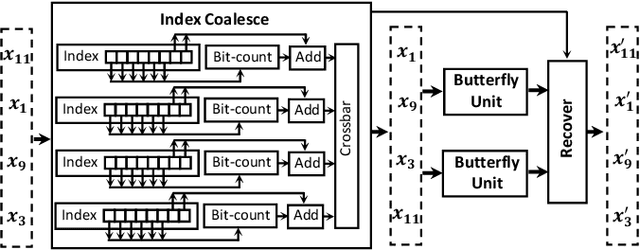
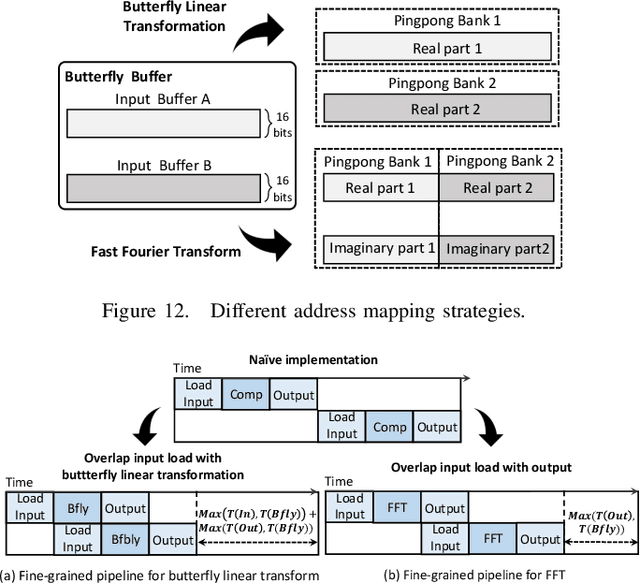
Attention-based neural networks have become pervasive in many AI tasks. Despite their excellent algorithmic performance, the use of the attention mechanism and feed-forward network (FFN) demands excessive computational and memory resources, which often compromises their hardware performance. Although various sparse variants have been introduced, most approaches only focus on mitigating the quadratic scaling of attention on the algorithm level, without explicitly considering the efficiency of mapping their methods on real hardware designs. Furthermore, most efforts only focus on either the attention mechanism or the FFNs but without jointly optimizing both parts, causing most of the current designs to lack scalability when dealing with different input lengths. This paper systematically considers the sparsity patterns in different variants from a hardware perspective. On the algorithmic level, we propose FABNet, a hardware-friendly variant that adopts a unified butterfly sparsity pattern to approximate both the attention mechanism and the FFNs. On the hardware level, a novel adaptable butterfly accelerator is proposed that can be configured at runtime via dedicated hardware control to accelerate different butterfly layers using a single unified hardware engine. On the Long-Range-Arena dataset, FABNet achieves the same accuracy as the vanilla Transformer while reducing the amount of computation by 10 to 66 times and the number of parameters 2 to 22 times. By jointly optimizing the algorithm and hardware, our FPGA-based butterfly accelerator achieves 14.2 to 23.2 times speedup over state-of-the-art accelerators normalized to the same computational budget. Compared with optimized CPU and GPU designs on Raspberry Pi 4 and Jetson Nano, our system is up to 273.8 and 15.1 times faster under the same power budget.
Zero-Cost Proxies Meet Differentiable Architecture Search
Jun 12, 2021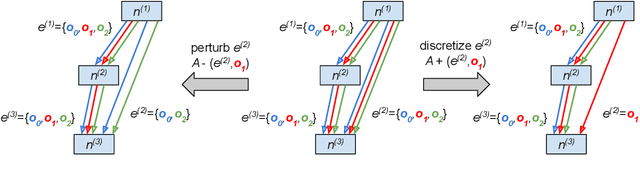


Differentiable neural architecture search (NAS) has attracted significant attention in recent years due to its ability to quickly discover promising architectures of deep neural networks even in very large search spaces. Despite its success, DARTS lacks robustness in certain cases, e.g. it may degenerate to trivial architectures with excessive parametric-free operations such as skip connection or random noise, leading to inferior performance. In particular, operation selection based on the magnitude of architectural parameters was recently proven to be fundamentally wrong showcasing the need to rethink this aspect. On the other hand, zero-cost proxies have been recently studied in the context of sample-based NAS showing promising results -- speeding up the search process drastically in some cases but also failing on some of the large search spaces typical for differentiable NAS. In this work we propose a novel operation selection paradigm in the context of differentiable NAS which utilises zero-cost proxies. Our perturbation-based zero-cost operation selection (Zero-Cost-PT) improves searching time and, in many cases, accuracy compared to the best available differentiable architecture search, regardless of the search space size. Specifically, we are able to find comparable architectures to DARTS-PT on the DARTS CNN search space while being over 40x faster (total searching time 25 minutes on a single GPU).
BRP-NAS: Prediction-based NAS using GCNs
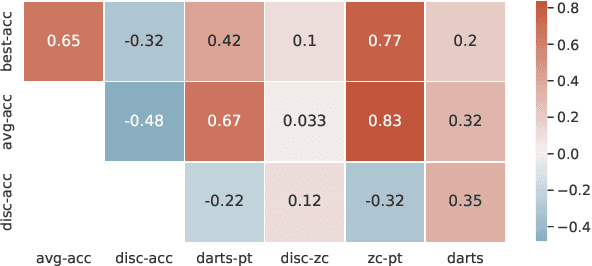
Aug 10, 2020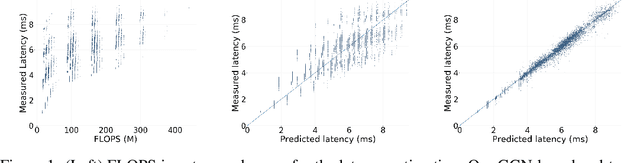

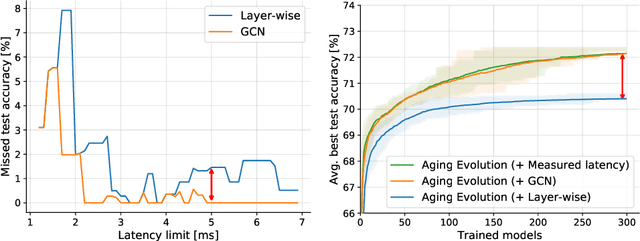
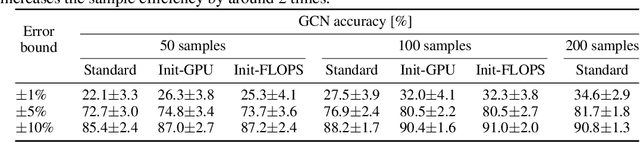
Neural architecture search (NAS) enables researchers to automatically explore broad design spaces in order to improve efficiency of neural networks. This efficiency is especially important in the case of on-device deployment, where improvements in accuracy should be balanced out with computational demands of a model. In practice, performance metrics of model are computationally expensive to obtain. Previous work uses a proxy (e.g. number of operations) or a layer-wise measurement of neural network layers to estimate end-to-end hardware performance but the imprecise prediction diminishes the quality of NAS. To address this problem, we propose BRP-NAS, an efficient hardware-aware NAS enabled by an accurate performance predictor-based on graph convolutional network (GCN). What is more, we investigate prediction quality on different metrics and show that sample-efficiency of the predictor-based NAS can be improved by considering binary relations of models and an iterative data selection strategy. We show that our proposed method outperforms all prior methods on both NAS-Bench-101 and NAS-Bench-201. Finally, to raise awareness of the fact that accurate latency estimation is not a trivial task, we release LatBench - a latency dataset of NAS-Bench-201 models running on a broad range of devices.
Best of Both Worlds: AutoML Codesign of a CNN and its Hardware Accelerator
Mar 06, 2020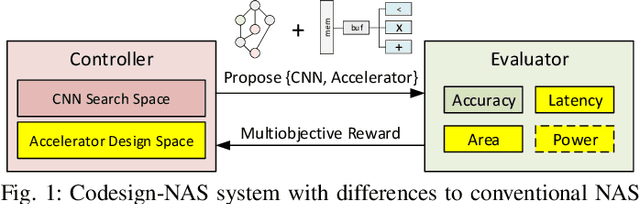
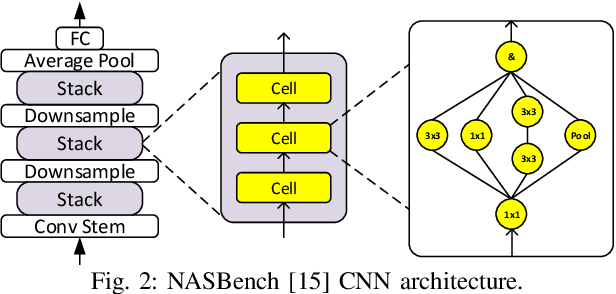
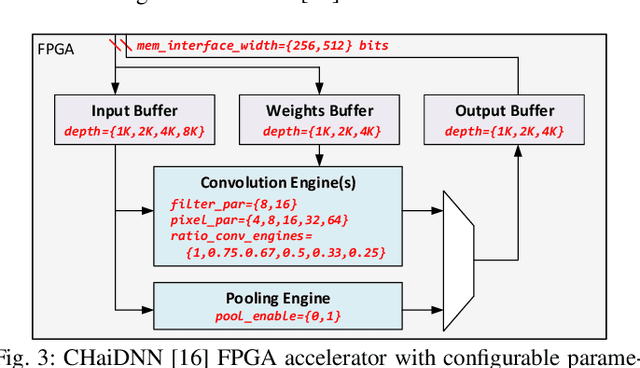
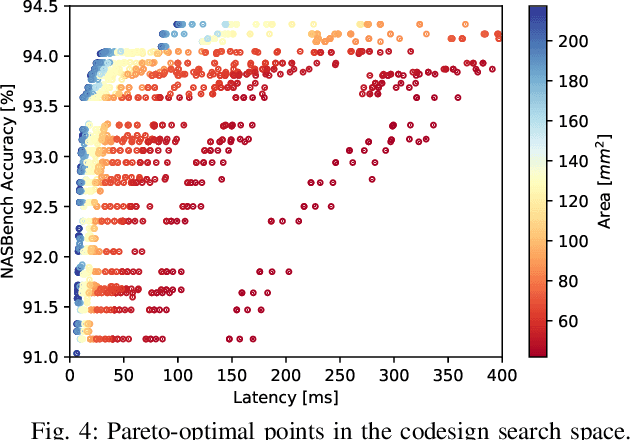
Neural architecture search (NAS) has been very successful at outperforming human-designed convolutional neural networks (CNN) in accuracy, and when hardware information is present, latency as well. However, NAS-designed CNNs typically have a complicated topology, therefore, it may be difficult to design a custom hardware (HW) accelerator for such CNNs. We automate HW-CNN codesign using NAS by including parameters from both the CNN model and the HW accelerator, and we jointly search for the best model-accelerator pair that boosts accuracy and efficiency. We call this Codesign-NAS. In this paper we focus on defining the Codesign-NAS multiobjective optimization problem, demonstrating its effectiveness, and exploring different ways of navigating the codesign search space. For CIFAR-10 image classification, we enumerate close to 4 billion model-accelerator pairs, and find the Pareto frontier within that large search space. This allows us to evaluate three different reinforcement-learning-based search strategies. Finally, compared to ResNet on its most optimal HW accelerator from within our HW design space, we improve on CIFAR-100 classification accuracy by 1.3% while simultaneously increasing performance/area by 41% in just~1000 GPU-hours of running Codesign-NAS.