 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Label Test-Time Adaptation with Bayesian Conditional Priors
Jun 11, 2026Multi-label recognition with frozen Vision-Language Models (VLMs) is brittle under distribution shift: standard zero-shot inference scores labels independently, ignoring co-occurrence structure and producing incoherent label sets where dominant concepts suppress weaker but compatible labels. We introduce Bayesian Conditional Priors (BCP) Estimation, a gradient-free test-time adaptation method that injects label dependency without tuning the backbone. BCP views zero-shot logits as a proxy for marginal posteriors under a fixed image-text likelihood and attributes shift-induced errors mainly to a mismatched label prior. For each test image, it selects a high-confidence anchor label and applies an anchor-conditioned Bayesian refinement. This update is closed-form in logit space and admits a pointwise mutual information (PMI) interpretation, explicitly promoting compatible labels and suppressing incompatible ones. BCP operates without target annotations by estimating anchor-conditioned priors online from the unlabeled test stream via lightweight second-order co-occurrence statistics, adding negligible overhead beyond a single forward pass. Across standard multi-label benchmarks and multiple CLIP backbones, BCP consistently outperforms strong TTA baselines, e.g., improving RN50 average mAP from 57.31 to 69.22 and ViT-B/16 from 62.61 to 71.79.
InfoMerge: Information-aware Token Compression for Efficient Video Large Language Models
Jun 01, 2026Video Large Language Models (Video-LLMs) achieve strong performance in video understanding, but their excessive visual tokens bring substantial computational overhead. Existing training-free compression methods improve inference efficiency by reducing visual tokens, yet they often rely on local adjacent-frame similarity for temporal redundancy estimation or allocate token budgets mainly according to segment length. Such designs are sensitive to frame-level noise and fail to capture the non-uniform information distribution of real-world videos. To address these challenges, we propose InfoMerge, a training-free visual token compression method that improves token utilization through robust redundancy estimation and content-aware budget allocation. Specifically, we propose the Temporal Fingerprint Difference: a segment-level second-order temporal redundancy estimation strategy, which models the temporal similarity structure of tokens at the same spatial positions within each segment. We further introduce Content-Aware Budget Allocation (CABA), which dynamically allocates segment-level token budgets based on segment uniqueness and spectral-entropy-based representational richness. By reducing repeated preservation of redundant static regions and allocating more tokens to informative segments, InfoMerge makes better use of the limited token budget while maintaining strong performance. Extensive experiments show that InfoMerge achieves strong efficiency--accuracy trade-offs across multiple benchmarks and backbones, with more pronounced advantages under aggressive compression. On LLaVA-OneVision-7B, InfoMerge retains 98.8\% of the original average performance while reducing 85\% of visual tokens and achieving a 4.24-fold speedup in the prefill stage.
RegionMarker: A Region-Triggered Semantic Watermarking Framework for Embedding-as-a-Service Copyright Protection
Nov 17, 2025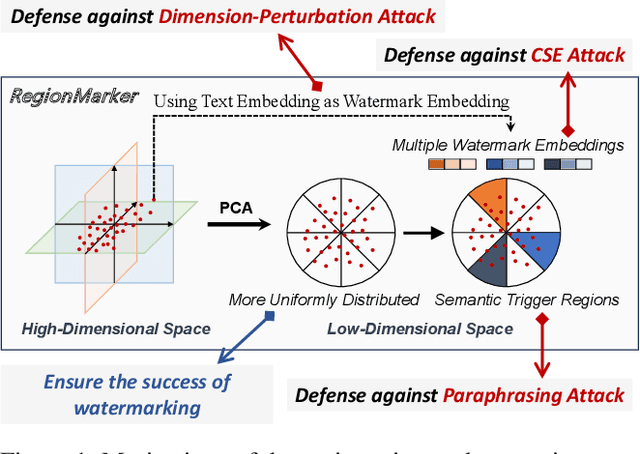

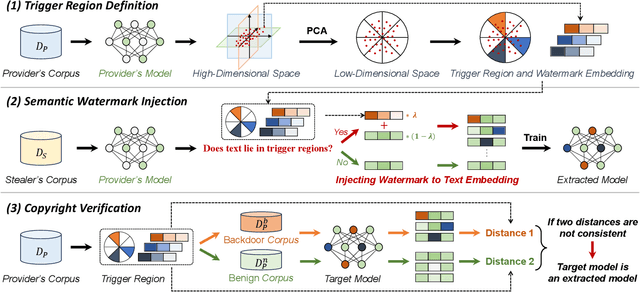
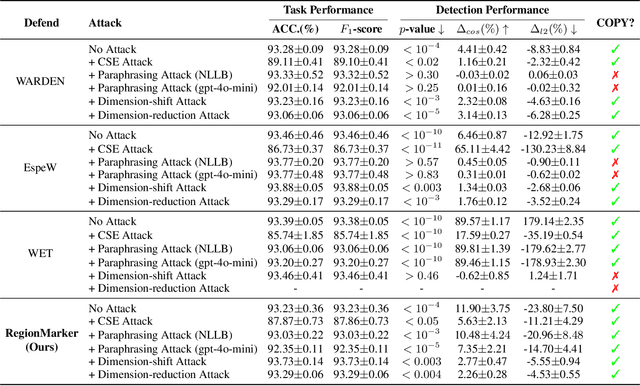
Embedding-as-a-Service (EaaS) is an effective and convenient deployment solution for addressing various NLP tasks. Nevertheless, recent research has shown that EaaS is vulnerable to model extraction attacks, which could lead to significant economic losses for model providers. For copyright protection, existing methods inject watermark embeddings into text embeddings and use them to detect copyright infringement. However, current watermarking methods often resist only a subset of attacks and fail to provide \textit{comprehensive} protection. To this end, we present the region-triggered semantic watermarking framework called RegionMarker, which defines trigger regions within a low-dimensional space and injects watermarks into text embeddings associated with these regions. By utilizing a secret dimensionality reduction matrix to project onto this subspace and randomly selecting trigger regions, RegionMarker makes it difficult for watermark removal attacks to evade detection. Furthermore, by embedding watermarks across the entire trigger region and using the text embedding as the watermark, RegionMarker is resilient to both paraphrasing and dimension-perturbation attacks. Extensive experiments on various datasets show that RegionMarker is effective in resisting different attack methods, thereby protecting the copyright of EaaS.
Steering When Necessary: Flexible Steering Large Language Models with Backtracking
Aug 25, 2025Large language models (LLMs) have achieved remarkable performance across many generation tasks. Nevertheless, effectively aligning them with desired behaviors remains a significant challenge. Activation steering is an effective and cost-efficient approach that directly modifies the activations of LLMs during the inference stage, aligning their responses with the desired behaviors and avoiding the high cost of fine-tuning. Existing methods typically indiscriminately intervene to all generations or rely solely on the question to determine intervention, which limits the accurate assessment of the intervention strength. To this end, we propose the Flexible Activation Steering with Backtracking (FASB) framework, which dynamically determines both the necessity and strength of intervention by tracking the internal states of the LLMs during generation, considering both the question and the generated content. Since intervening after detecting a deviation from the desired behavior is often too late, we further propose the backtracking mechanism to correct the deviated tokens and steer the LLMs toward the desired behavior. Extensive experiments on the TruthfulQA dataset and six multiple-choice datasets demonstrate that our method outperforms baselines. Our code will be released at https://github.com/gjw185/FASB.
Aligning LLM with human travel choices: a persona-based embedding learning approach
May 25, 2025



The advent of large language models (LLMs) presents new opportunities for travel demand modeling. However, behavioral misalignment between LLMs and humans presents obstacles for the usage of LLMs, and existing alignment methods are frequently inefficient or impractical given the constraints of typical travel demand data. This paper introduces a novel framework for aligning LLMs with human travel choice behavior, tailored to the current travel demand data sources. Our framework uses a persona inference and loading process to condition LLMs with suitable prompts to enhance alignment. The inference step establishes a set of base personas from empirical data, and a learned persona loading function driven by behavioral embeddings guides the loading process. We validate our framework on the Swissmetro mode choice dataset, and the results show that our proposed approach significantly outperformed baseline choice models and LLM-based simulation models in predicting both aggregate mode choice shares and individual choice outcomes. Furthermore, we showcase that our framework can generate insights on population behavior through interpretable parameters. Overall, our research offers a more adaptable, interpretable, and resource-efficient pathway to robust LLM-based travel behavior simulation, paving the way to integrate LLMs into travel demand modeling practice in the future.
Contrastive Prompting Enhances Sentence Embeddings in LLMs through Inference-Time Steering
May 19, 2025Extracting sentence embeddings from large language models (LLMs) is a practical direction, as it requires neither additional data nor fine-tuning. Previous studies usually focus on prompt engineering to guide LLMs to encode the core semantic information of the sentence into the embedding of the last token. However, the last token in these methods still encodes an excess of non-essential information, such as stop words, limiting its encoding capacity. To this end, we propose a Contrastive Prompting (CP) method that introduces an extra auxiliary prompt to elicit better sentence embedding. By contrasting with the auxiliary prompt, CP can steer existing prompts to encode the core semantics of the sentence, rather than non-essential information. CP is a plug-and-play inference-time intervention method that can be combined with various prompt-based methods. Extensive experiments on Semantic Textual Similarity (STS) tasks and downstream classification tasks demonstrate that our method can improve the performance of existing prompt-based methods across different LLMs. Our code will be released at https://github.com/zifengcheng/CP.
MixSignGraph: A Sign Sequence is Worth Mixed Graphs of Nodes
Apr 16, 2025Recent advances in sign language research have benefited from CNN-based backbones, which are primarily transferred from traditional computer vision tasks (\eg object identification, image recognition). However, these CNN-based backbones usually excel at extracting features like contours and texture, but may struggle with capturing sign-related features. In fact, sign language tasks require focusing on sign-related regions, including the collaboration between different regions (\eg left hand region and right hand region) and the effective content in a single region. To capture such region-related features, we introduce MixSignGraph, which represents sign sequences as a group of mixed graphs and designs the following three graph modules for feature extraction, \ie Local Sign Graph (LSG) module, Temporal Sign Graph (TSG) module and Hierarchical Sign Graph (HSG) module. Specifically, the LSG module learns the correlation of intra-frame cross-region features within one frame, \ie focusing on spatial features. The TSG module tracks the interaction of inter-frame cross-region features among adjacent frames, \ie focusing on temporal features. The HSG module aggregates the same-region features from different-granularity feature maps of a frame, \ie focusing on hierarchical features. In addition, to further improve the performance of sign language tasks without gloss annotations, we propose a simple yet counter-intuitive Text-driven CTC Pre-training (TCP) method, which generates pseudo gloss labels from text labels for model pre-training. Extensive experiments conducted on current five public sign language datasets demonstrate the superior performance of the proposed model. Notably, our model surpasses the SOTA models on multiple sign language tasks across several datasets, without relying on any additional cues.
Implicit Location-Caption Alignment via Complementary Masking for Weakly-Supervised Dense Video Captioning
Dec 17, 2024



Weakly-Supervised Dense Video Captioning (WSDVC) aims to localize and describe all events of interest in a video without requiring annotations of event boundaries. This setting poses a great challenge in accurately locating the temporal location of event, as the relevant supervision is unavailable. Existing methods rely on explicit alignment constraints between event locations and captions, which involve complex event proposal procedures during both training and inference. To tackle this problem, we propose a novel implicit location-caption alignment paradigm by complementary masking, which simplifies the complex event proposal and localization process while maintaining effectiveness. Specifically, our model comprises two components: a dual-mode video captioning module and a mask generation module. The dual-mode video captioning module captures global event information and generates descriptive captions, while the mask generation module generates differentiable positive and negative masks for localizing the events. These masks enable the implicit alignment of event locations and captions by ensuring that captions generated from positively and negatively masked videos are complementary, thereby forming a complete video description. In this way, even under weak supervision, the event location and event caption can be aligned implicitly. Extensive experiments on the public datasets demonstrate that our method outperforms existing weakly-supervised methods and achieves competitive results compared to fully-supervised methods.
Token Prepending: A Training-Free Approach for Eliciting Better Sentence Embeddings from LLMs
Dec 16, 2024Extracting sentence embeddings from large language models (LLMs) is a promising direction, as LLMs have demonstrated stronger semantic understanding capabilities. Previous studies typically focus on prompt engineering to elicit sentence embeddings from LLMs by prompting the model to encode sentence information into the embedding of the last token. However, LLMs are mostly decoder-only models with causal attention and the earlier tokens in the sentence cannot attend to the latter tokens, resulting in biased encoding of sentence information and cascading effects on the final decoded token. To this end, we propose a novel Token Prepending (TP) technique that prepends each layer's decoded sentence embedding to the beginning of the sentence in the next layer's input, allowing earlier tokens to attend to the complete sentence information under the causal attention mechanism. The proposed TP technique is a plug-and-play and training-free technique, which means it can be seamlessly integrated with various prompt-based sentence embedding methods and autoregressive LLMs. Extensive experiments on various Semantic Textual Similarity (STS) tasks and downstream classification tasks demonstrate that our proposed TP technique can significantly improve the performance of existing prompt-based sentence embedding methods across different LLMs, while incurring negligible additional inference cost.
Toward LLM-Agent-Based Modeling of Transportation Systems: A Conceptual Framework
Dec 09, 2024In transportation system demand modeling and simulation, agent-based models and microsimulations are current state-of-the-art approaches. However, existing agent-based models still have some limitations on behavioral realism and resource demand that limit their applicability. In this study, leveraging the emerging technology of large language models (LLMs) and LLM-based agents, we propose a general LLM-agent-based modeling framework for transportation systems. We argue that LLM agents not only possess the essential capabilities to function as agents but also offer promising solutions to overcome some limitations of existing agent-based models. Our conceptual framework design closely replicates the decision-making and interaction processes and traits of human travelers within transportation networks, and we demonstrate that the proposed systems can meet critical behavioral criteria for decision-making and learning behaviors using related studies and a demonstrative example of LLM agents' learning and adjustment in the bottleneck setting. Although further refinement of the LLM-agent-based modeling framework is necessary, we believe that this approach has the potential to improve transportation system modeling and simulation.