 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing Scientific General Intelligence of LLMs with Scientist-Aligned Workflows
Dec 18, 2025Despite advances in scientific AI, a coherent framework for Scientific General Intelligence (SGI)-the ability to autonomously conceive, investigate, and reason across scientific domains-remains lacking. We present an operational SGI definition grounded in the Practical Inquiry Model (PIM: Deliberation, Conception, Action, Perception) and operationalize it via four scientist-aligned tasks: deep research, idea generation, dry/wet experiments, and experimental reasoning. SGI-Bench comprises over 1,000 expert-curated, cross-disciplinary samples inspired by Science's 125 Big Questions, enabling systematic evaluation of state-of-the-art LLMs. Results reveal gaps: low exact match (10--20%) in deep research despite step-level alignment; ideas lacking feasibility and detail; high code executability but low execution result accuracy in dry experiments; low sequence fidelity in wet protocols; and persistent multimodal comparative-reasoning challenges. We further introduce Test-Time Reinforcement Learning (TTRL), which optimizes retrieval-augmented novelty rewards at inference, enhancing hypothesis novelty without reference answer. Together, our PIM-grounded definition, workflow-centric benchmark, and empirical insights establish a foundation for AI systems that genuinely participate in scientific discovery.
RegionMarker: A Region-Triggered Semantic Watermarking Framework for Embedding-as-a-Service Copyright Protection
Nov 17, 2025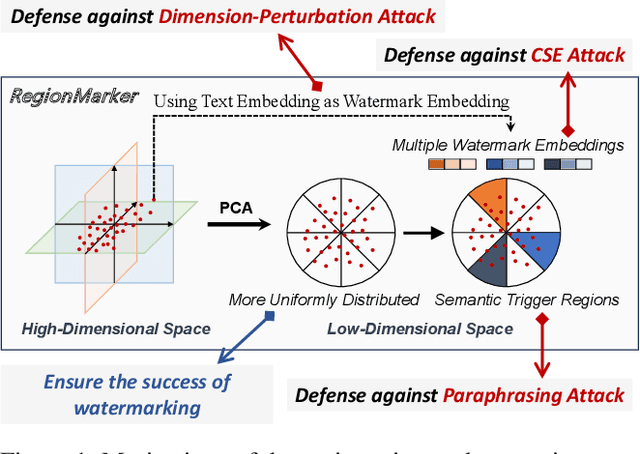

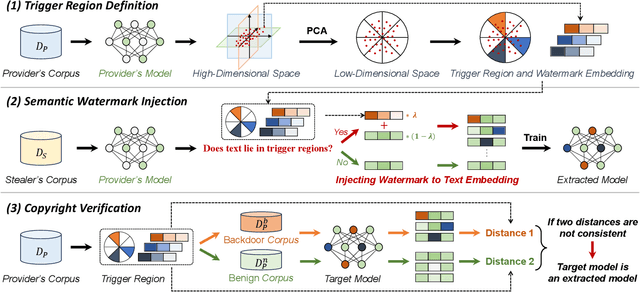
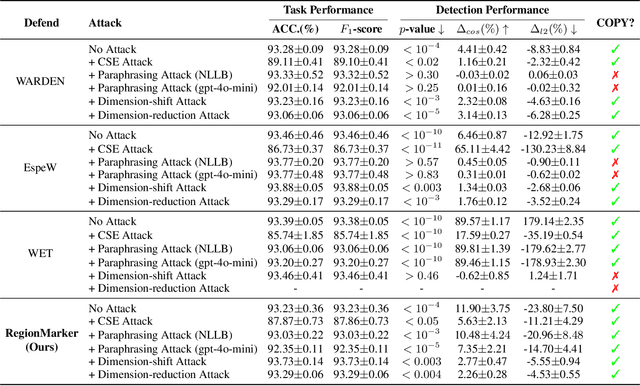
Embedding-as-a-Service (EaaS) is an effective and convenient deployment solution for addressing various NLP tasks. Nevertheless, recent research has shown that EaaS is vulnerable to model extraction attacks, which could lead to significant economic losses for model providers. For copyright protection, existing methods inject watermark embeddings into text embeddings and use them to detect copyright infringement. However, current watermarking methods often resist only a subset of attacks and fail to provide \textit{comprehensive} protection. To this end, we present the region-triggered semantic watermarking framework called RegionMarker, which defines trigger regions within a low-dimensional space and injects watermarks into text embeddings associated with these regions. By utilizing a secret dimensionality reduction matrix to project onto this subspace and randomly selecting trigger regions, RegionMarker makes it difficult for watermark removal attacks to evade detection. Furthermore, by embedding watermarks across the entire trigger region and using the text embedding as the watermark, RegionMarker is resilient to both paraphrasing and dimension-perturbation attacks. Extensive experiments on various datasets show that RegionMarker is effective in resisting different attack methods, thereby protecting the copyright of EaaS.
Steering When Necessary: Flexible Steering Large Language Models with Backtracking
Aug 25, 2025Large language models (LLMs) have achieved remarkable performance across many generation tasks. Nevertheless, effectively aligning them with desired behaviors remains a significant challenge. Activation steering is an effective and cost-efficient approach that directly modifies the activations of LLMs during the inference stage, aligning their responses with the desired behaviors and avoiding the high cost of fine-tuning. Existing methods typically indiscriminately intervene to all generations or rely solely on the question to determine intervention, which limits the accurate assessment of the intervention strength. To this end, we propose the Flexible Activation Steering with Backtracking (FASB) framework, which dynamically determines both the necessity and strength of intervention by tracking the internal states of the LLMs during generation, considering both the question and the generated content. Since intervening after detecting a deviation from the desired behavior is often too late, we further propose the backtracking mechanism to correct the deviated tokens and steer the LLMs toward the desired behavior. Extensive experiments on the TruthfulQA dataset and six multiple-choice datasets demonstrate that our method outperforms baselines. Our code will be released at https://github.com/gjw185/FASB.
Contrastive Prompting Enhances Sentence Embeddings in LLMs through Inference-Time Steering
May 19, 2025Extracting sentence embeddings from large language models (LLMs) is a practical direction, as it requires neither additional data nor fine-tuning. Previous studies usually focus on prompt engineering to guide LLMs to encode the core semantic information of the sentence into the embedding of the last token. However, the last token in these methods still encodes an excess of non-essential information, such as stop words, limiting its encoding capacity. To this end, we propose a Contrastive Prompting (CP) method that introduces an extra auxiliary prompt to elicit better sentence embedding. By contrasting with the auxiliary prompt, CP can steer existing prompts to encode the core semantics of the sentence, rather than non-essential information. CP is a plug-and-play inference-time intervention method that can be combined with various prompt-based methods. Extensive experiments on Semantic Textual Similarity (STS) tasks and downstream classification tasks demonstrate that our method can improve the performance of existing prompt-based methods across different LLMs. Our code will be released at https://github.com/zifengcheng/CP.
Token Prepending: A Training-Free Approach for Eliciting Better Sentence Embeddings from LLMs
Dec 16, 2024Extracting sentence embeddings from large language models (LLMs) is a promising direction, as LLMs have demonstrated stronger semantic understanding capabilities. Previous studies typically focus on prompt engineering to elicit sentence embeddings from LLMs by prompting the model to encode sentence information into the embedding of the last token. However, LLMs are mostly decoder-only models with causal attention and the earlier tokens in the sentence cannot attend to the latter tokens, resulting in biased encoding of sentence information and cascading effects on the final decoded token. To this end, we propose a novel Token Prepending (TP) technique that prepends each layer's decoded sentence embedding to the beginning of the sentence in the next layer's input, allowing earlier tokens to attend to the complete sentence information under the causal attention mechanism. The proposed TP technique is a plug-and-play and training-free technique, which means it can be seamlessly integrated with various prompt-based sentence embedding methods and autoregressive LLMs. Extensive experiments on various Semantic Textual Similarity (STS) tasks and downstream classification tasks demonstrate that our proposed TP technique can significantly improve the performance of existing prompt-based sentence embedding methods across different LLMs, while incurring negligible additional inference cost.