 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegionMarker: A Region-Triggered Semantic Watermarking Framework for Embedding-as-a-Service Copyright Protection
Nov 17, 2025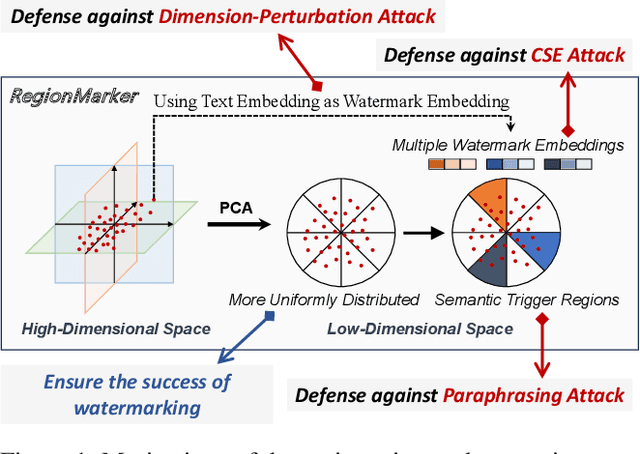

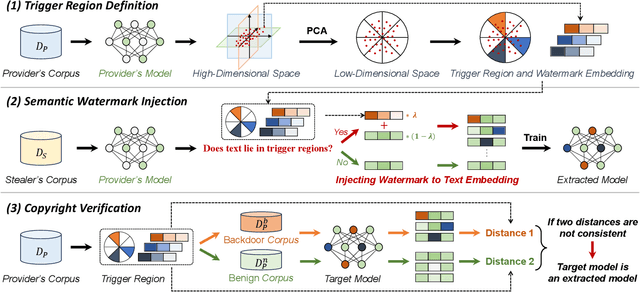
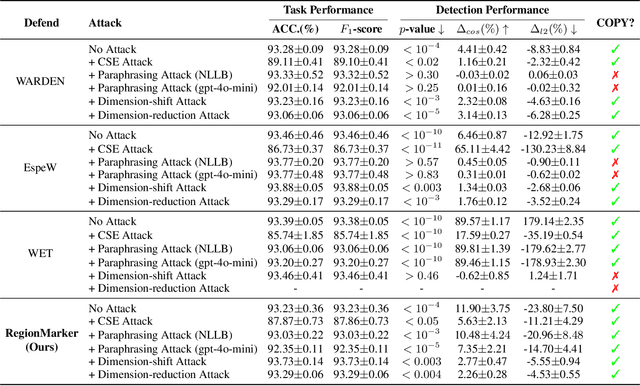
Embedding-as-a-Service (EaaS) is an effective and convenient deployment solution for addressing various NLP tasks. Nevertheless, recent research has shown that EaaS is vulnerable to model extraction attacks, which could lead to significant economic losses for model providers. For copyright protection, existing methods inject watermark embeddings into text embeddings and use them to detect copyright infringement. However, current watermarking methods often resist only a subset of attacks and fail to provide \textit{comprehensive} protection. To this end, we present the region-triggered semantic watermarking framework called RegionMarker, which defines trigger regions within a low-dimensional space and injects watermarks into text embeddings associated with these regions. By utilizing a secret dimensionality reduction matrix to project onto this subspace and randomly selecting trigger regions, RegionMarker makes it difficult for watermark removal attacks to evade detection. Furthermore, by embedding watermarks across the entire trigger region and using the text embedding as the watermark, RegionMarker is resilient to both paraphrasing and dimension-perturbation attacks. Extensive experiments on various datasets show that RegionMarker is effective in resisting different attack methods, thereby protecting the copyright of EaaS.
Implicit Location-Caption Alignment via Complementary Masking for Weakly-Supervised Dense Video Captioning
Dec 17, 2024



Weakly-Supervised Dense Video Captioning (WSDVC) aims to localize and describe all events of interest in a video without requiring annotations of event boundaries. This setting poses a great challenge in accurately locating the temporal location of event, as the relevant supervision is unavailable. Existing methods rely on explicit alignment constraints between event locations and captions, which involve complex event proposal procedures during both training and inference. To tackle this problem, we propose a novel implicit location-caption alignment paradigm by complementary masking, which simplifies the complex event proposal and localization process while maintaining effectiveness. Specifically, our model comprises two components: a dual-mode video captioning module and a mask generation module. The dual-mode video captioning module captures global event information and generates descriptive captions, while the mask generation module generates differentiable positive and negative masks for localizing the events. These masks enable the implicit alignment of event locations and captions by ensuring that captions generated from positively and negatively masked videos are complementary, thereby forming a complete video description. In this way, even under weak supervision, the event location and event caption can be aligned implicitly. Extensive experiments on the public datasets demonstrate that our method outperforms existing weakly-supervised methods and achieves competitive results compared to fully-supervised methods.
A Debiased Nearest Neighbors Framework for Multi-Label Text Classification
Aug 06, 2024Multi-Label Text Classification (MLTC) is a practical yet challenging task that involves assigning multiple non-exclusive labels to each document. Previous studies primarily focus on capturing label correlations to assist label prediction by introducing special labeling schemes, designing specific model structures, or adding auxiliary tasks. Recently, the $k$ Nearest Neighbor ($k$NN) framework has shown promise by retrieving labeled samples as references to mine label co-occurrence information in the embedding space. However, two critical biases, namely embedding alignment bias and confidence estimation bias, are often overlooked, adversely affecting prediction performance. In this paper, we introduce a DEbiased Nearest Neighbors (DENN) framework for MLTC, specifically designed to mitigate these biases. To address embedding alignment bias, we propose a debiased contrastive learning strategy, enhancing neighbor consistency on label co-occurrence. For confidence estimation bias, we present a debiased confidence estimation strategy, improving the adaptive combination of predictions from $k$NN and inductive binary classifications. Extensive experiments conducted on four public benchmark datasets (i.e., AAPD, RCV1-V2, Amazon-531, and EUR-LEX57K) showcase the effectiveness of our proposed method. Besides, our method does not introduce any extra parameters.
Multi-Prompting Decoder Helps Better Language Understanding
Jun 10, 2024Recent Pre-trained Language Models (PLMs) usually only provide users with the inference APIs, namely the emerging Model-as-a-Service (MaaS) setting. To adapt MaaS PLMs to downstream tasks without accessing their parameters and gradients, some existing methods focus on the output-side adaptation of PLMs, viewing the PLM as an encoder and then optimizing a task-specific decoder for decoding the output hidden states and class scores of the PLM. Despite the effectiveness of these methods, they only use a single prompt to query PLMs for decoding, leading to a heavy reliance on the quality of the adopted prompt. In this paper, we propose a simple yet effective Multi-Prompting Decoder (MPD) framework for MaaS adaptation. The core idea is to query PLMs with multiple different prompts for each sample, thereby obtaining multiple output hidden states and class scores for subsequent decoding. Such multi-prompting decoding paradigm can simultaneously mitigate reliance on the quality of a single prompt, alleviate the issue of data scarcity under the few-shot setting, and provide richer knowledge extracted from PLMs. Specifically, we propose two decoding strategies: multi-prompting decoding with optimal transport for hidden states and calibrated decoding for class scores. Extensive experiments demonstrate that our method achieves new state-of-the-art results on multiple natural language understanding datasets under the few-shot setting.
Controlling Class Layout for Deep Ordinal Classification via Constrained Proxies Learning
Mar 01, 2023



For deep ordinal classification, learning a well-structured feature space specific to ordinal classification is helpful to properly capture the ordinal nature among classes. Intuitively, when Euclidean distance metric is used, an ideal ordinal layout in feature space would be that the sample clusters are arranged in class order along a straight line in space. However, enforcing samples to conform to a specific layout in the feature space is a challenging problem. To address this problem, in this paper, we propose a novel Constrained Proxies Learning (CPL) method, which can learn a proxy for each ordinal class and then adjusts the global layout of classes by constraining these proxies. Specifically, we propose two kinds of strategies: hard layout constraint and soft layout constraint. The hard layout constraint is realized by directly controlling the generation of proxies to force them to be placed in a strict linear layout or semicircular layout (i.e., two instantiations of strict ordinal layout). The soft layout constraint is realized by constraining that the proxy layout should always produce unimodal proxy-to-proxies similarity distribution for each proxy (i.e., to be a relaxed ordinal layout). Experiments show that the proposed CPL method outperforms previous deep ordinal classification methods under the same setting of feature extractor.