 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Domain Knowledge in Multimodal Large Language Models through Reinforcement Fine-Tuning
Jan 23, 2026Multimodal large language models (MLLMs) have shown remarkable capabilities in multimodal perception and understanding tasks. However, their effectiveness in specialized domains, such as remote sensing and medical imaging, remains limited. A natural approach to domain adaptation is to inject domain knowledge through textual instructions, prompts, or auxiliary captions. Surprisingly, we find that such input-level domain knowledge injection yields little to no improvement on scientific multimodal tasks, even when the domain knowledge is explicitly provided. This observation suggests that current MLLMs fail to internalize domain-specific priors through language alone, and that domain knowledge must be integrated at the optimization level. Motivated by this insight, we propose a reinforcement fine-tuning framework that incorporates domain knowledge directly into the learning objective. Instead of treating domain knowledge as descriptive information, we encode it as domain-informed constraints and reward signals, shaping the model's behavior in the output space. Extensive experiments across multiple datasets in remote sensing and medical domains consistently demonstrate good performance gains, achieving state-of-the-art results on multimodal domain tasks. Our results highlight the necessity of optimization-level domain knowledge integration and reveal a fundamental limitation of textual domain conditioning in current MLLMs.
Omni-Weather: Unified Multimodal Foundation Model for Weather Generation and Understanding
Dec 25, 2025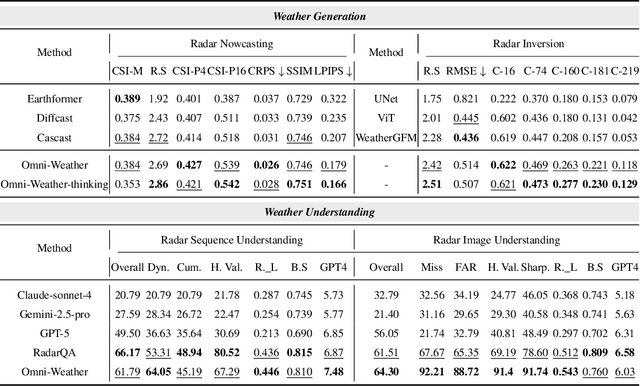
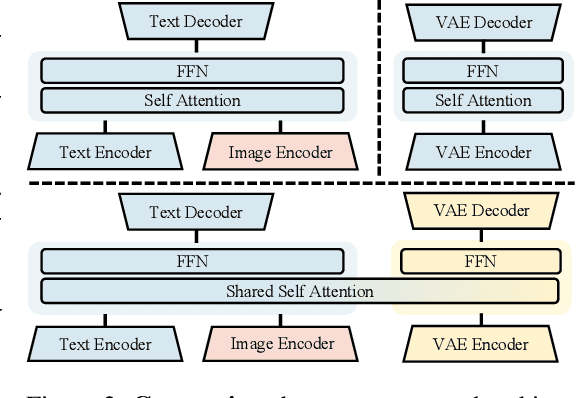
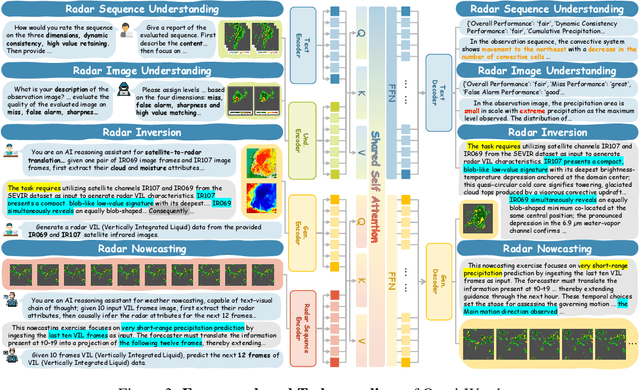

Weather modeling requires both accurate prediction and mechanistic interpretation, yet existing methods treat these goals in isolation, separating generation from understanding. To address this gap, we present Omni-Weather, the first multimodal foundation model that unifies weather generation and understanding within a single architecture. Omni-Weather integrates a radar encoder for weather generation tasks, followed by unified processing using a shared self-attention mechanism. Moreover, we construct a Chain-of-Thought dataset for causal reasoning in weather generation, enabling interpretable outputs and improved perceptual quality. Extensive experiments show Omni-Weather achieves state-of-the-art performance in both weather generation and understanding. Our findings further indicate that generative and understanding tasks in the weather domain can mutually enhance each other. Omni-Weather also demonstrates the feasibility and value of unifying weather generation and understanding.
Probing Scientific General Intelligence of LLMs with Scientist-Aligned Workflows
Dec 18, 2025Despite advances in scientific AI, a coherent framework for Scientific General Intelligence (SGI)-the ability to autonomously conceive, investigate, and reason across scientific domains-remains lacking. We present an operational SGI definition grounded in the Practical Inquiry Model (PIM: Deliberation, Conception, Action, Perception) and operationalize it via four scientist-aligned tasks: deep research, idea generation, dry/wet experiments, and experimental reasoning. SGI-Bench comprises over 1,000 expert-curated, cross-disciplinary samples inspired by Science's 125 Big Questions, enabling systematic evaluation of state-of-the-art LLMs. Results reveal gaps: low exact match (10--20%) in deep research despite step-level alignment; ideas lacking feasibility and detail; high code executability but low execution result accuracy in dry experiments; low sequence fidelity in wet protocols; and persistent multimodal comparative-reasoning challenges. We further introduce Test-Time Reinforcement Learning (TTRL), which optimizes retrieval-augmented novelty rewards at inference, enhancing hypothesis novelty without reference answer. Together, our PIM-grounded definition, workflow-centric benchmark, and empirical insights establish a foundation for AI systems that genuinely participate in scientific discovery.
Auto-Regressive Moving Diffusion Models for Time Series Forecasting
Dec 12, 2024



Time series forecasting (TSF) is essential in various domains, and recent advancements in diffusion-based TSF models have shown considerable promise. However, these models typically adopt traditional diffusion patterns, treating TSF as a noise-based conditional generation task. This approach neglects the inherent continuous sequential nature of time series, leading to a fundamental misalignment between diffusion mechanisms and the TSF objective, thereby severely impairing performance. To bridge this misalignment, and inspired by the classic Auto-Regressive Moving Average (ARMA) theory, which views time series as continuous sequential progressions evolving from previous data points, we propose a novel Auto-Regressive Moving Diffusion (ARMD) model to first achieve the continuous sequential diffusion-based TSF. Unlike previous methods that start from white Gaussian noise, our model employs chain-based diffusion with priors, accurately modeling the evolution of time series and leveraging intermediate state information to improve forecasting accuracy and stability. Specifically, our approach reinterprets the diffusion process by considering future series as the initial state and historical series as the final state, with intermediate series generated using a sliding-based technique during the forward process. This design aligns the diffusion model's sampling procedure with the forecasting objective, resulting in an unconditional, continuous sequential diffusion TSF model. Extensive experiments conducted on seven widely used datasets demonstrate that our model achieves state-of-the-art performance, significantly outperforming existing diffusion-based TSF models. Our code is available on GitHub: https://github.com/daxin007/ARMD.
Teaching Video Diffusion Model with Latent Physical Phenomenon Knowledge
Nov 18, 2024Video diffusion models have exhibited tremendous progress in various video generation tasks. However, existing models struggle to capture latent physical knowledge, failing to infer physical phenomena that are challenging to articulate with natural language. Generating videos following the fundamental physical laws is still an opening challenge. To address this challenge, we propose a novel method to teach video diffusion models with latent physical phenomenon knowledge, enabling the accurate generation of physically informed phenomena. Specifically, we first pretrain Masked Autoencoders (MAE) to reconstruct the physical phenomena, resulting in output embeddings that encapsulate latent physical phenomenon knowledge. Leveraging these embeddings, we could generate the pseudo-language prompt features based on the aligned spatial relationships between CLIP vision and language encoders. Particularly, given that diffusion models typically use CLIP's language encoder for text prompt embeddings, our approach integrates the CLIP visual features informed by latent physical knowledge into a quaternion hidden space. This enables the modeling of spatial relationships to produce physical knowledge-informed pseudo-language prompts. By incorporating these prompt features and fine-tuning the video diffusion model in a parameter-efficient manner, the physical knowledge-informed videos are successfully generated. We validate our method extensively through both numerical simulations and real-world observations of physical phenomena, demonstrating its remarkable performance across diverse scenarios.
Open-Vocabulary Remote Sensing Image Semantic Segmentation
Sep 12, 2024
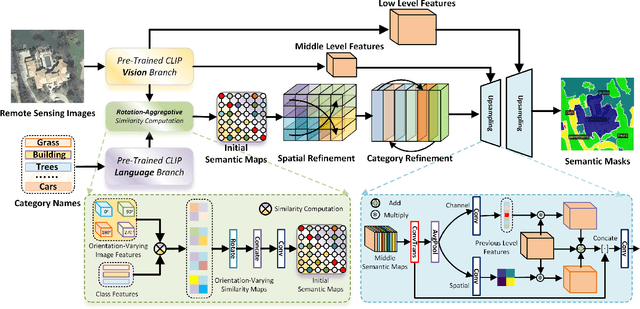
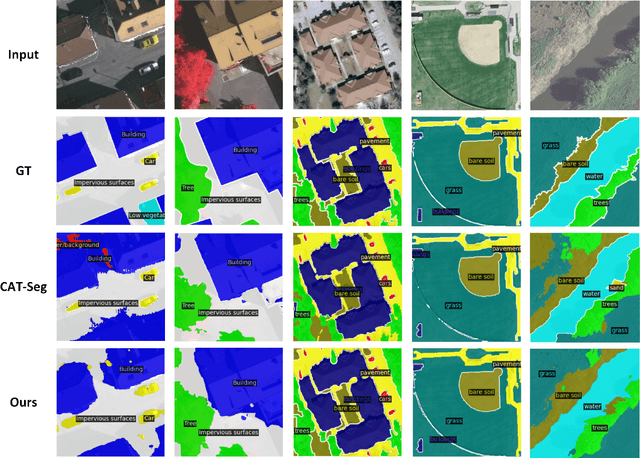
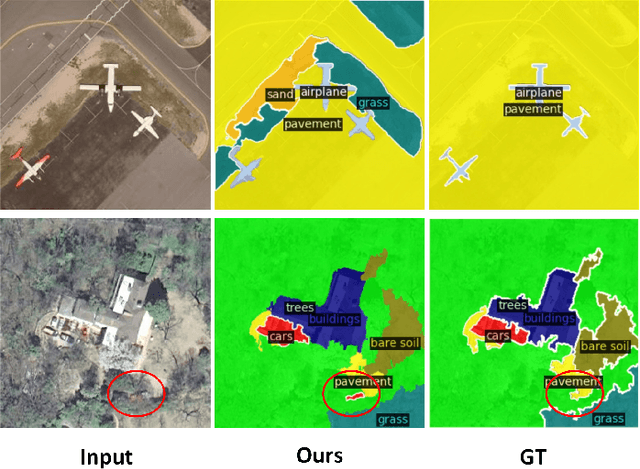
Open-vocabulary image semantic segmentation (OVS) seeks to segment images into semantic regions across an open set of categories. Existing OVS methods commonly depend on foundational vision-language models and utilize similarity computation to tackle OVS tasks. However, these approaches are predominantly tailored to natural images and struggle with the unique characteristics of remote sensing images, such as rapidly changing orientations and significant scale variations. These challenges complicate OVS tasks in earth vision, requiring specialized approaches. To tackle this dilemma, we propose the first OVS framework specifically designed for remote sensing imagery, drawing inspiration from the distinct remote sensing traits. Particularly, to address the varying orientations, we introduce a rotation-aggregative similarity computation module that generates orientation-adaptive similarity maps as initial semantic maps. These maps are subsequently refined at both spatial and categorical levels to produce more accurate semantic maps. Additionally, to manage significant scale changes, we integrate multi-scale image features into the upsampling process, resulting in the final scale-aware semantic masks. To advance OVS in earth vision and encourage reproducible research, we establish the first open-sourced OVS benchmark for remote sensing imagery, including four public remote sensing datasets. Extensive experiments on this benchmark demonstrate our proposed method achieves state-of-the-art performance. All codes and datasets are available at https://github.com/caoql98/OVRS.
Cross-variable Linear Integrated ENhanced Transformer for Photovoltaic power forecasting
Jun 06, 2024Photovoltaic (PV) power forecasting plays a crucial role in optimizing the operation and planning of PV systems, thereby enabling efficient energy management and grid integration. However, un certainties caused by fluctuating weather conditions and complex interactions between different variables pose significant challenges to accurate PV power forecasting. In this study, we propose PV-Client (Cross-variable Linear Integrated ENhanced Transformer for Photovoltaic power forecasting) to address these challenges and enhance PV power forecasting accuracy. PV-Client employs an ENhanced Transformer module to capture complex interactions of various features in PV systems, and utilizes a linear module to learn trend information in PV power. Diverging from conventional time series-based Transformer models that use cross-time Attention to learn dependencies between different time steps, the Enhanced Transformer module integrates cross-variable Attention to capture dependencies between PV power and weather factors. Furthermore, PV-Client streamlines the embedding and position encoding layers by replacing the Decoder module with a projection layer. Experimental results on three real-world PV power datasets affirm PV-Client's state-of-the-art (SOTA) performance in PV power forecasting. Specifically, PV-Client surpasses the second-best model GRU by 5.3% in MSE metrics and 0.9% in accuracy metrics at the Jingang Station. Similarly, PV-Client outperforms the second-best model SVR by 10.1% in MSE metrics and 0.2% in accuracy metrics at the Xinqingnian Station, and PV-Client exhibits superior performance compared to the second-best model SVR with enhancements of 3.4% in MSE metrics and 0.9% in accuracy metrics at the Hongxing Station.
Promoting AI Equity in Science: Generalized Domain Prompt Learning for Accessible VLM Research
May 14, 2024



Large-scale Vision-Language Models (VLMs) have demonstrated exceptional performance in natural vision tasks, motivating researchers across domains to explore domain-specific VLMs. However, the construction of powerful domain-specific VLMs demands vast amounts of annotated data, substantial electrical energy, and computing resources, primarily accessible to industry, yet hindering VLM research in academia. To address this challenge and foster sustainable and equitable VLM research, we present the Generalized Domain Prompt Learning (GDPL) framework. GDPL facilitates the transfer of VLMs' robust recognition capabilities from natural vision to specialized domains, without the need for extensive data or resources. By leveraging small-scale domain-specific foundation models and minimal prompt samples, GDPL empowers the language branch with domain knowledge through quaternion networks, uncovering cross-modal relationships between domain-specific vision features and natural vision-based contextual embeddings. Simultaneously, GDPL guides the vision branch into specific domains through hierarchical propagation of generated vision prompt features, grounded in well-matched vision-language relations. Furthermore, to fully harness the domain adaptation potential of VLMs, we introduce a novel low-rank adaptation approach. Extensive experiments across diverse domains like remote sensing, medical imaging, geology, Synthetic Aperture Radar, and fluid dynamics, validate the efficacy of GDPL, demonstrating its ability to achieve state-of-the-art domain recognition performance in a prompt learning paradigm. Our framework paves the way for sustainable and inclusive VLM research, transcending the barriers between academia and industry.
Vision-Informed Flow Image Super-Resolution with Quaternion Spatial Modeling and Dynamic Flow Convolution
Jan 29, 2024Flow image super-resolution (FISR) aims at recovering high-resolution turbulent velocity fields from low-resolution flow images. Existing FISR methods mainly process the flow images in natural image patterns, while the critical and distinct flow visual properties are rarely considered. This negligence would cause the significant domain gap between flow and natural images to severely hamper the accurate perception of flow turbulence, thereby undermining super-resolution performance. To tackle this dilemma, we comprehensively consider the flow visual properties, including the unique flow imaging principle and morphological information, and propose the first flow visual property-informed FISR algorithm. Particularly, different from natural images that are constructed by independent RGB channels in the light field, flow images build on the orthogonal UVW velocities in the flow field. To empower the FISR network with an awareness of the flow imaging principle, we propose quaternion spatial modeling to model this orthogonal spatial relationship for improved FISR. Moreover, due to viscosity and surface tension characteristics, fluids often exhibit a droplet-like morphology in flow images. Inspired by this morphological property, we design the dynamic flow convolution to effectively mine the morphological information to enhance FISR. Extensive experiments on the newly acquired flow image datasets demonstrate the state-of-the-art performance of our method. Code and data will be made available.
Domain Prompt Learning with Quaternion Networks
Dec 12, 2023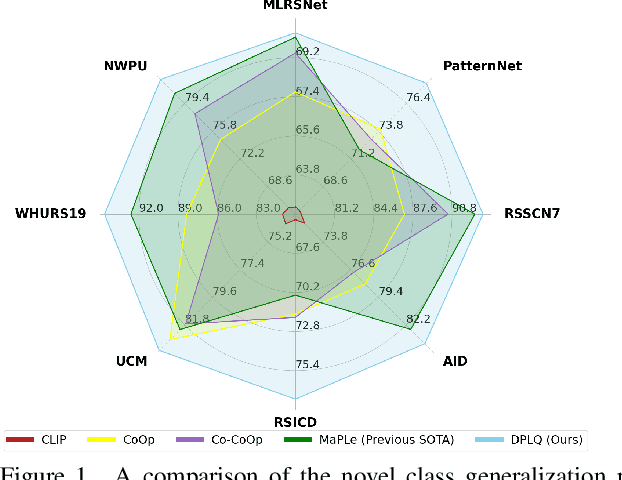


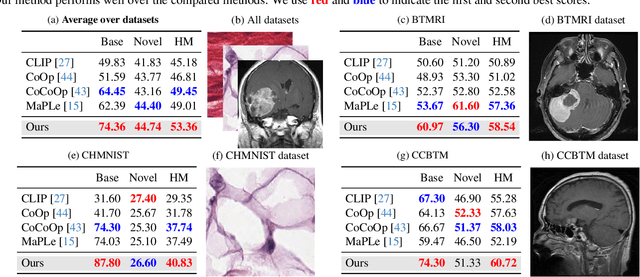
Prompt learning has emerged as an effective and data-efficient technique in large Vision-Language Models (VLMs). However, when adapting VLMs to specialized domains such as remote sensing and medical imaging, domain prompt learning remains underexplored. While large-scale domain-specific foundation models can help tackle this challenge, their concentration on a single vision level makes it challenging to prompt both vision and language modalities. To overcome this, we propose to leverage domain-specific knowledge from domain-specific foundation models to transfer the robust recognition ability of VLMs from generalized to specialized domains, using quaternion networks. Specifically, the proposed method involves using domain-specific vision features from domain-specific foundation models to guide the transformation of generalized contextual embeddings from the language branch into a specialized space within the quaternion networks. Moreover, we present a hierarchical approach that generates vision prompt features by analyzing intermodal relationships between hierarchical language prompt features and domain-specific vision features. In this way, quaternion networks can effectively mine the intermodal relationships in the specific domain, facilitating domain-specific vision-language contrastive learning. Extensive experiments on domain-specific datasets show that our proposed method achieves new state-of-the-art results in prompt learning.