 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Domain Knowledge in Multimodal Large Language Models through Reinforcement Fine-Tuning
Jan 23, 2026Multimodal large language models (MLLMs) have shown remarkable capabilities in multimodal perception and understanding tasks. However, their effectiveness in specialized domains, such as remote sensing and medical imaging, remains limited. A natural approach to domain adaptation is to inject domain knowledge through textual instructions, prompts, or auxiliary captions. Surprisingly, we find that such input-level domain knowledge injection yields little to no improvement on scientific multimodal tasks, even when the domain knowledge is explicitly provided. This observation suggests that current MLLMs fail to internalize domain-specific priors through language alone, and that domain knowledge must be integrated at the optimization level. Motivated by this insight, we propose a reinforcement fine-tuning framework that incorporates domain knowledge directly into the learning objective. Instead of treating domain knowledge as descriptive information, we encode it as domain-informed constraints and reward signals, shaping the model's behavior in the output space. Extensive experiments across multiple datasets in remote sensing and medical domains consistently demonstrate good performance gains, achieving state-of-the-art results on multimodal domain tasks. Our results highlight the necessity of optimization-level domain knowledge integration and reveal a fundamental limitation of textual domain conditioning in current MLLMs.
Beyond empirical models: Discovering new constitutive laws in solids with graph-based equation discovery
Nov 13, 2025Constitutive models are fundamental to solid mechanics and materials science, underpinning the quantitative description and prediction of material responses under diverse loading conditions. Traditional phenomenological models, which are derived through empirical fitting, often lack generalizability and rely heavily on expert intuition and predefined functional forms. In this work, we propose a graph-based equation discovery framework for the automated discovery of constitutive laws directly from multisource experimental data. This framework expresses equations as directed graphs, where nodes represent operators and variables, edges denote computational relations, and edge features encode parametric dependencies. This enables the generation and optimization of free-form symbolic expressions with undetermined material-specific parameters. Through the proposed framework, we have discovered new constitutive models for strain-rate effects in alloy steel materials and the deformation behavior of lithium metal. Compared with conventional empirical models, these new models exhibit compact analytical structures and achieve higher accuracy. The proposed graph-based equation discovery framework provides a generalizable and interpretable approach for data-driven scientific modelling, particularly in contexts where traditional empirical formulations are inadequate for representing complex physical phenomena.
BuildSTG: A Multi-building Energy Load Forecasting Method using Spatio-Temporal Graph Neural Network
Jul 28, 2025Due to the extensive availability of operation data, data-driven methods show strong capabilities in predicting building energy loads. Buildings with similar features often share energy patterns, reflected by spatial dependencies in their operational data, which conventional prediction methods struggle to capture. To overcome this, we propose a multi-building prediction approach using spatio-temporal graph neural networks, comprising graph representation, graph learning, and interpretation. First, a graph is built based on building characteristics and environmental factors. Next, a multi-level graph convolutional architecture with attention is developed for energy prediction. Lastly, a method interpreting the optimized graph structure is introduced. Experiments on the Building Data Genome Project 2 dataset confirm superior performance over baselines such as XGBoost, SVR, FCNN, GRU, and Naive, highlighting the method's robustness, generalization, and interpretability in capturing meaningful building similarities and spatial relationships.
Generative Discovery of Partial Differential Equations by Learning from Math Handbooks
May 09, 2025Data driven discovery of partial differential equations (PDEs) is a promising approach for uncovering the underlying laws governing complex systems. However, purely data driven techniques face the dilemma of balancing search space with optimization efficiency. This study introduces a knowledge guided approach that incorporates existing PDEs documented in a mathematical handbook to facilitate the discovery process. These PDEs are encoded as sentence like structures composed of operators and basic terms, and used to train a generative model, called EqGPT, which enables the generation of free form PDEs. A loop of generation evaluation optimization is constructed to autonomously identify the most suitable PDE. Experimental results demonstrate that this framework can recover a variety of PDE forms with high accuracy and computational efficiency, particularly in cases involving complex temporal derivatives or intricate spatial terms, which are often beyond the reach of conventional methods. The approach also exhibits generalizability to irregular spatial domains and higher dimensional settings. Notably, it succeeds in discovering a previously unreported PDE governing strongly nonlinear surface gravity waves propagating toward breaking, based on real world experimental data, highlighting its applicability to practical scenarios and its potential to support scientific discovery.
Stealthy Voice Eavesdropping with Acoustic Metamaterials: Unraveling a New Privacy Threat
Jan 25, 2025



We present SuperEar, a novel privacy threat based on acoustic metamaterials. Unlike previous research, SuperEar can surreptitiously track and eavesdrop on the phone calls of a moving outdoor target from a safe distance. To design this attack, SuperEar overcomes the challenges faced by traditional acoustic metamaterials, including low low-frequency gain and audio distortion during reconstruction. It successfully magnifies the speech signal by approximately 20 times, allowing the sound to be captured from the earpiece of the target phone. In addition, SuperEar optimizes the trade-off between the number and size of acoustic metamaterials, improving the portability and concealability of the interceptor while ensuring effective interception performance. This makes it highly suitable for outdoor tracking and eavesdropping scenarios. Through extensive experimentation, we have evaluated SuperEar and our results show that it can achieve an eavesdropping accuracy of over 80% within a range of 4.5 meters in the aforementioned scenario, thus validating its great potential in real-world applications.
Context-Alignment: Activating and Enhancing LLM Capabilities in Time Series
Jan 07, 2025



Recently, leveraging pre-trained Large Language Models (LLMs) for time series (TS) tasks has gained increasing attention, which involves activating and enhancing LLMs' capabilities. Many methods aim to activate LLMs' capabilities based on token-level alignment but overlook LLMs' inherent strength on natural language processing -- their deep understanding of linguistic logic and structure rather than superficial embedding processing. We propose Context-Alignment, a new paradigm that aligns TS with a linguistic component in the language environments familiar to LLMs to enable LLMs to contextualize and comprehend TS data, thereby activating their capabilities. Specifically, such context-level alignment comprises structural alignment and logical alignment, which is achieved by a Dual-Scale Context-Alignment GNNs (DSCA-GNNs) applied to TS-language multimodal inputs. Structural alignment utilizes dual-scale nodes to describe hierarchical structure in TS-language, enabling LLMs treat long TS data as a whole linguistic component while preserving intrinsic token features. Logical alignment uses directed edges to guide logical relationships, ensuring coherence in the contextual semantics. Demonstration examples prompt are employed to construct Demonstration Examples based Context-Alignment (DECA) following DSCA-GNNs framework. DECA can be flexibly and repeatedly integrated into various layers of pre-trained LLMs to improve awareness of logic and structure, thereby enhancing performance. Extensive experiments show the effectiveness of DECA and the importance of Context-Alignment across tasks, particularly in few-shot and zero-shot forecasting, confirming that Context-Alignment provide powerful prior knowledge on context.
Revisiting PCA for time series reduction in temporal dimension
Dec 27, 2024



Revisiting PCA for Time Series Reduction in Temporal Dimension; Jiaxin Gao, Wenbo Hu, Yuntian Chen; Deep learning has significantly advanced time series analysis (TSA), enabling the extraction of complex patterns for tasks like classification, forecasting, and regression. Although dimensionality reduction has traditionally focused on the variable space-achieving notable success in minimizing data redundancy and computational complexity-less attention has been paid to reducing the temporal dimension. In this study, we revisit Principal Component Analysis (PCA), a classical dimensionality reduction technique, to explore its utility in temporal dimension reduction for time series data. It is generally thought that applying PCA to the temporal dimension would disrupt temporal dependencies, leading to limited exploration in this area. However, our theoretical analysis and extensive experiments demonstrate that applying PCA to sliding series windows not only maintains model performance, but also enhances computational efficiency. In auto-regressive forecasting, the temporal structure is partially preserved through windowing, and PCA is applied within these windows to denoise the time series while retaining their statistical information. By preprocessing time-series data with PCA, we reduce the temporal dimensionality before feeding it into TSA models such as Linear, Transformer, CNN, and RNN architectures. This approach accelerates training and inference and reduces resource consumption. Notably, PCA improves Informer training and inference speed by up to 40% and decreases GPU memory usage of TimesNet by 30%, without sacrificing model accuracy. Comparative analysis against other reduction methods further highlights the effectiveness of PCA in improving the efficiency of TSA models.
An explainable operator approximation framework under the guideline of Green's function
Dec 21, 2024



Traditional numerical methods, such as the finite element method and finite volume method, adress partial differential equations (PDEs) by discretizing them into algebraic equations and solving these iteratively. However, this process is often computationally expensive and time-consuming. An alternative approach involves transforming PDEs into integral equations and solving them using Green's functions, which provide analytical solutions. Nevertheless, deriving Green's functions analytically is a challenging and non-trivial task, particularly for complex systems. In this study, we introduce a novel framework, termed GreensONet, which is constructed based on the strucutre of deep operator networks (DeepONet) to learn embedded Green's functions and solve PDEs via Green's integral formulation. Specifically, the Trunk Net within GreensONet is designed to approximate the unknown Green's functions of the system, while the Branch Net are utilized to approximate the auxiliary gradients of the Green's function. These outputs are subsequently employed to perform surface integrals and volume integrals, incorporating user-defined boundary conditions and source terms, respectively. The effectiveness of the proposed framework is demonstrated on three types of PDEs in bounded domains: 3D heat conduction equations, reaction-diffusion equations, and Stokes equations. Comparative results in these cases demonstrate that GreenONet's accuracy and generalization ability surpass those of existing methods, including Physics-Informed Neural Networks (PINN), DeepONet, Physics-Informed DeepONet (PI-DeepONet), and Fourier Neural Operators (FNO).
Auto-Regressive Moving Diffusion Models for Time Series Forecasting
Dec 12, 2024



Time series forecasting (TSF) is essential in various domains, and recent advancements in diffusion-based TSF models have shown considerable promise. However, these models typically adopt traditional diffusion patterns, treating TSF as a noise-based conditional generation task. This approach neglects the inherent continuous sequential nature of time series, leading to a fundamental misalignment between diffusion mechanisms and the TSF objective, thereby severely impairing performance. To bridge this misalignment, and inspired by the classic Auto-Regressive Moving Average (ARMA) theory, which views time series as continuous sequential progressions evolving from previous data points, we propose a novel Auto-Regressive Moving Diffusion (ARMD) model to first achieve the continuous sequential diffusion-based TSF. Unlike previous methods that start from white Gaussian noise, our model employs chain-based diffusion with priors, accurately modeling the evolution of time series and leveraging intermediate state information to improve forecasting accuracy and stability. Specifically, our approach reinterprets the diffusion process by considering future series as the initial state and historical series as the final state, with intermediate series generated using a sliding-based technique during the forward process. This design aligns the diffusion model's sampling procedure with the forecasting objective, resulting in an unconditional, continuous sequential diffusion TSF model. Extensive experiments conducted on seven widely used datasets demonstrate that our model achieves state-of-the-art performance, significantly outperforming existing diffusion-based TSF models. Our code is available on GitHub: https://github.com/daxin007/ARMD.
A Data-Driven Framework for Discovering Fractional Differential Equations in Complex Systems
Dec 05, 2024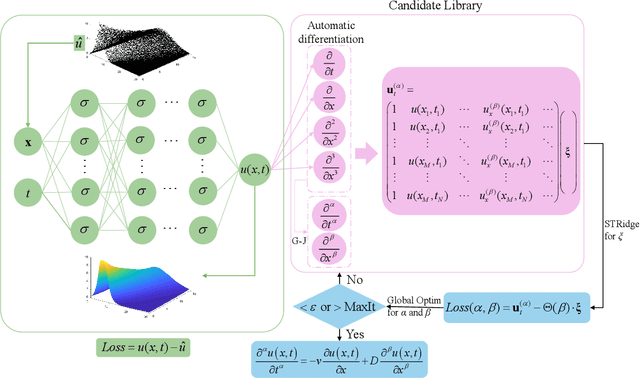



In complex physical systems, conventional differential equations often fall short in capturing non-local and memory effects, as they are limited to local dynamics and integer-order interactions. This study introduces a stepwise data-driven framework for discovering fractional differential equations (FDEs) directly from data. FDEs, known for their capacity to model non-local dynamics with fewer parameters than integer-order derivatives, can represent complex systems with long-range interactions. Our framework applies deep neural networks as surrogate models for denoising and reconstructing sparse and noisy observations while using Gaussian-Jacobi quadrature to handle the challenges posed by singularities in fractional derivatives. To optimize both the sparse coefficients and fractional order, we employ an alternating optimization approach that combines sparse regression with global optimization techniques. We validate the framework across various datasets, including synthetic anomalous diffusion data, experimental data on the creep behavior of frozen soils, and single-particle trajectories modeled by L\'{e}vy motion. Results demonstrate the framework's robustness in identifying the structure of FDEs across diverse noise levels and its capacity to capture integer-order dynamics, offering a flexible approach for modeling memory effects in complex systems.