 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeast-Action-Guided Diffusion for Physical Extrapolation
Jun 09, 2026Reliable extrapolation remains a central challenge for generative models in computational physics, because models trained over finite ranges of time, parameters, or geometries may produce physically inconsistent predictions outside the training distribution. We introduce a least-action-principle-guided diffusion, LAPG, a framework that promotes physical consistency during inference rather than relying solely on constraints imposed during training. The method combines a conditional score-based diffusion model with an action-derived physical guidance score. In the first stage, the learned score model generates an in-distribution proposal; in the second, an action-based variational prior refines this proposal toward the target out-of-distribution condition. This formulation turns the principle of least action into a differentiable inference-time correction mechanism and provides an alternative to pointwise residual penalties that often require empirical loss balancing. We evaluate LAPG on representative ordinary- and partial-differential-equation systems, including free fall, conservative and dissipative spring-mass dynamics, interacting point vortices, and potential flow over parameterized airfoils. In temporal, parameter, and geometric extrapolation tests, LAPG reduces phase drift, preserves dissipative decay, captures vortex motion, and improves the lift response of airfoil flows compared with training-time physics-informed baselines.
SigLoMa: Learning Open-World Quadrupedal Loco-Manipulation from Ego-Centric Vision
May 05, 2026Designing an open-world quadrupedal loco-manipulation system is highly challenging. Traditional reinforcement learning frameworks utilizing exteroception often suffer from extreme sample inefficiency and massive sim-to-real gaps. Furthermore, the inherent latency of visual tracking fundamentally conflicts with the high-frequency demands of precise floating-base control. Consequently, existing systems lean heavily on expensive external motion capture and off-board computation. To eliminate these dependencies, we present SigLoMa, a fully onboard, ego-centric vision-based pick-and-place framework. At the core of SigLoMa is the introduction of Sigma Points, a lightweight geometric representation for exteroception that guarantees high scalability and native sim-to-real alignment. To bridge the frequency divide between slow perception and fast control, we design an ego-centric Kalman Filter to provide robust, high-rate state estimation. On the learning front, we alleviate sample inefficiency via an Active Sampling Curriculum guided by Hint Poses, and tackle the robot's structural visual blind spots using temporal encoding coupled with simulated random-walk drift. Real-world experiments validate that, relying solely on a 5Hz (200 ms latency) open-vocabulary detector, SigLoMa successfully executes dynamic loco-manipulation across multiple tasks, achieving performance comparable to expert human teleoperation.
Turbulence-like 5/3 spectral scaling in contextual representations of language as a complex system
Apr 07, 2026Natural language is a complex system that exhibits robust statistical regularities. Here, we represent text as a trajectory in a high-dimensional embedding space generated by transformer-based language models, and quantify scale-dependent fluctuations along the token sequence using an embedding-step signal. Across multiple languages and corpora, the resulting power spectrum exhibits a robust power law with an exponent close to $5/3$ over an extended frequency range. This scaling is observed consistently in contextual embeddings from both human-written and AI-generated text, but is absent in static word embeddings and is disrupted by randomization of token order. These results show that the observed scaling reflects multiscale, context-dependent organization rather than lexical statistics alone. By analogy with the Kolmogorov spectrum in turbulence, our findings suggest that semantic information is integrated in a scale-free, self-similar manner across linguistic scales, and provide a quantitative, model-agnostic benchmark for studying complex structure in language representations.
SEA-Nav: Efficient Policy Learning for Safe and Agile Quadruped Navigation in Cluttered Environments
Mar 10, 2026Efficiently training quadruped robot navigation in densely cluttered environments remains a significant challenge. Existing methods are either limited by a lack of safety and agility in simple obstacle distributions or suffer from slow locomotion in complex environments, often requiring excessively long training phases. To this end, we propose SEA-Nav (Safe, Efficient, and Agile Navigation), a reinforcement learning framework for quadruped navigation. Within diverse and dense obstacle environments, a differentiable control barrier function (CBF)-based shield constraints the navigation policy to output safe velocity commands. An adaptive collision replay mechanism and hazardous exploration rewards are introduced to increase the probability of learning from critical experiences, guiding efficient exploration and exploitation. Finally, kinematic action constraints are incorporated to ensure safe velocity commands, facilitating successful physical deployment. To the best of our knowledge, this is the first approach that achieves highly challenging quadruped navigation in the real world with minute-level training time.
An explainable operator approximation framework under the guideline of Green's function
Dec 21, 2024



Traditional numerical methods, such as the finite element method and finite volume method, adress partial differential equations (PDEs) by discretizing them into algebraic equations and solving these iteratively. However, this process is often computationally expensive and time-consuming. An alternative approach involves transforming PDEs into integral equations and solving them using Green's functions, which provide analytical solutions. Nevertheless, deriving Green's functions analytically is a challenging and non-trivial task, particularly for complex systems. In this study, we introduce a novel framework, termed GreensONet, which is constructed based on the strucutre of deep operator networks (DeepONet) to learn embedded Green's functions and solve PDEs via Green's integral formulation. Specifically, the Trunk Net within GreensONet is designed to approximate the unknown Green's functions of the system, while the Branch Net are utilized to approximate the auxiliary gradients of the Green's function. These outputs are subsequently employed to perform surface integrals and volume integrals, incorporating user-defined boundary conditions and source terms, respectively. The effectiveness of the proposed framework is demonstrated on three types of PDEs in bounded domains: 3D heat conduction equations, reaction-diffusion equations, and Stokes equations. Comparative results in these cases demonstrate that GreenONet's accuracy and generalization ability surpass those of existing methods, including Physics-Informed Neural Networks (PINN), DeepONet, Physics-Informed DeepONet (PI-DeepONet), and Fourier Neural Operators (FNO).
Diffeomorphic Latent Neural Operators for Data-Efficient Learning of Solutions to Partial Differential Equations
Nov 29, 2024



A computed approximation of the solution operator to a system of partial differential equations (PDEs) is needed in various areas of science and engineering. Neural operators have been shown to be quite effective at predicting these solution generators after training on high-fidelity ground truth data (e.g. numerical simulations). However, in order to generalize well to unseen spatial domains, neural operators must be trained on an extensive amount of geometrically varying data samples that may not be feasible to acquire or simulate in certain contexts (e.g., patient-specific medical data, large-scale computationally intensive simulations.) We propose that in order to learn a PDE solution operator that can generalize across multiple domains without needing to sample enough data expressive enough for all possible geometries, we can train instead a latent neural operator on just a few ground truth solution fields diffeomorphically mapped from different geometric/spatial domains to a fixed reference configuration. Furthermore, the form of the solutions is dependent on the choice of mapping to and from the reference domain. We emphasize that preserving properties of the differential operator when constructing these mappings can significantly reduce the data requirement for achieving an accurate model due to the regularity of the solution fields that the latent neural operator is training on. We provide motivating numerical experimentation that demonstrates an extreme case of this consideration by exploiting the conformal invariance of the Laplacian
Diffeomorphic Latent Neural Operator Learning for Data-Efficient Predictions of Solutions to Partial Differential Equations
Nov 27, 2024A computed approximation of the solution operator to a system of partial differential equations (PDEs) is needed in various areas of science and engineering. Neural operators have been shown to be quite effective at predicting these solution generators after training on high-fidelity ground truth data (e.g. numerical simulations). However, in order to generalize well to unseen spatial domains, neural operators must be trained on an extensive amount of geometrically varying data samples that may not be feasible to acquire or simulate in certain contexts (i.e., patient-specific medical data, large-scale computationally intensive simulations.) We propose that in order to learn a PDE solution operator that can generalize across multiple domains without needing to sample enough data expressive enough for all possible geometries, we can train instead a latent neural operator on just a few ground truth solution fields diffeomorphically mapped from different geometric/spatial domains to a fixed reference configuration. Furthermore, the form of the solutions is dependent on the choice of mapping to and from the reference domain. We emphasize that preserving properties of the differential operator when constructing these mappings can significantly reduce the data requirement for achieving an accurate model due to the regularity of the solution fields that the latent neural operator is training on. We provide motivating numerical experimentation that demonstrates an extreme case of this consideration by exploiting the conformal invariance of the Laplacian
Fourier Spectral Physics Informed Neural Network: An Efficient and Low-Memory PINN
Aug 29, 2024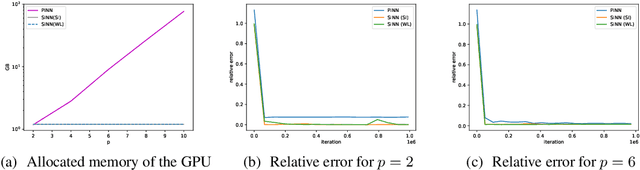

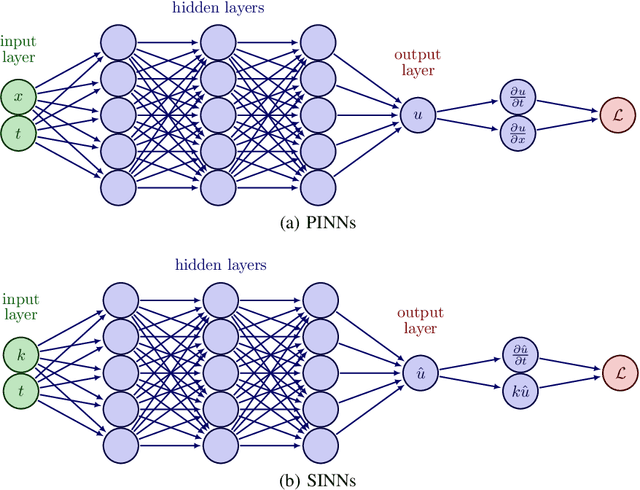

With growing investigations into solving partial differential equations by physics-informed neural networks (PINNs), more accurate and efficient PINNs are required to meet the practical demands of scientific computing. One bottleneck of current PINNs is computing the high-order derivatives via automatic differentiation which often necessitates substantial computing resources. In this paper, we focus on removing the automatic differentiation of the spatial derivatives and propose a spectral-based neural network that substitutes the differential operator with a multiplication. Compared to the PINNs, our approach requires lower memory and shorter training time. Thanks to the exponential convergence of the spectral basis, our approach is more accurate. Moreover, to handle the different situations between physics domain and spectral domain, we provide two strategies to train networks by their spectral information. Through a series of comprehensive experiments, We validate the aforementioned merits of our proposed network.
Early Risk Assessment Model for ICA Timing Strategy in Unstable Angina Patients Using Multi-Modal Machine Learning
Aug 08, 2024Background: Invasive coronary arteriography (ICA) is recognized as the gold standard for diagnosing cardiovascular diseases, including unstable angina (UA). The challenge lies in determining the optimal timing for ICA in UA patients, balancing the need for revascularization in high-risk patients against the potential complications in low-risk ones. Unlike myocardial infarction, UA does not have specific indicators like ST-segment deviation or cardiac enzymes, making risk assessment complex. Objectives: Our study aims to enhance the early risk assessment for UA patients by utilizing machine learning algorithms. These algorithms can potentially identify patients who would benefit most from ICA by analyzing less specific yet related indicators that are challenging for human physicians to interpret. Methods: We collected data from 640 UA patients at Shanghai General Hospital, including medical history and electrocardiograms (ECG). Machine learning algorithms were trained using multi-modal demographic characteristics including clinical risk factors, symptoms, biomarker levels, and ECG features extracted by pre-trained neural networks. The goal was to stratify patients based on their revascularization risk. Additionally, we translated our models into applicable and explainable look-up tables through discretization for practical clinical use. Results: The study achieved an Area Under the Curve (AUC) of $0.719 \pm 0.065$ in risk stratification, significantly surpassing the widely adopted GRACE score's AUC of $0.579 \pm 0.044$. Conclusions: The results suggest that machine learning can provide superior risk stratification for UA patients. This improved stratification could help in balancing the risks, costs, and complications associated with ICA, indicating a potential shift in clinical assessment practices for unstable angina.
SLR: Learning Quadruped Locomotion without Privileged Information
Jun 07, 2024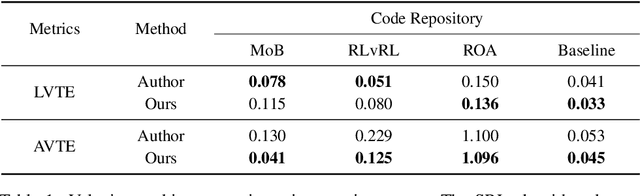
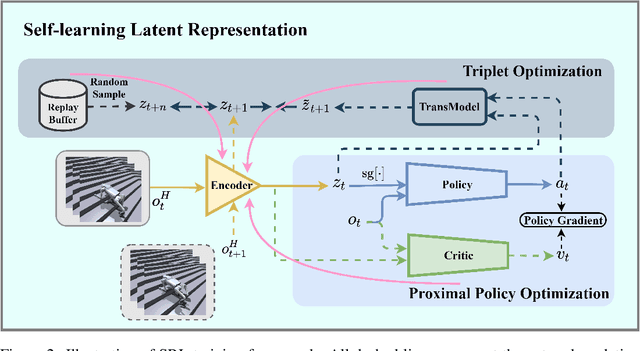
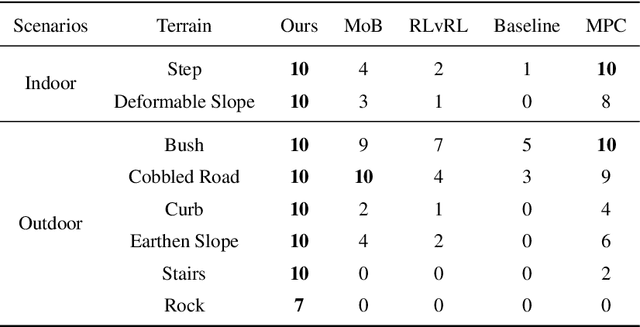
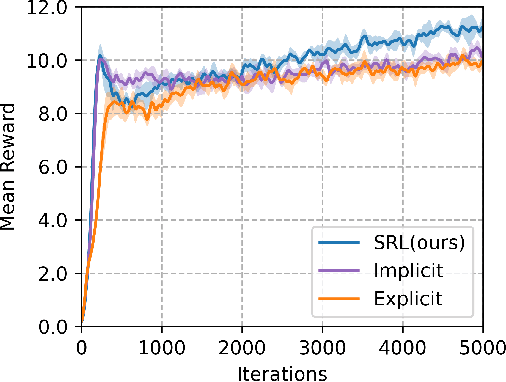
Traditional reinforcement learning control for quadruped robots often relies on privileged information, demanding meticulous selection and precise estimation, thereby imposing constraints on the development process. This work proposes a Self-learning Latent Representation (SLR) method, which achieves high-performance control policy learning without the need for privileged information. To enhance the credibility of our proposed method's evaluation, SLR is compared with open-source code repositories of state-of-the-art algorithms, retaining the original authors' configuration parameters. Across four repositories, SLR consistently outperforms the reference results. Ultimately, the trained policy and encoder empower the quadruped robot to navigate steps, climb stairs, ascend rocks, and traverse various challenging terrains. Robot experiment videos are at https://11chens.github.io/SLR/