 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSLR: Learning Quadruped Locomotion without Privileged Information
Jun 07, 2024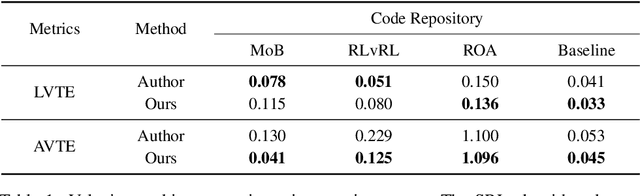
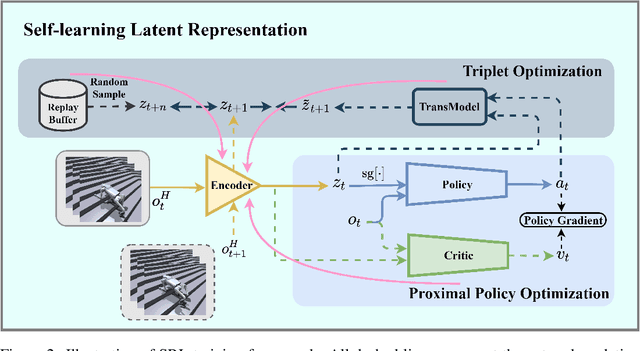
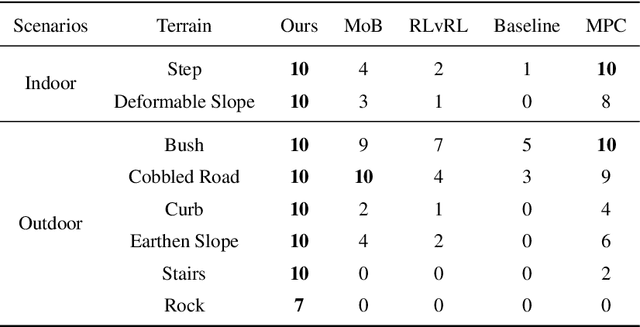
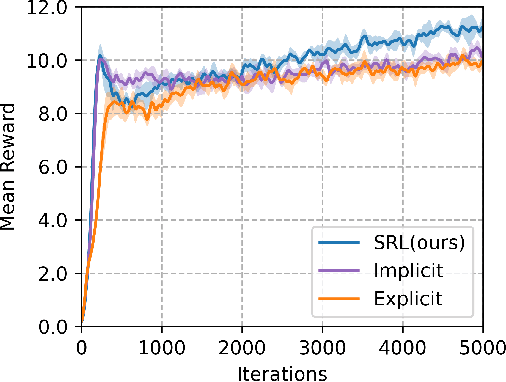
Traditional reinforcement learning control for quadruped robots often relies on privileged information, demanding meticulous selection and precise estimation, thereby imposing constraints on the development process. This work proposes a Self-learning Latent Representation (SLR) method, which achieves high-performance control policy learning without the need for privileged information. To enhance the credibility of our proposed method's evaluation, SLR is compared with open-source code repositories of state-of-the-art algorithms, retaining the original authors' configuration parameters. Across four repositories, SLR consistently outperforms the reference results. Ultimately, the trained policy and encoder empower the quadruped robot to navigate steps, climb stairs, ascend rocks, and traverse various challenging terrains. Robot experiment videos are at https://11chens.github.io/SLR/
Fine-Grained Cross-View Geo-Localization Using a Correlation-Aware Homography Estimator
Aug 31, 2023In this paper, we introduce a novel approach to fine-grained cross-view geo-localization. Our method aligns a warped ground image with a corresponding GPS-tagged satellite image covering the same area using homography estimation. We first employ a differentiable spherical transform, adhering to geometric principles, to accurately align the perspective of the ground image with the satellite map. This transformation effectively places ground and aerial images in the same view and on the same plane, reducing the task to an image alignment problem. To address challenges such as occlusion, small overlapping range, and seasonal variations, we propose a robust correlation-aware homography estimator to align similar parts of the transformed ground image with the satellite image. Our method achieves sub-pixel resolution and meter-level GPS accuracy by mapping the center point of the transformed ground image to the satellite image using a homography matrix and determining the orientation of the ground camera using a point above the central axis. Operating at a speed of 30 FPS, our method outperforms state-of-the-art techniques, reducing the mean metric localization error by 21.3% and 32.4% in same-area and cross-area generalization tasks on the VIGOR benchmark, respectively, and by 34.4% on the KITTI benchmark in same-area evaluation.
LP-SLAM: Language-Perceptive RGB-D SLAM system based on Large Language Model
Mar 17, 2023Simultaneous localization and mapping (SLAM) is a critical technology that enables autonomous robots to be aware of their surrounding environment. With the development of deep learning, SLAM systems can achieve a higher level of perception of the environment, including the semantic and text levels. However, current works are limited in their ability to achieve a natural-language level of perception of the world. To address this limitation, we propose LP-SLAM, the first language-perceptive SLAM system that leverages large language models (LLMs). LP-SLAM has two major features: (a) it can detect text in the scene and determine whether it represents a landmark to be stored during the tracking and mapping phase, and (b) it can understand natural language input from humans and provide guidance based on the generated map. We illustrated three usages of the LLM in the system including text cluster, landmark judgment, and natural language navigation. Our proposed system represents an advancement in the field of LLMs based SLAM and opens up new possibilities for autonomous robots to interact with their environment in a more natural and intuitive way.
Observation Contribution Theory for Pose Estimation Accuracy
Nov 15, 2021
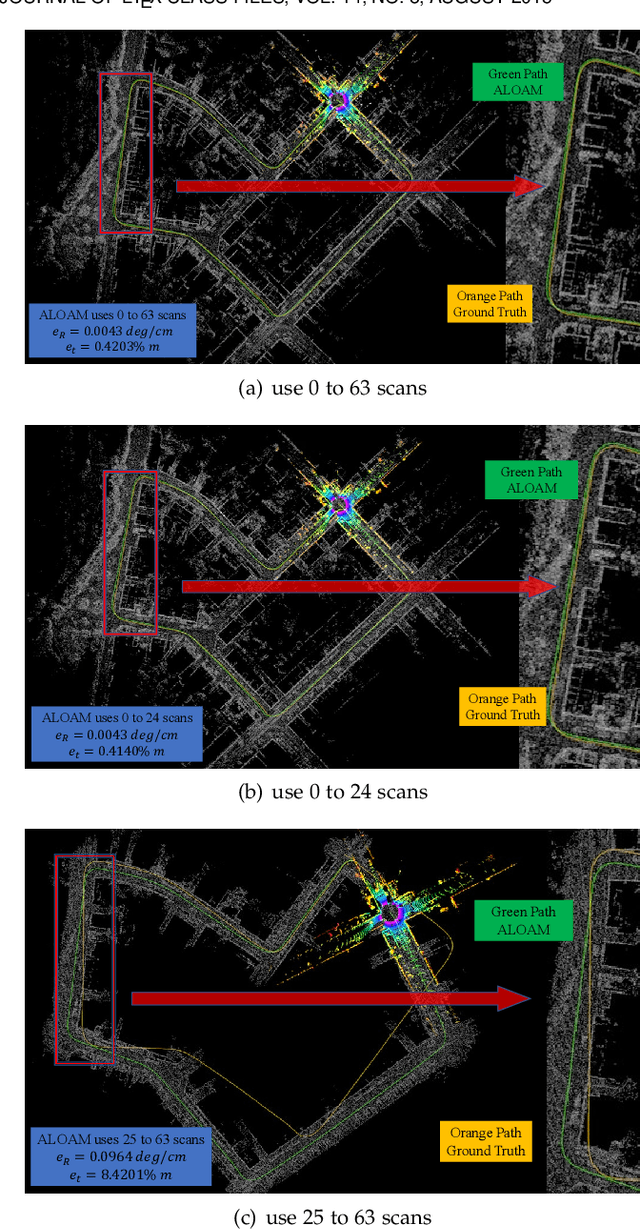

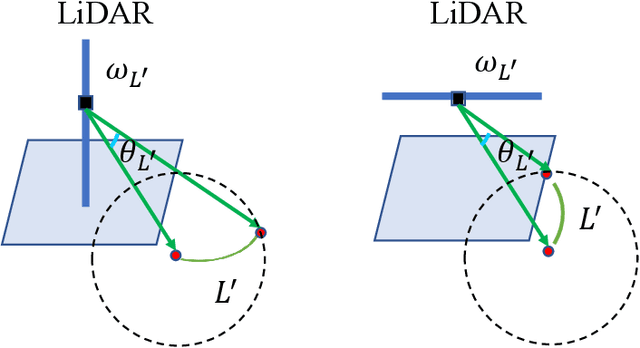
The improvement of pose estimation accuracy is currently the fundamental problem in mobile robots. This study aims to improve the use of observations to enhance accuracy. The selection of feature points affects the accuracy of pose estimation, leading to the question of how the contribution of observation influences the system. Accordingly, the contribution of information to the pose estimation process is analyzed. Moreover, the uncertainty model, sensitivity model, and contribution theory are formulated, providing a method for calculating the contribution of every residual term. The proposed selection method has been theoretically proven capable of achieving a global statistical optimum. The proposed method is tested on artificial data simulations and compared with the KITTI benchmark. The experiments revealed superior results in contrast to ALOAM and MLOAM. The proposed algorithm is implemented in LiDAR odometry and LiDAR Inertial odometry both indoors and outdoors using diverse LiDAR sensors with different scan modes, demonstrating its effectiveness in improving pose estimation accuracy. A new configuration of two laser scan sensors is subsequently inferred. The configuration is valid for three-dimensional pose localization in a prior map and yields results at the centimeter level.