 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBound-Constrained Sparse Representation for Electrical Impedance Tomography
May 27, 2026This study proposes a bound-constrained sparse representation (BC-SR) framework for electrical impedance tomography (EIT), aimed at improving conductivity estimation without explicit regularization. BC-SR adopts a representation-driven strategy, generating conductivity from low-dimensional latent variables via an implicit composite parameterization. Structural priors are embedded using a truncated graph-Laplacian basis, while a bound-preserving nonlinear mapping enforces admissible conductivity ranges and improves conditioning through implicit gradient modulation. The approach ensures robust convergence, even under noisy or incomplete data. Extensive validation on 2D/3D simulations, tank experiments, and in-vivo lung data shows that BC-SR improves physical consistency and structural fidelity, offering enhanced robustness compared to traditional methods. Additionally, BC-SR enables 3D time-difference EIT reconstruction, offering improved spatial resolution and a more coherent representation of 3D conductivity distributions, particularly for in-vivo lung data. This suggests potential for improved performance in EIT, particularly in clinical applications for respiratory monitoring.
SEA-Nav: Efficient Policy Learning for Safe and Agile Quadruped Navigation in Cluttered Environments
Mar 10, 2026Efficiently training quadruped robot navigation in densely cluttered environments remains a significant challenge. Existing methods are either limited by a lack of safety and agility in simple obstacle distributions or suffer from slow locomotion in complex environments, often requiring excessively long training phases. To this end, we propose SEA-Nav (Safe, Efficient, and Agile Navigation), a reinforcement learning framework for quadruped navigation. Within diverse and dense obstacle environments, a differentiable control barrier function (CBF)-based shield constraints the navigation policy to output safe velocity commands. An adaptive collision replay mechanism and hazardous exploration rewards are introduced to increase the probability of learning from critical experiences, guiding efficient exploration and exploitation. Finally, kinematic action constraints are incorporated to ensure safe velocity commands, facilitating successful physical deployment. To the best of our knowledge, this is the first approach that achieves highly challenging quadruped navigation in the real world with minute-level training time.
\$OneMillion-Bench: How Far are Language Agents from Human Experts?
Mar 09, 2026As language models (LMs) evolve from chat assistants to long-horizon agents capable of multi-step reasoning and tool use, existing benchmarks remain largely confined to structured or exam-style tasks that fall short of real-world professional demands. To this end, we introduce \$OneMillion-Bench \$OneMillion-Bench, a benchmark of 400 expert-curated tasks spanning Law, Finance, Industry, Healthcare, and Natural Science, built to evaluate agents across economically consequential scenarios. Unlike prior work, the benchmark requires retrieving authoritative sources, resolving conflicting evidence, applying domain-specific rules, and making constraint decisions, where correctness depends as much on the reasoning process as the final answer. We adopt a rubric-based evaluation protocol scoring factual accuracy, logical coherence, practical feasibility, and professional compliance, focused on expert-level problems to ensure meaningful differentiation across agents. Together, \$OneMillion-Bench provides a unified testbed for assessing agentic reliability, professional depth, and practical readiness in domain-intensive scenarios.
SD-MoE: Spectral Decomposition for Effective Expert Specialization
Feb 13, 2026Mixture-of-Experts (MoE) architectures scale Large Language Models via expert specialization induced by conditional computation. In practice, however, expert specialization often fails: some experts become functionally similar, while others functioning as de facto shared experts, limiting the effective capacity and model performance. In this work, we analysis from a spectral perspective on parameter and gradient spaces, uncover that (1) experts share highly overlapping dominant spectral components in their parameters, (2) dominant gradient subspaces are strongly aligned across experts, driven by ubiquitous low-rank structure in human corpus, and (3) gating mechanisms preferentially route inputs along these dominant directions, further limiting specialization. To address this, we propose Spectral-Decoupled MoE (SD-MoE), which decomposes both parameter and gradient in the spectral space. SD-MoE improves performance across downstream tasks, enables effective expert specialization, incurring minimal additional computation, and can be seamlessly integrated into a wide range of existing MoE architectures, including Qwen and DeepSeek.
SuperGPQA: Scaling LLM Evaluation across 285 Graduate Disciplines
Feb 20, 2025Large language models (LLMs) have demonstrated remarkable proficiency in mainstream academic disciplines such as mathematics, physics, and computer science. However, human knowledge encompasses over 200 specialized disciplines, far exceeding the scope of existing benchmarks. The capabilities of LLMs in many of these specialized fields-particularly in light industry, agriculture, and service-oriented disciplines-remain inadequately evaluated. To address this gap, we present SuperGPQA, a comprehensive benchmark that evaluates graduate-level knowledge and reasoning capabilities across 285 disciplines. Our benchmark employs a novel Human-LLM collaborative filtering mechanism to eliminate trivial or ambiguous questions through iterative refinement based on both LLM responses and expert feedback. Our experimental results reveal significant room for improvement in the performance of current state-of-the-art LLMs across diverse knowledge domains (e.g., the reasoning-focused model DeepSeek-R1 achieved the highest accuracy of 61.82% on SuperGPQA), highlighting the considerable gap between current model capabilities and artificial general intelligence. Additionally, we present comprehensive insights from our management of a large-scale annotation process, involving over 80 expert annotators and an interactive Human-LLM collaborative system, offering valuable methodological guidance for future research initiatives of comparable scope.
MGSA: Multi-granularity Graph Structure Attention for Knowledge Graph-to-Text Generation
Sep 16, 2024


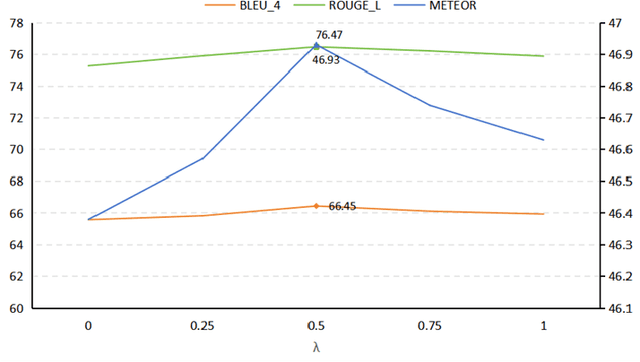
The Knowledge Graph-to-Text Generation task aims to convert structured knowledge graphs into coherent and human-readable natural language text. Recent efforts in this field have focused on enhancing pre-trained language models (PLMs) by incorporating graph structure information to capture the intricate structure details of knowledge graphs. However, most of these approaches tend to capture only single-granularity structure information, concentrating either on the relationships between entities within the original graph or on the relationships between words within the same entity or across different entities. This narrow focus results in a significant limitation: models that concentrate solely on entity-level structure fail to capture the nuanced semantic relationships between words, while those that focus only on word-level structure overlook the broader relationships between original entire entities. To overcome these limitations, this paper introduces the Multi-granularity Graph Structure Attention (MGSA), which is based on PLMs. The encoder of the model architecture features an entity-level structure encoding module, a word-level structure encoding module, and an aggregation module that synthesizes information from both structure. This multi-granularity structure encoding approach allows the model to simultaneously capture both entity-level and word-level structure information, providing a more comprehensive understanding of the knowledge graph's structure information, thereby significantly improving the quality of the generated text. We conducted extensive evaluations of the MGSA model using two widely recognized KG-to-Text Generation benchmark datasets, WebNLG and EventNarrative, where it consistently outperformed models that rely solely on single-granularity structure information, demonstrating the effectiveness of our approach.
SLR: Learning Quadruped Locomotion without Privileged Information
Jun 07, 2024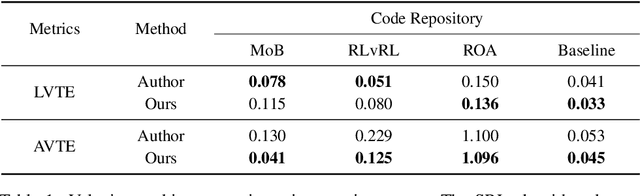
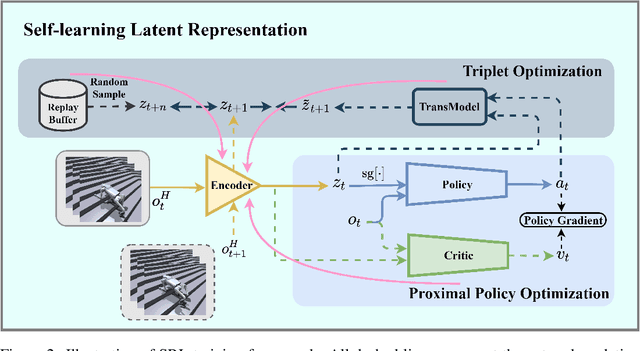
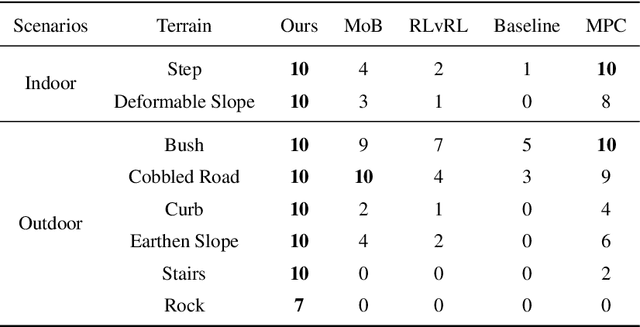
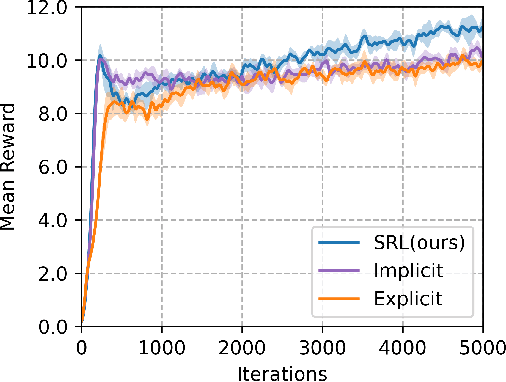
Traditional reinforcement learning control for quadruped robots often relies on privileged information, demanding meticulous selection and precise estimation, thereby imposing constraints on the development process. This work proposes a Self-learning Latent Representation (SLR) method, which achieves high-performance control policy learning without the need for privileged information. To enhance the credibility of our proposed method's evaluation, SLR is compared with open-source code repositories of state-of-the-art algorithms, retaining the original authors' configuration parameters. Across four repositories, SLR consistently outperforms the reference results. Ultimately, the trained policy and encoder empower the quadruped robot to navigate steps, climb stairs, ascend rocks, and traverse various challenging terrains. Robot experiment videos are at https://11chens.github.io/SLR/
LP-SLAM: Language-Perceptive RGB-D SLAM system based on Large Language Model
Mar 17, 2023Simultaneous localization and mapping (SLAM) is a critical technology that enables autonomous robots to be aware of their surrounding environment. With the development of deep learning, SLAM systems can achieve a higher level of perception of the environment, including the semantic and text levels. However, current works are limited in their ability to achieve a natural-language level of perception of the world. To address this limitation, we propose LP-SLAM, the first language-perceptive SLAM system that leverages large language models (LLMs). LP-SLAM has two major features: (a) it can detect text in the scene and determine whether it represents a landmark to be stored during the tracking and mapping phase, and (b) it can understand natural language input from humans and provide guidance based on the generated map. We illustrated three usages of the LLM in the system including text cluster, landmark judgment, and natural language navigation. Our proposed system represents an advancement in the field of LLMs based SLAM and opens up new possibilities for autonomous robots to interact with their environment in a more natural and intuitive way.
A simple normalization technique using window statistics to improve the out-of-distribution generalization on medical images
Jul 14, 2022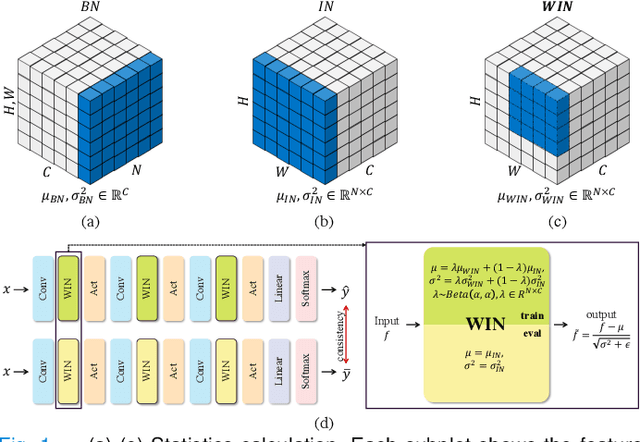
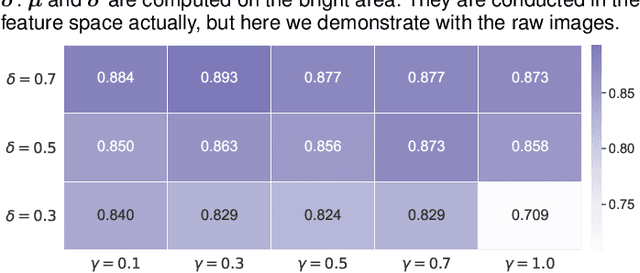

Since data scarcity and data heterogeneity are prevailing for medical images, well-trained Convolutional Neural Networks (CNNs) using previous normalization methods may perform poorly when deployed to a new site. However, a reliable model for real-world clinical applications should be able to generalize well both on in-distribution (IND) and out-of-distribution (OOD) data (e.g., the new site data). In this study, we present a novel normalization technique called window normalization (WIN) to improve the model generalization on heterogeneous medical images, which is a simple yet effective alternative to existing normalization methods. Specifically, WIN perturbs the normalizing statistics with the local statistics computed on the window of features. This feature-level augmentation technique regularizes the models well and improves their OOD generalization significantly. Taking its advantage, we propose a novel self-distillation method called WIN-WIN for classification tasks. WIN-WIN is easily implemented with twice forward passes and a consistency constraint, which can be a simple extension for existing methods. Extensive experimental results on various tasks (6 tasks) and datasets (24 datasets) demonstrate the generality and effectiveness of our methods.
Long-term prediction of chaotic systems with recurrent neural networks
Mar 06, 2020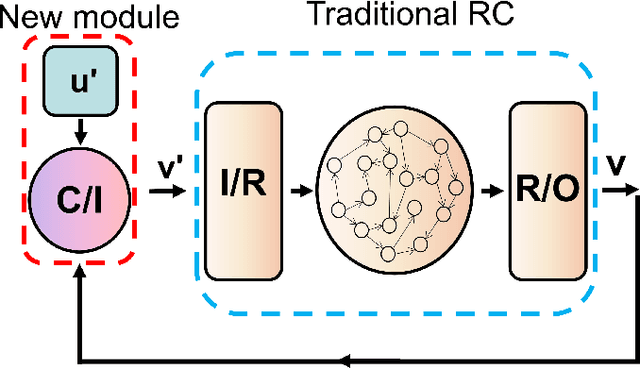

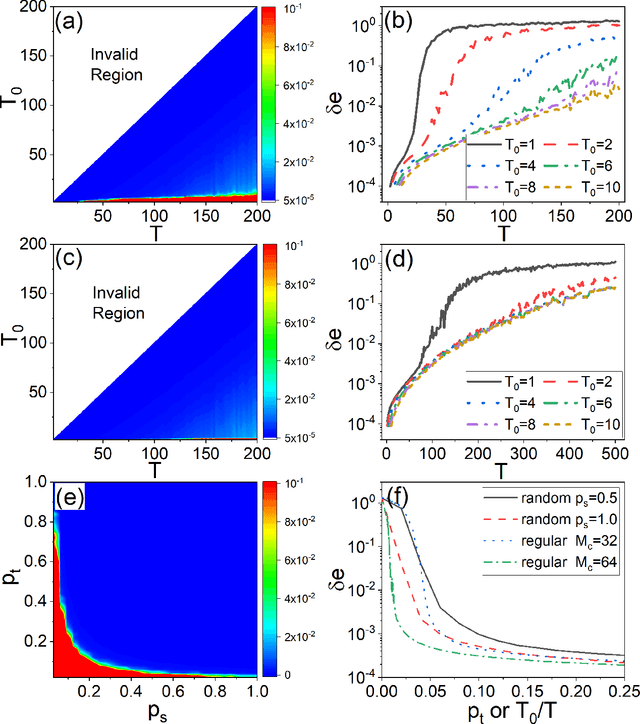

Reservoir computing systems, a class of recurrent neural networks, have recently been exploited for model-free, data-based prediction of the state evolution of a variety of chaotic dynamical systems. The prediction horizon demonstrated has been about half dozen Lyapunov time. Is it possible to significantly extend the prediction time beyond what has been achieved so far? We articulate a scheme incorporating time-dependent but sparse data inputs into reservoir computing and demonstrate that such rare "updates" of the actual state practically enable an arbitrarily long prediction horizon for a variety of chaotic systems. A physical understanding based on the theory of temporal synchronization is developed.