 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePaperFit: Vision-in-the-Loop Typesetting Optimization for Scientific Documents
May 11, 2026A LaTeX manuscript that compiles without error is not necessarily publication-ready. The resulting PDFs frequently suffer from misplaced floats, overflowing equations, inconsistent table scaling, widow and orphan lines, and poor page balance, forcing authors into repetitive compile-inspect-edit cycles. Rule-based tools are blind to rendered visuals, operating only on source code and log files. Text-only LLMs perform open-loop text editing, unable to predict or verify the two-dimensional layout consequences of their changes. Reliable typesetting optimization therefore requires a visual closed loop with verification after every edit. We formalize this problem as Visual Typesetting Optimization (VTO), the task of transforming a compilable LaTeX paper into a visually polished, page-budget-compliant PDF through iterative visual verification and source-level revision, and introduce a five-category taxonomy of typesetting defects to guide diagnosis. We present PaperFit, a vision-in-the-loop agent that iteratively renders pages, diagnoses defects, and applies constrained repairs. To benchmark VTO, we construct PaperFit-Bench with 200 papers across 10 venue templates and 13 defect types at different difficulty. Extensive experiments show that PaperFit outperforms all baselines by a large margin, establishing that bridging the gap from compilable source to publication-ready PDF requires vision-in-the-loop optimization and that VTO constitutes a critical missing stage in the document automation pipeline.
Machine intelligence supports the full chain of 2D dendrite synthesis
Mar 17, 2026Exemplified by the chemical vapor deposition growth of two-dimensional dendrites, which has potential applications in catalysis and presents a parameter-intensive, data-scarce and reaction process-complex model problem, we devise a machine intelligence-empowered framework for the full chain support of material synthesis, encompassing rapid process optimization, accurate customized synthesis, and comprehensive mechanism deciphering.First, active learning is integrated into the experimental workflow, identifying an optimal recipe for the growth of highly-branched, electrocatalytically-active ReSe2 dendrites through 60 experiments (4 iterations), which account for less than 1.3% of the numerous possible parameter combinations.Then, a prediction accuracy-guided data augmentation strategy is developed combined with a tree-based machine learning (ML) algorithm, unveiling a non-linear correlation between 5 process variables and fractal dimension (DF) of ReSe2 dendrites with only 9 experiment additions, which guides the synthesis of various user-defined DF. Finally, we construct a data-knowledge dual-driven mechanism model by integration of cross-scale characterizations, interpretable ML models, and domain knowledge in thermodynamics and kinetics, unraveling synergistic contributions of multiple process parameters to the product morphology. This work demonstrates the ML potential to transform the research paradigm and is adaptable to broader material synthesis.
The Trinity of Consistency as a Defining Principle for General World Models
Feb 26, 2026The construction of World Models capable of learning, simulating, and reasoning about objective physical laws constitutes a foundational challenge in the pursuit of Artificial General Intelligence. Recent advancements represented by video generation models like Sora have demonstrated the potential of data-driven scaling laws to approximate physical dynamics, while the emerging Unified Multimodal Model (UMM) offers a promising architectural paradigm for integrating perception, language, and reasoning. Despite these advances, the field still lacks a principled theoretical framework that defines the essential properties requisite for a General World Model. In this paper, we propose that a World Model must be grounded in the Trinity of Consistency: Modal Consistency as the semantic interface, Spatial Consistency as the geometric basis, and Temporal Consistency as the causal engine. Through this tripartite lens, we systematically review the evolution of multimodal learning, revealing a trajectory from loosely coupled specialized modules toward unified architectures that enable the synergistic emergence of internal world simulators. To complement this conceptual framework, we introduce CoW-Bench, a benchmark centered on multi-frame reasoning and generation scenarios. CoW-Bench evaluates both video generation models and UMMs under a unified evaluation protocol. Our work establishes a principled pathway toward general world models, clarifying both the limitations of current systems and the architectural requirements for future progress.
Training deep physical neural networks with local physical information bottleneck
Feb 10, 2026Deep learning has revolutionized modern society but faces growing energy and latency constraints. Deep physical neural networks (PNNs) are interconnected computing systems that directly exploit analog dynamics for energy-efficient, ultrafast AI execution. Realizing this potential, however, requires universal training methods tailored to physical intricacies. Here, we present the Physical Information Bottleneck (PIB), a general and efficient framework that integrates information theory and local learning, enabling deep PNNs to learn under arbitrary physical dynamics. By allocating matrix-based information bottlenecks to each unit, we demonstrate supervised, unsupervised, and reinforcement learning across electronic memristive chips and optical computing platforms. PIB also adapts to severe hardware faults and allows for parallel training via geographically distributed resources. Bypassing auxiliary digital models and contrastive measurements, PIB recasts PNN training as an intrinsic, scalable information-theoretic process compatible with diverse physical substrates.
GPF-Net: Gated Progressive Fusion Learning for Polyp Re-Identification
Dec 25, 2025Colonoscopic Polyp Re-Identification aims to match the same polyp from a large gallery with images from different views taken using different cameras, which plays an important role in the prevention and treatment of colorectal cancer in computer-aided diagnosis. However, the coarse resolution of high-level features of a specific polyp often leads to inferior results for small objects where detailed information is important. To address this challenge, we propose a novel architecture, named Gated Progressive Fusion network, to selectively fuse features from multiple levels using gates in a fully connected way for polyp ReID. On the basis of it, a gated progressive fusion strategy is introduced to achieve layer-wise refinement of semantic information through multi-level feature interactions. Experiments on standard benchmarks show the benefits of the multimodal setting over state-of-the-art unimodal ReID models, especially when combined with the specialized multimodal fusion strategy.
Improving Pattern Recognition of Scheduling Anomalies through Structure-Aware and Semantically-Enhanced Graphs
Dec 21, 2025This paper proposes a structure-aware driven scheduling graph modeling method to improve the accuracy and representation capability of anomaly identification in scheduling behaviors of complex systems. The method first designs a structure-guided scheduling graph construction mechanism that integrates task execution stages, resource node states, and scheduling path information to build dynamically evolving scheduling behavior graphs, enhancing the model's ability to capture global scheduling relationships. On this basis, a multi-scale graph semantic aggregation module is introduced to achieve semantic consistency modeling of scheduling features through local adjacency semantic integration and global topology alignment, thereby strengthening the model's capability to capture abnormal features in complex scenarios such as multi-task concurrency, resource competition, and stage transitions. Experiments are conducted on a real scheduling dataset with multiple scheduling disturbance paths set to simulate different types of anomalies, including structural shifts, resource changes, and task delays. The proposed model demonstrates significant performance advantages across multiple metrics, showing a sensitive response to structural disturbances and semantic shifts. Further visualization analysis reveals that, under the combined effect of structure guidance and semantic aggregation, the scheduling behavior graph exhibits stronger anomaly separability and pattern representation, validating the effectiveness and adaptability of the method in scheduling anomaly detection tasks.
ACPO: Adaptive Curriculum Policy Optimization for Aligning Vision-Language Models in Complex Reasoning
Oct 01, 2025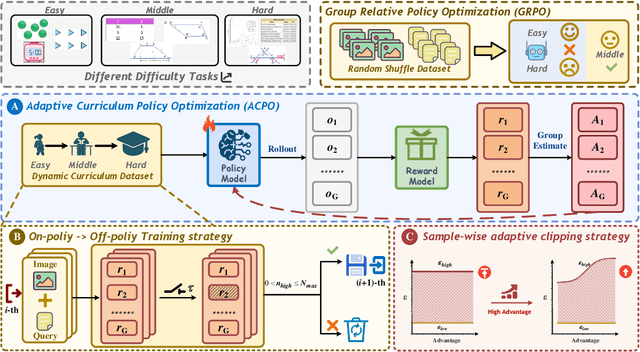


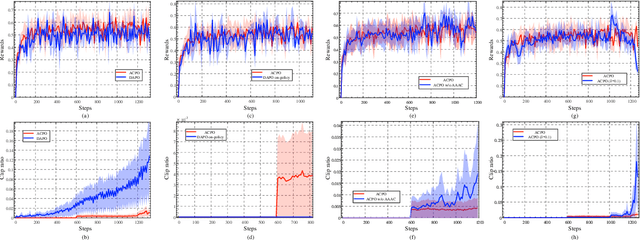
Aligning large-scale vision-language models (VLMs) for complex reasoning via reinforcement learning is often hampered by the limitations of existing policy optimization algorithms, such as static training schedules and the rigid, uniform clipping mechanism in Proximal Policy Optimization (PPO). In this work, we introduce Adaptive Curriculum Policy Optimization (ACPO), a novel framework that addresses these challenges through a dual-component adaptive learning strategy. First, ACPO employs a dynamic curriculum that orchestrates a principled transition from a stable, near on-policy exploration phase to an efficient, off-policy exploitation phase by progressively increasing sample reuse. Second, we propose an Advantage-Aware Adaptive Clipping (AAAC) mechanism that replaces the fixed clipping hyperparameter with dynamic, sample-wise bounds modulated by the normalized advantage of each token. This allows for more granular and robust policy updates, enabling larger gradients for high-potential samples while safeguarding against destructive ones. We conduct extensive experiments on a suite of challenging multimodal reasoning benchmarks, including MathVista, LogicVista, and MMMU-Pro. Results demonstrate that ACPO consistently outperforms strong baselines such as DAPO and PAPO, achieving state-of-the-art performance, accelerated convergence, and superior training stability.
Nonlinear Motion-Guided and Spatio-Temporal Aware Network for Unsupervised Event-Based Optical Flow
May 08, 2025Event cameras have the potential to capture continuous motion information over time and space, making them well-suited for optical flow estimation. However, most existing learning-based methods for event-based optical flow adopt frame-based techniques, ignoring the spatio-temporal characteristics of events. Additionally, these methods assume linear motion between consecutive events within the loss time window, which increases optical flow errors in long-time sequences. In this work, we observe that rich spatio-temporal information and accurate nonlinear motion between events are crucial for event-based optical flow estimation. Therefore, we propose E-NMSTFlow, a novel unsupervised event-based optical flow network focusing on long-time sequences. We propose a Spatio-Temporal Motion Feature Aware (STMFA) module and an Adaptive Motion Feature Enhancement (AMFE) module, both of which utilize rich spatio-temporal information to learn spatio-temporal data associations. Meanwhile, we propose a nonlinear motion compensation loss that utilizes the accurate nonlinear motion between events to improve the unsupervised learning of our network. Extensive experiments demonstrate the effectiveness and superiority of our method. Remarkably, our method ranks first among unsupervised learning methods on the MVSEC and DSEC-Flow datasets. Our project page is available at https://wynelio.github.io/E-NMSTFlow.
SAM2MOT: A Novel Paradigm of Multi-Object Tracking by Segmentation
Apr 06, 2025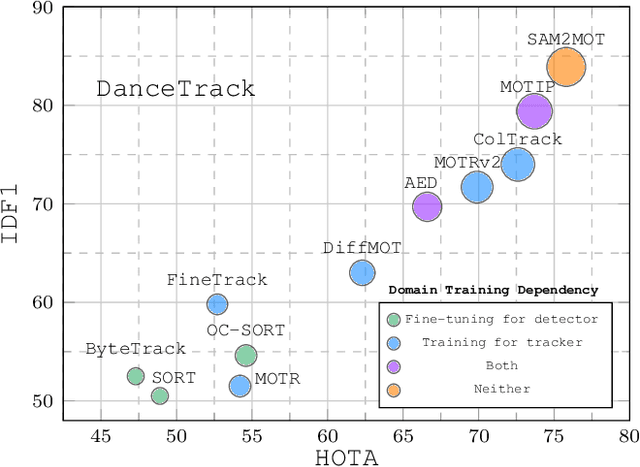
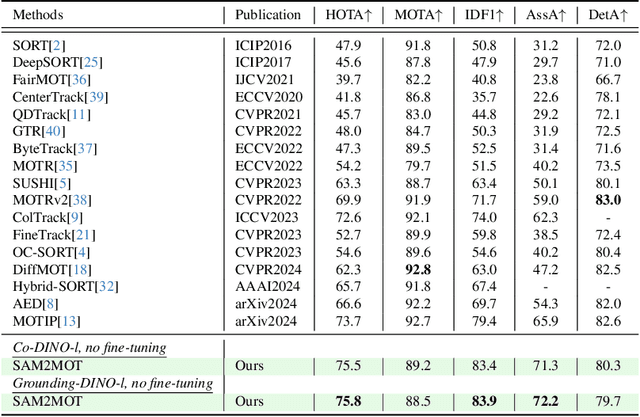
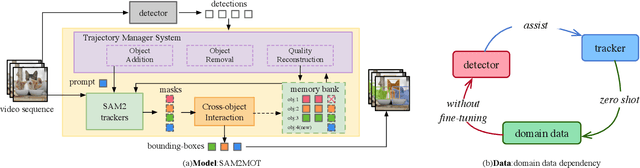
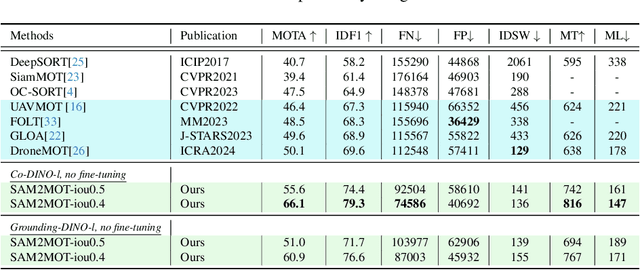
Segment Anything 2 (SAM2) enables robust single-object tracking using segmentation. To extend this to multi-object tracking (MOT), we propose SAM2MOT, introducing a novel Tracking by Segmentation paradigm. Unlike Tracking by Detection or Tracking by Query, SAM2MOT directly generates tracking boxes from segmentation masks, reducing reliance on detection accuracy. SAM2MOT has two key advantages: zero-shot generalization, allowing it to work across datasets without fine-tuning, and strong object association, inherited from SAM2. To further improve performance, we integrate a trajectory manager system for precise object addition and removal, and a cross-object interaction module to handle occlusions. Experiments on DanceTrack, UAVDT, and BDD100K show state-of-the-art results. Notably, SAM2MOT outperforms existing methods on DanceTrack by +2.1 HOTA and +4.5 IDF1, highlighting its effectiveness in MOT.
Optimal Brain Apoptosis
Feb 25, 2025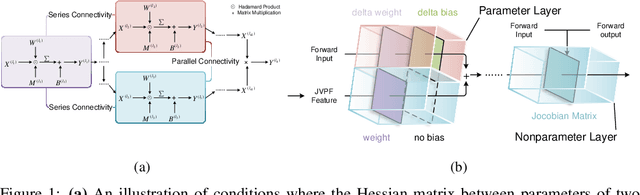
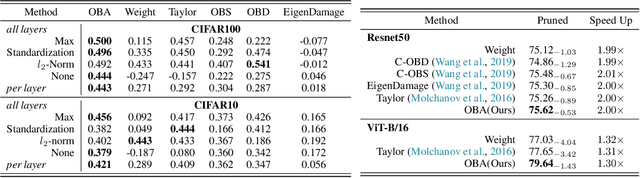
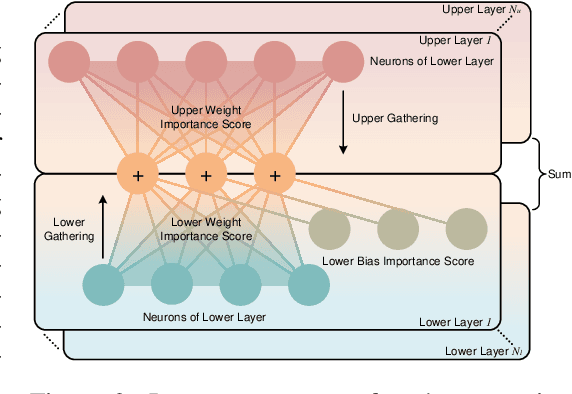
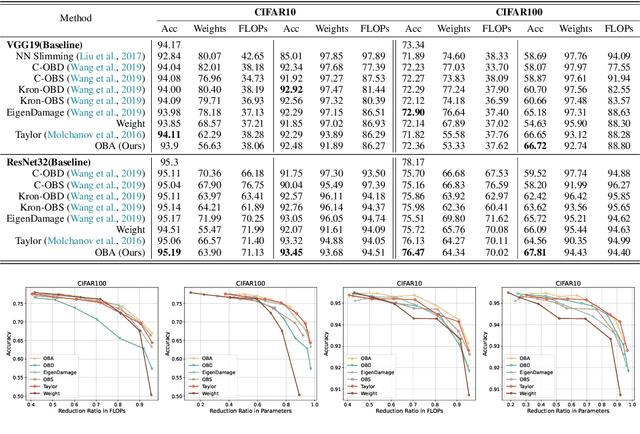
The increasing complexity and parameter count of Convolutional Neural Networks (CNNs) and Transformers pose challenges in terms of computational efficiency and resource demands. Pruning has been identified as an effective strategy to address these challenges by removing redundant elements such as neurons, channels, or connections, thereby enhancing computational efficiency without heavily compromising performance. This paper builds on the foundational work of Optimal Brain Damage (OBD) by advancing the methodology of parameter importance estimation using the Hessian matrix. Unlike previous approaches that rely on approximations, we introduce Optimal Brain Apoptosis (OBA), a novel pruning method that calculates the Hessian-vector product value directly for each parameter. By decomposing the Hessian matrix across network layers and identifying conditions under which inter-layer Hessian submatrices are non-zero, we propose a highly efficient technique for computing the second-order Taylor expansion of parameters. This approach allows for a more precise pruning process, particularly in the context of CNNs and Transformers, as validated in our experiments including VGG19, ResNet32, ResNet50, and ViT-B/16 on CIFAR10, CIFAR100 and Imagenet datasets. Our code is available at https://github.com/NEU-REAL/OBA.