 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics-Informed Neural Networks for Device and Circuit Modeling: A Case Study of NeuroSPICE
Dec 31, 2025We present NeuroSPICE, a physics-informed neural network (PINN) framework for device and circuit simulation. Unlike conventional SPICE, which relies on time-discretized numerical solvers, NeuroSPICE leverages PINNs to solve circuit differential-algebraic equations (DAEs) by minimizing the residual of the equations through backpropagation. It models device and circuit waveforms using analytical equations in time domain with exact temporal derivatives. While PINNs do not outperform SPICE in speed or accuracy during training, they offer unique advantages such as surrogate models for design optimization and inverse problems. NeuroSPICE's flexibility enables the simulation of emerging devices, including highly nonlinear systems such as ferroelectric memories.
Optimal Brain Apoptosis
Feb 25, 2025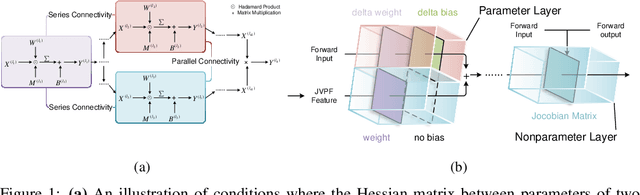
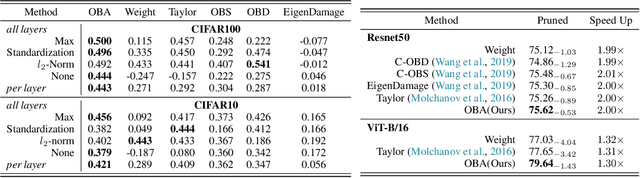
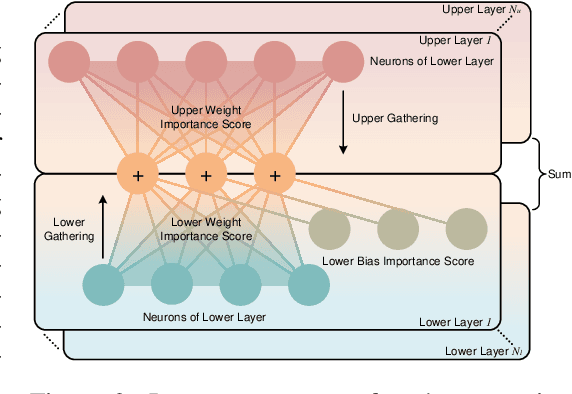
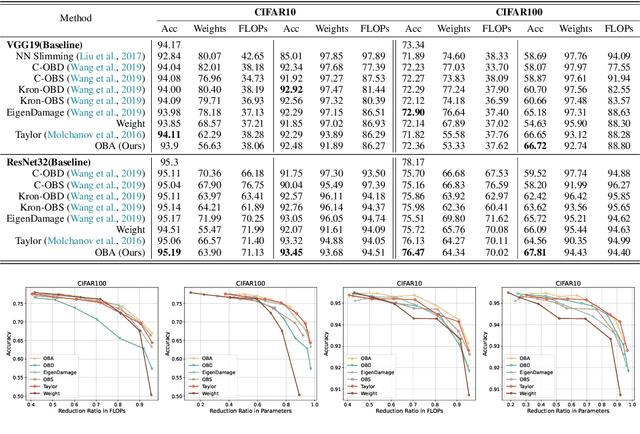
The increasing complexity and parameter count of Convolutional Neural Networks (CNNs) and Transformers pose challenges in terms of computational efficiency and resource demands. Pruning has been identified as an effective strategy to address these challenges by removing redundant elements such as neurons, channels, or connections, thereby enhancing computational efficiency without heavily compromising performance. This paper builds on the foundational work of Optimal Brain Damage (OBD) by advancing the methodology of parameter importance estimation using the Hessian matrix. Unlike previous approaches that rely on approximations, we introduce Optimal Brain Apoptosis (OBA), a novel pruning method that calculates the Hessian-vector product value directly for each parameter. By decomposing the Hessian matrix across network layers and identifying conditions under which inter-layer Hessian submatrices are non-zero, we propose a highly efficient technique for computing the second-order Taylor expansion of parameters. This approach allows for a more precise pruning process, particularly in the context of CNNs and Transformers, as validated in our experiments including VGG19, ResNet32, ResNet50, and ViT-B/16 on CIFAR10, CIFAR100 and Imagenet datasets. Our code is available at https://github.com/NEU-REAL/OBA.
Fully Asynchronous Neuromorphic Perception for Mobile Robot Dodging with Loihi Chips
Oct 14, 2024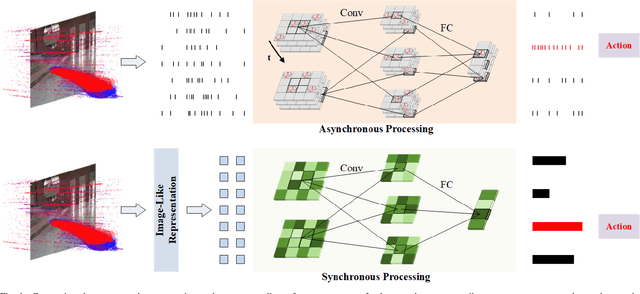
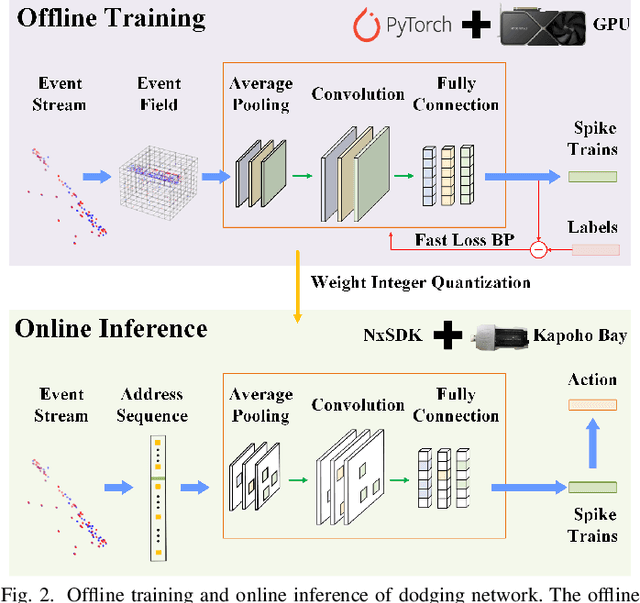
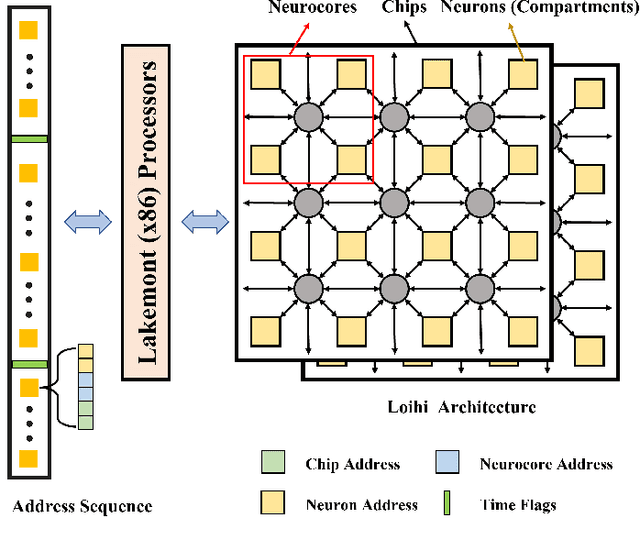
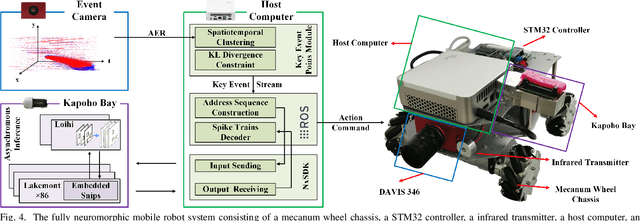
Sparse and asynchronous sensing and processing in natural organisms lead to ultra low-latency and energy-efficient perception. Event cameras, known as neuromorphic vision sensors, are designed to mimic these characteristics. However, fully utilizing the sparse and asynchronous event stream remains challenging. Influenced by the mature algorithms of standard cameras, most existing event-based algorithms still rely on the "group of events" processing paradigm (e.g., event frames, 3D voxels) when handling event streams. This paradigm encounters issues such as feature loss, event stacking, and high computational burden, which deviates from the intended purpose of event cameras. To address these issues, we propose a fully asynchronous neuromorphic paradigm that integrates event cameras, spiking networks, and neuromorphic processors (Intel Loihi). This paradigm can faithfully process each event asynchronously as it arrives, mimicking the spike-driven signal processing in biological brains. We compare the proposed paradigm with the existing "group of events" processing paradigm in detail on the real mobile robot dodging task. Experimental results show that our scheme exhibits better robustness than frame-based methods with different time windows and light conditions. Additionally, the energy consumption per inference of our scheme on the embedded Loihi processor is only 4.30% of that of the event spike tensor method on NVIDIA Jetson Orin NX with energy-saving mode, and 1.64% of that of the event frame method on the same neuromorphic processor. As far as we know, this is the first time that a fully asynchronous neuromorphic paradigm has been implemented for solving sequential tasks on real mobile robot.
Spike-EVPR: Deep Spiking Residual Network with Cross-Representation Aggregation for Event-Based Visual Place Recognition
Feb 16, 2024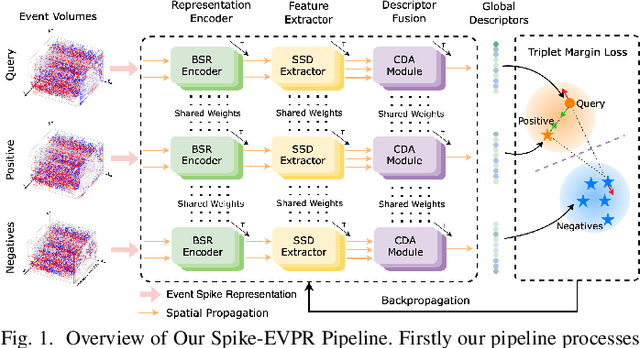
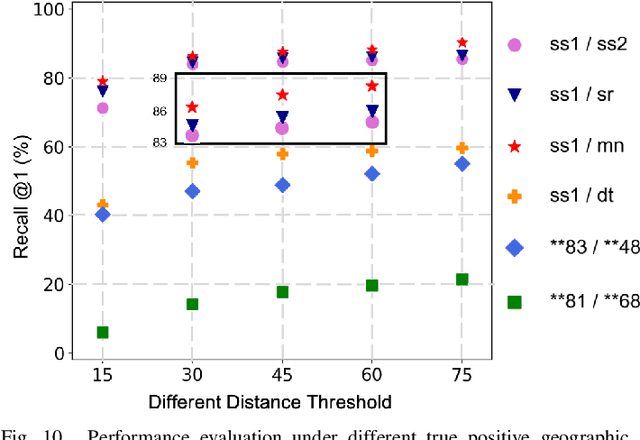
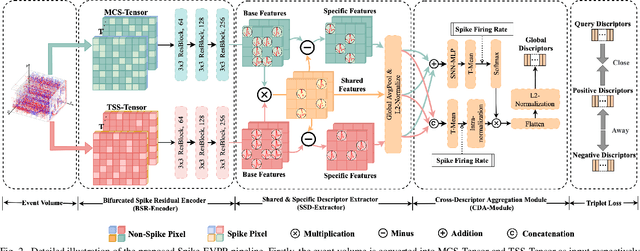
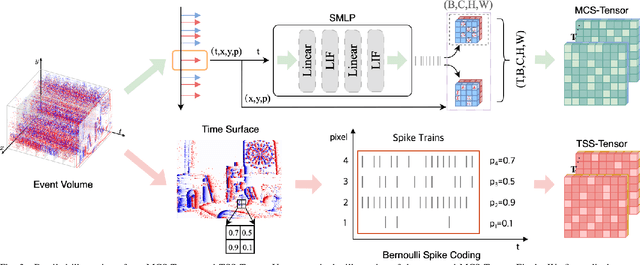
Event cameras have been successfully applied to visual place recognition (VPR) tasks by using deep artificial neural networks (ANNs) in recent years. However, previously proposed deep ANN architectures are often unable to harness the abundant temporal information presented in event streams. In contrast, deep spiking networks exhibit more intricate spatiotemporal dynamics and are inherently well-suited to process sparse asynchronous event streams. Unfortunately, directly inputting temporal-dense event volumes into the spiking network introduces excessive time steps, resulting in prohibitively high training costs for large-scale VPR tasks. To address the aforementioned issues, we propose a novel deep spiking network architecture called Spike-EVPR for event-based VPR tasks. First, we introduce two novel event representations tailored for SNN to fully exploit the spatio-temporal information from the event streams, and reduce the video memory occupation during training as much as possible. Then, to exploit the full potential of these two representations, we construct a Bifurcated Spike Residual Encoder (BSR-Encoder) with powerful representational capabilities to better extract the high-level features from the two event representations. Next, we introduce a Shared & Specific Descriptor Extractor (SSD-Extractor). This module is designed to extract features shared between the two representations and features specific to each. Finally, we propose a Cross-Descriptor Aggregation Module (CDA-Module) that fuses the above three features to generate a refined, robust global descriptor of the scene. Our experimental results indicate the superior performance of our Spike-EVPR compared to several existing EVPR pipelines on Brisbane-Event-VPR and DDD20 datasets, with the average Recall@1 increased by 7.61% on Brisbane and 13.20% on DDD20.
EV-MGRFlowNet: Motion-Guided Recurrent Network for Unsupervised Event-based Optical Flow with Hybrid Motion-Compensation Loss
May 13, 2023



Event cameras offer promising properties, such as high temporal resolution and high dynamic range. These benefits have been utilized into many machine vision tasks, especially optical flow estimation. Currently, most existing event-based works use deep learning to estimate optical flow. However, their networks have not fully exploited prior hidden states and motion flows. Additionally, their supervision strategy has not fully leveraged the geometric constraints of event data to unlock the potential of networks. In this paper, we propose EV-MGRFlowNet, an unsupervised event-based optical flow estimation pipeline with motion-guided recurrent networks using a hybrid motion-compensation loss. First, we propose a feature-enhanced recurrent encoder network (FERE-Net) which fully utilizes prior hidden states to obtain multi-level motion features. Then, we propose a flow-guided decoder network (FGD-Net) to integrate prior motion flows. Finally, we design a hybrid motion-compensation loss (HMC-Loss) to strengthen geometric constraints for the more accurate alignment of events. Experimental results show that our method outperforms the current state-of-the-art (SOTA) method on the MVSEC dataset, with an average reduction of approximately 22.71% in average endpoint error (AEE). To our knowledge, our method ranks first among unsupervised learning-based methods.