 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Brain Apoptosis
Feb 25, 2025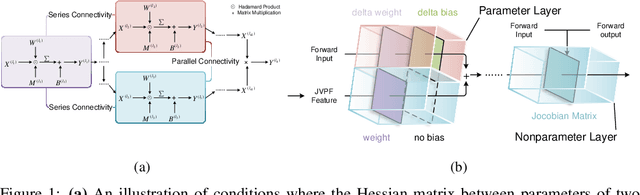
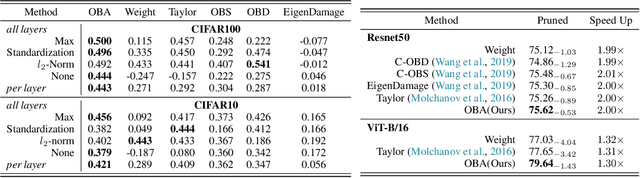
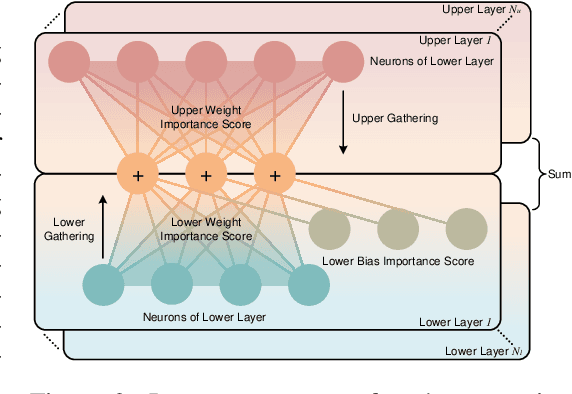
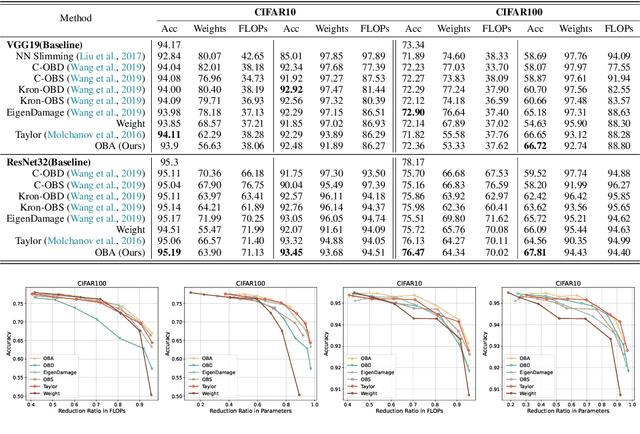
The increasing complexity and parameter count of Convolutional Neural Networks (CNNs) and Transformers pose challenges in terms of computational efficiency and resource demands. Pruning has been identified as an effective strategy to address these challenges by removing redundant elements such as neurons, channels, or connections, thereby enhancing computational efficiency without heavily compromising performance. This paper builds on the foundational work of Optimal Brain Damage (OBD) by advancing the methodology of parameter importance estimation using the Hessian matrix. Unlike previous approaches that rely on approximations, we introduce Optimal Brain Apoptosis (OBA), a novel pruning method that calculates the Hessian-vector product value directly for each parameter. By decomposing the Hessian matrix across network layers and identifying conditions under which inter-layer Hessian submatrices are non-zero, we propose a highly efficient technique for computing the second-order Taylor expansion of parameters. This approach allows for a more precise pruning process, particularly in the context of CNNs and Transformers, as validated in our experiments including VGG19, ResNet32, ResNet50, and ViT-B/16 on CIFAR10, CIFAR100 and Imagenet datasets. Our code is available at https://github.com/NEU-REAL/OBA.
Fully Asynchronous Neuromorphic Perception for Mobile Robot Dodging with Loihi Chips
Oct 14, 2024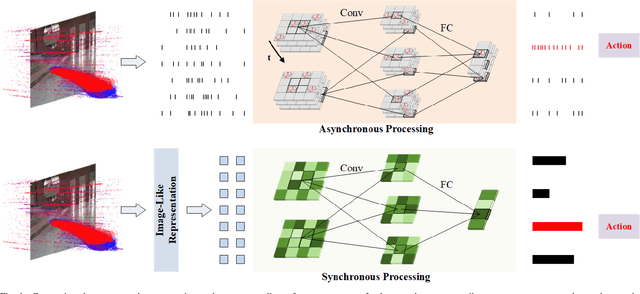
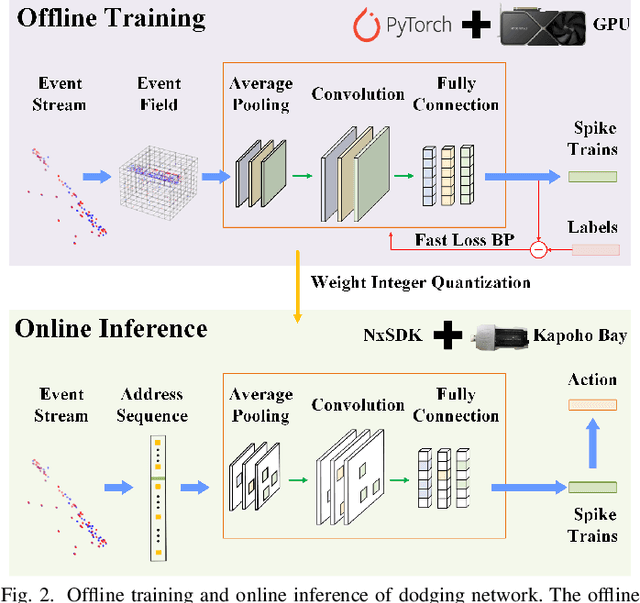
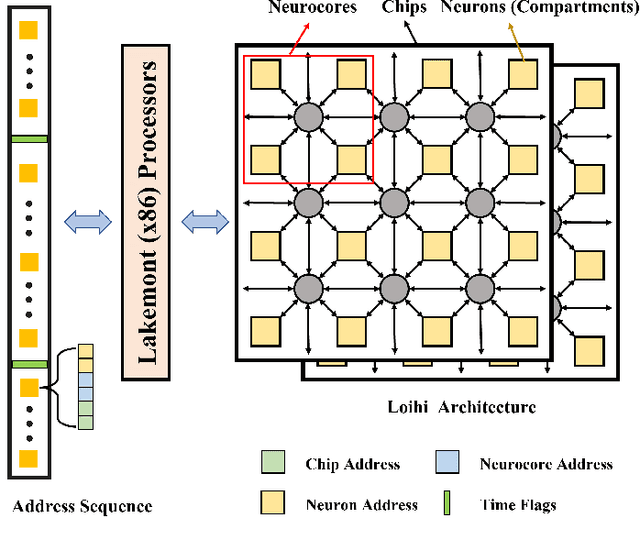
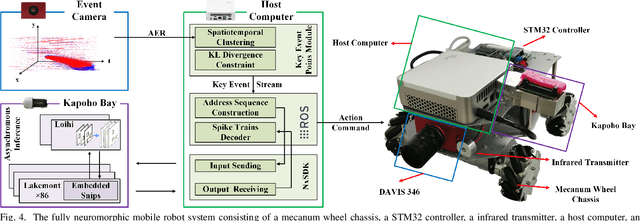
Sparse and asynchronous sensing and processing in natural organisms lead to ultra low-latency and energy-efficient perception. Event cameras, known as neuromorphic vision sensors, are designed to mimic these characteristics. However, fully utilizing the sparse and asynchronous event stream remains challenging. Influenced by the mature algorithms of standard cameras, most existing event-based algorithms still rely on the "group of events" processing paradigm (e.g., event frames, 3D voxels) when handling event streams. This paradigm encounters issues such as feature loss, event stacking, and high computational burden, which deviates from the intended purpose of event cameras. To address these issues, we propose a fully asynchronous neuromorphic paradigm that integrates event cameras, spiking networks, and neuromorphic processors (Intel Loihi). This paradigm can faithfully process each event asynchronously as it arrives, mimicking the spike-driven signal processing in biological brains. We compare the proposed paradigm with the existing "group of events" processing paradigm in detail on the real mobile robot dodging task. Experimental results show that our scheme exhibits better robustness than frame-based methods with different time windows and light conditions. Additionally, the energy consumption per inference of our scheme on the embedded Loihi processor is only 4.30% of that of the event spike tensor method on NVIDIA Jetson Orin NX with energy-saving mode, and 1.64% of that of the event frame method on the same neuromorphic processor. As far as we know, this is the first time that a fully asynchronous neuromorphic paradigm has been implemented for solving sequential tasks on real mobile robot.
EV-MGDispNet: Motion-Guided Event-Based Stereo Disparity Estimation Network with Left-Right Consistency
Aug 10, 2024



Event cameras have the potential to revolutionize the field of robot vision, particularly in areas like stereo disparity estimation, owing to their high temporal resolution and high dynamic range. Many studies use deep learning for event camera stereo disparity estimation. However, these methods fail to fully exploit the temporal information in the event stream to acquire clear event representations. Additionally, there is room for further reduction in pixel shifts in the feature maps before constructing the cost volume. In this paper, we propose EV-MGDispNet, a novel event-based stereo disparity estimation method. Firstly, we propose an edge-aware aggregation (EAA) module, which fuses event frames and motion confidence maps to generate a novel clear event representation. Then, we propose a motion-guided attention (MGA) module, where motion confidence maps utilize deformable transformer encoders to enhance the feature map with more accurate edges. Finally, we also add a census left-right consistency loss function to enhance the left-right consistency of stereo event representation. Through conducting experiments within challenging real-world driving scenarios, we validate that our method outperforms currently known state-of-the-art methods in terms of mean absolute error (MAE) and root mean square error (RMSE) metrics.
Motion and Structure from Event-based Normal Flow
Jul 19, 2024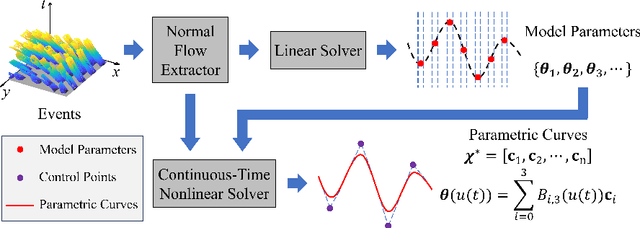
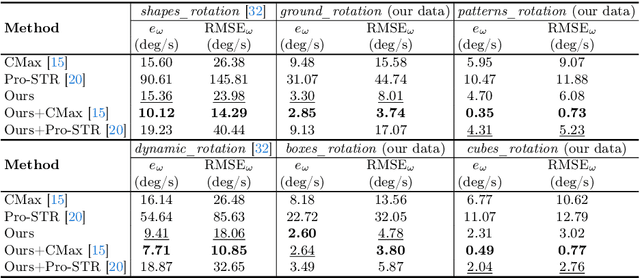


Recovering the camera motion and scene geometry from visual data is a fundamental problem in the field of computer vision. Its success in standard vision is attributed to the maturity of feature extraction, data association and multi-view geometry. The recent emergence of neuromorphic event-based cameras places great demands on approaches that use raw event data as input to solve this fundamental problem.Existing state-of-the-art solutions typically infer implicitly data association by iteratively reversing the event data generation process. However, the nonlinear nature of these methods limits their applicability in real-time tasks, and the constant-motion assumption leads to unstable results under agile motion. To this end, we rethink the problem formulation in a way that aligns better with the differential working principle of event cameras.We show that the event-based normal flow can be used, via the proposed geometric error term, as an alternative to the full flow in solving a family of geometric problems that involve instantaneous first-order kinematics and scene geometry. Furthermore, we develop a fast linear solver and a continuous-time nonlinear solver on top of the proposed geometric error term.Experiments on both synthetic and real data show the superiority of our linear solver in terms of accuracy and efficiency, and indicate its complementary feature as an initialization method for existing nonlinear solvers. Besides, our continuous-time non-linear solver exhibits exceptional capability in accommodating sudden variations in motion since it does not rely on the constant-motion assumption.
Spike-EVPR: Deep Spiking Residual Network with Cross-Representation Aggregation for Event-Based Visual Place Recognition
Feb 16, 2024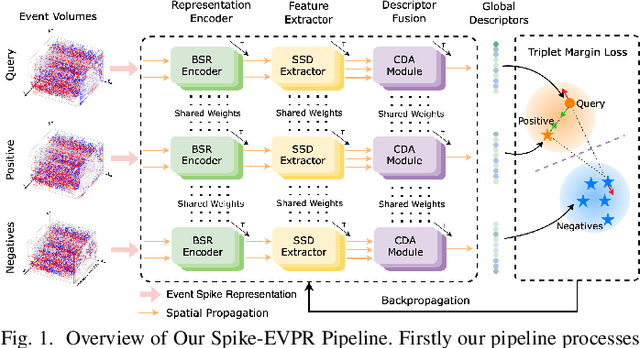
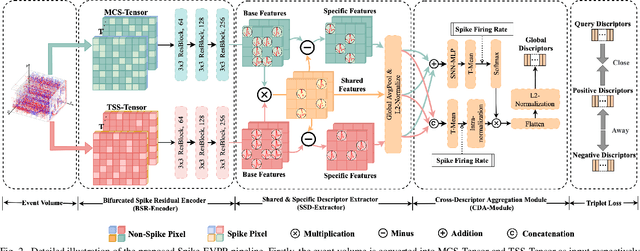
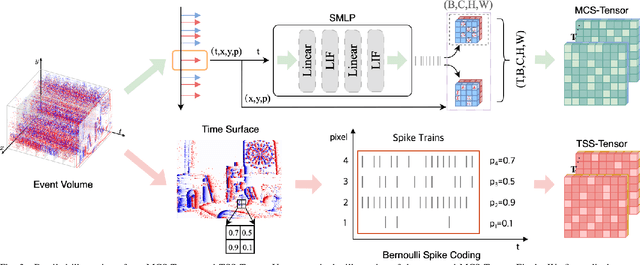
Event cameras have been successfully applied to visual place recognition (VPR) tasks by using deep artificial neural networks (ANNs) in recent years. However, previously proposed deep ANN architectures are often unable to harness the abundant temporal information presented in event streams. In contrast, deep spiking networks exhibit more intricate spatiotemporal dynamics and are inherently well-suited to process sparse asynchronous event streams. Unfortunately, directly inputting temporal-dense event volumes into the spiking network introduces excessive time steps, resulting in prohibitively high training costs for large-scale VPR tasks. To address the aforementioned issues, we propose a novel deep spiking network architecture called Spike-EVPR for event-based VPR tasks. First, we introduce two novel event representations tailored for SNN to fully exploit the spatio-temporal information from the event streams, and reduce the video memory occupation during training as much as possible. Then, to exploit the full potential of these two representations, we construct a Bifurcated Spike Residual Encoder (BSR-Encoder) with powerful representational capabilities to better extract the high-level features from the two event representations. Next, we introduce a Shared & Specific Descriptor Extractor (SSD-Extractor). This module is designed to extract features shared between the two representations and features specific to each. Finally, we propose a Cross-Descriptor Aggregation Module (CDA-Module) that fuses the above three features to generate a refined, robust global descriptor of the scene. Our experimental results indicate the superior performance of our Spike-EVPR compared to several existing EVPR pipelines on Brisbane-Event-VPR and DDD20 datasets, with the average Recall@1 increased by 7.61% on Brisbane and 13.20% on DDD20.
EV-MGRFlowNet: Motion-Guided Recurrent Network for Unsupervised Event-based Optical Flow with Hybrid Motion-Compensation Loss
May 13, 2023



Event cameras offer promising properties, such as high temporal resolution and high dynamic range. These benefits have been utilized into many machine vision tasks, especially optical flow estimation. Currently, most existing event-based works use deep learning to estimate optical flow. However, their networks have not fully exploited prior hidden states and motion flows. Additionally, their supervision strategy has not fully leveraged the geometric constraints of event data to unlock the potential of networks. In this paper, we propose EV-MGRFlowNet, an unsupervised event-based optical flow estimation pipeline with motion-guided recurrent networks using a hybrid motion-compensation loss. First, we propose a feature-enhanced recurrent encoder network (FERE-Net) which fully utilizes prior hidden states to obtain multi-level motion features. Then, we propose a flow-guided decoder network (FGD-Net) to integrate prior motion flows. Finally, we design a hybrid motion-compensation loss (HMC-Loss) to strengthen geometric constraints for the more accurate alignment of events. Experimental results show that our method outperforms the current state-of-the-art (SOTA) method on the MVSEC dataset, with an average reduction of approximately 22.71% in average endpoint error (AEE). To our knowledge, our method ranks first among unsupervised learning-based methods.
FE-Fusion-VPR: Attention-based Multi-Scale Network Architecture for Visual Place Recognition by Fusing Frames and Events
Nov 23, 2022



Traditional visual place recognition (VPR), usually using standard cameras, is easy to fail due to glare or high-speed motion. By contrast, event cameras have the advantages of low latency, high temporal resolution, and high dynamic range, which can deal with the above issues. Nevertheless, event cameras are prone to failure in weakly textured or motionless scenes, while standard cameras can still provide appearance information in this case. Thus, exploiting the complementarity of standard cameras and event cameras can effectively improve the performance of VPR algorithms. In the paper, we propose FE-Fusion-VPR, an attention-based multi-scale network architecture for VPR by fusing frames and events. First, the intensity frame and event volume are fed into the two-stream feature extraction network for shallow feature fusion. Next, the three-scale features are obtained through the multi-scale fusion network and aggregated into three sub-descriptors using the VLAD layer. Finally, the weight of each sub-descriptor is learned through the descriptor re-weighting network to obtain the final refined descriptor. Experimental results show that on the Brisbane-Event-VPR and DDD20 datasets, the Recall@1 of our FE-Fusion-VPR is 29.26% and 33.59% higher than Event-VPR and Ensemble-EventVPR, and is 7.00% and 14.15% higher than MultiRes-NetVLAD and NetVLAD. To our knowledge, this is the first end-to-end network that goes beyond the existing event-based and frame-based SOTA methods to fuse frame and events directly for VPR.
Neuro-Planner: A 3D Visual Navigation Method for MAV with Depth Camera based on Neuromorphic Reinforcement Learning
Oct 05, 2022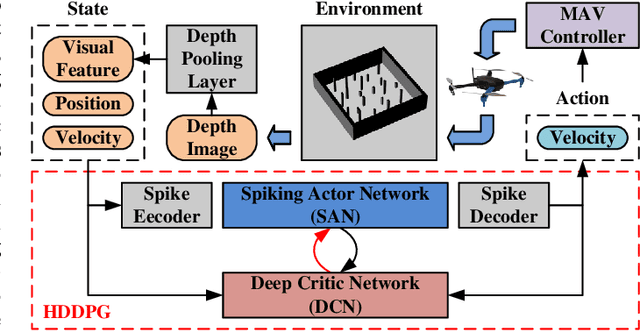
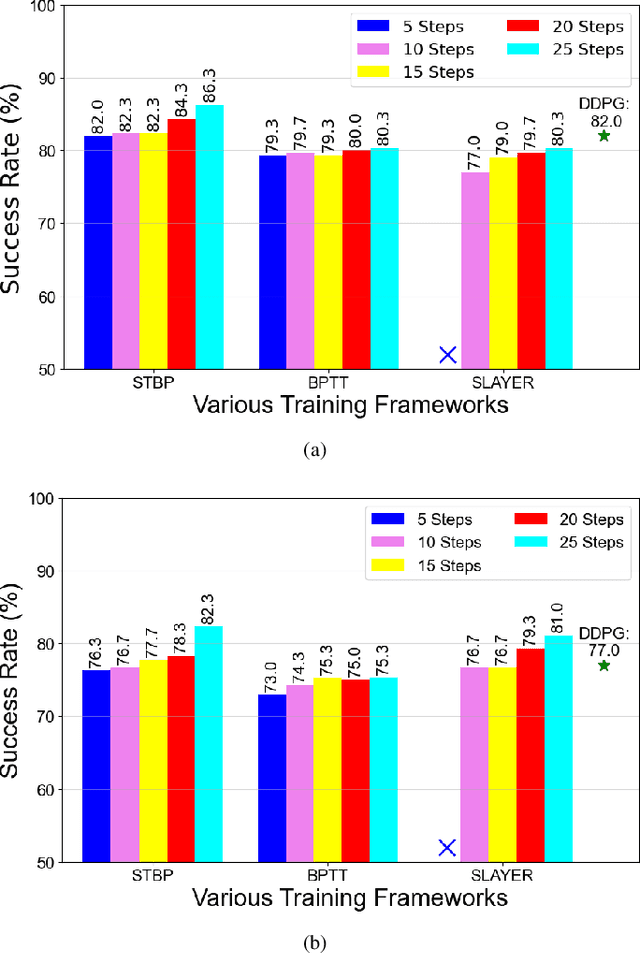
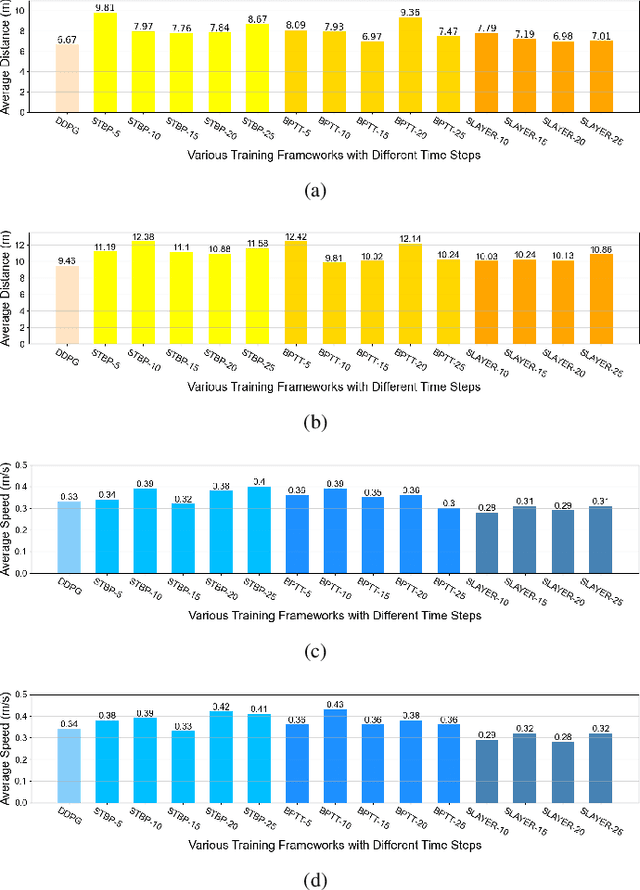
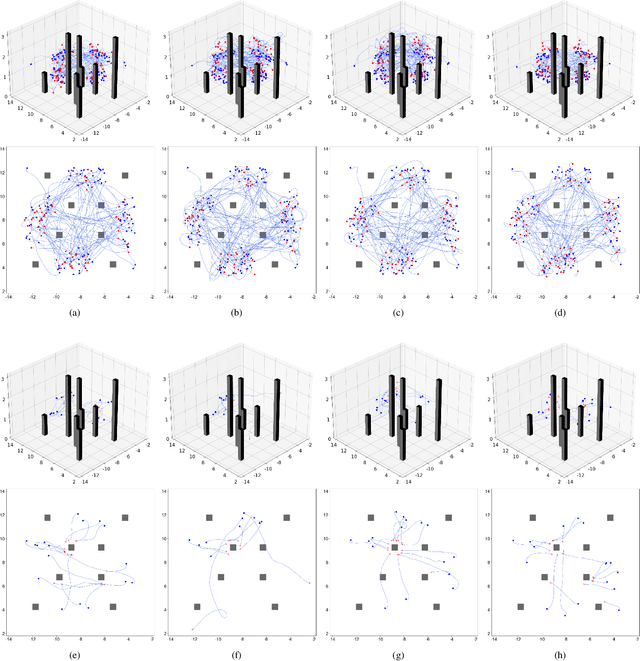
Traditional visual navigation methods of micro aerial vehicle (MAV) usually calculate a passable path that satisfies the constraints depending on a prior map. However, these methods have issues such as high demand for computing resources and poor robustness in face of unfamiliar environments. Aiming to solve the above problems, we propose a neuromorphic reinforcement learning method (Neuro-Planner) that combines spiking neural network (SNN) and deep reinforcement learning (DRL) to realize MAV 3D visual navigation with depth camera. Specifically, we design spiking actor network based on two-state LIF (TS-LIF) neurons and its encoding-decoding schemes for efficient inference. Then our improved hybrid deep deterministic policy gradient (HDDPG) and TS-LIF-based spatio-temporal back propagation (STBP) algorithms are used as the training framework for actor-critic network architecture. To verify the effectiveness of the proposed Neuro-Planner, we carry out detailed comparison experiments with various SNN training algorithm (STBP, BPTT and SLAYER) in the software-in-the-loop (SITL) simulation framework. The navigation success rate of our HDDPG-STBP is 4.3\% and 5.3\% higher than that of the original DDPG in the two evaluation environments. To the best of our knowledge, this is the first work combining neuromorphic computing and deep reinforcement learning for MAV 3D visual navigation task.
Event-VPR: End-to-End Weakly Supervised Network Architecture for Event-based Visual Place Recognition
Nov 06, 2020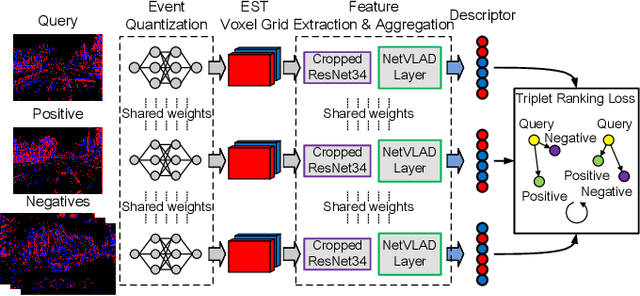
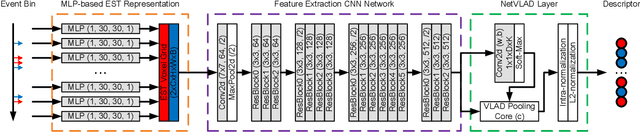
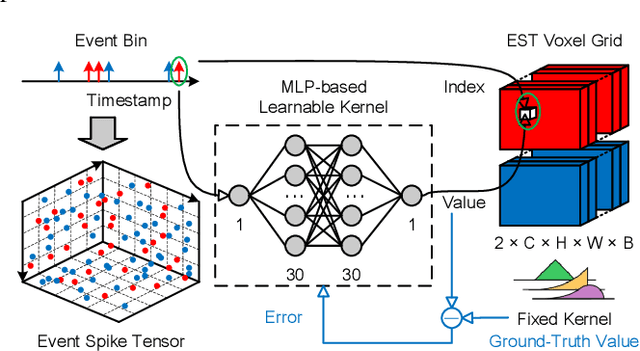
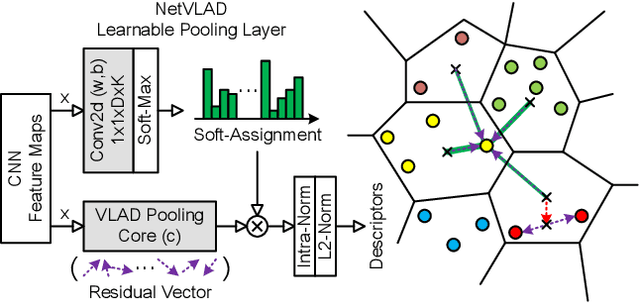
Traditional visual place recognition (VPR) methods generally use frame-based cameras, which is easy to fail due to dramatic illumination changes or fast motions. In this paper, we propose an end-to-end visual place recognition network for event cameras, which can achieve good place recognition performance in challenging environments. The key idea of the proposed algorithm is firstly to characterize the event streams with the EST voxel grid, then extract features using a convolution network, and finally aggregate features using an improved VLAD network to realize end-to-end visual place recognition using event streams. To verify the effectiveness of the proposed algorithm, we compare the proposed method with classical VPR methods on the event-based driving datasets (MVSEC, DDD17) and the synthetic datasets (Oxford RobotCar). Experimental results show that the proposed method can achieve much better performance in challenging scenarios. To our knowledge, this is the first end-to-end event-based VPR method. The accompanying source code is available at https://github.com/kongdelei/Event-VPR.