 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBSH-Det3D: Improving 3D Object Detection with BEV Shape Heatmap
Mar 03, 2023



The progress of LiDAR-based 3D object detection has significantly enhanced developments in autonomous driving and robotics. However, due to the limitations of LiDAR sensors, object shapes suffer from deterioration in occluded and distant areas, which creates a fundamental challenge to 3D perception. Existing methods estimate specific 3D shapes and achieve remarkable performance. However, these methods rely on extensive computation and memory, causing imbalances between accuracy and real-time performance. To tackle this challenge, we propose a novel LiDAR-based 3D object detection model named BSH-Det3D, which applies an effective way to enhance spatial features by estimating complete shapes from a bird's eye view (BEV). Specifically, we design the Pillar-based Shape Completion (PSC) module to predict the probability of occupancy whether a pillar contains object shapes. The PSC module generates a BEV shape heatmap for each scene. After integrating with heatmaps, BSH-Det3D can provide additional information in shape deterioration areas and generate high-quality 3D proposals. We also design an attention-based densification fusion module (ADF) to adaptively associate the sparse features with heatmaps and raw points. The ADF module integrates the advantages of points and shapes knowledge with negligible overheads. Extensive experiments on the KITTI benchmark achieve state-of-the-art (SOTA) performance in terms of accuracy and speed, demonstrating the efficiency and flexibility of BSH-Det3D. The source code is available on https://github.com/mystorm16/BSH-Det3D.
DYP-SLAM: A Real-time Visual SLAM Based on YOLO and Probability in Dynamic Environments
Feb 04, 2022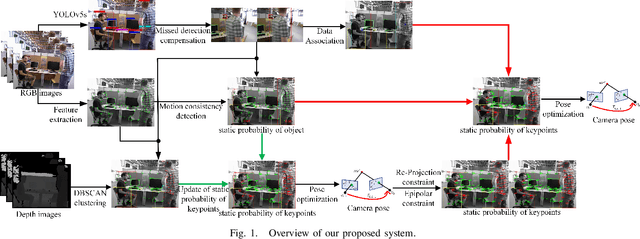

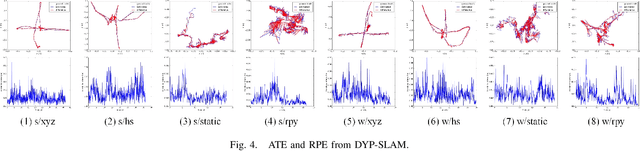
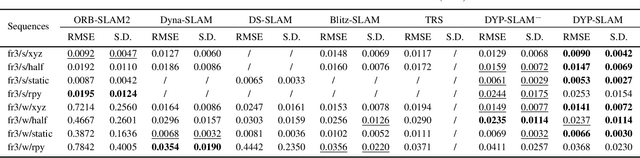
SLAM algorithm is based on the static assumption of environment. Therefore, the dynamic factors in the environment will have a great impact on the matching points due to violating this assumption, and then directly affect the accuracy of subsequent camera pose estimation. Recently, some related works generally use the combination of semantic constraints and geometric constraints to deal with dynamic objects, but there are some problems, such as poor real-time performance, easy to treat people as rigid bodies, and poor performance in low dynamic scenes. In this paper, a dynamic scene oriented visual SLAM algorithm based on target detection and static probability named DYP-SLAM is proposed. The algorithm combines semantic constraints and geometric constraints to calculate the static probability of objects, keypoints and map points, and takes them as weights to participate in camera pose estimation. The proposed algorithm is evaluated on the public dataset and compared with a variety of advanced algorithms. It has achieved the best results in almost all low dynamics and high dynamic scenarios, and showing quite high real-time.
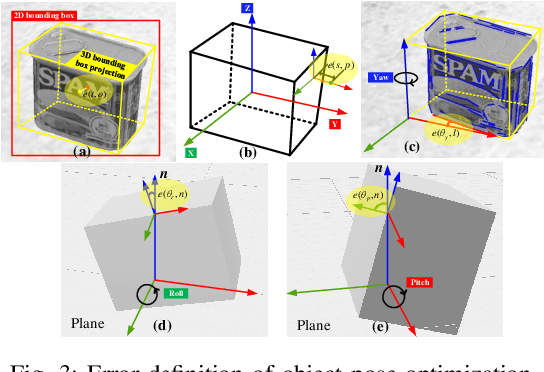
Accurate and Robust Object-oriented SLAM with 3D Quadric Landmark Construction in Outdoor Environment
Oct 18, 2021



Object-oriented SLAM is a popular technology in autonomous driving and robotics. In this paper, we propose a stereo visual SLAM with a robust quadric landmark representation method. The system consists of four components, including deep learning detection, object-oriented data association, dual quadric landmark initialization and object-based pose optimization. State-of-the-art quadric-based SLAM algorithms always face observation related problems and are sensitive to observation noise, which limits their application in outdoor scenes. To solve this problem, we propose a quadric initialization method based on the decoupling of the quadric parameters method, which improves the robustness to observation noise. The sufficient object data association algorithm and object-oriented optimization with multiple cues enables a highly accurate object pose estimation that is robust to local observations. Experimental results show that the proposed system is more robust to observation noise and significantly outperforms current state-of-the-art methods in outdoor environments. In addition, the proposed system demonstrates real-time performance.
Accurate and Robust Scale Recovery for Monocular Visual Odometry Based on Plane Geometry
Jan 15, 2021
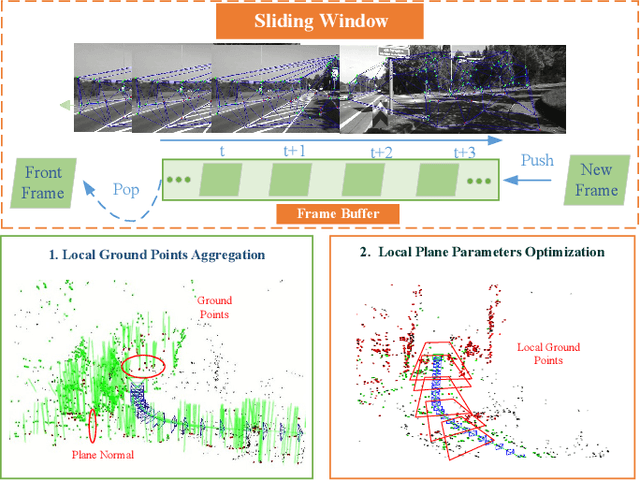
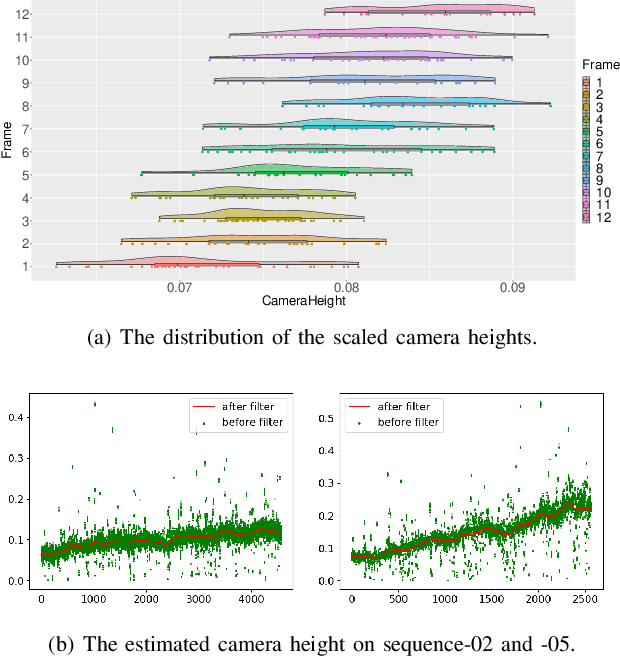
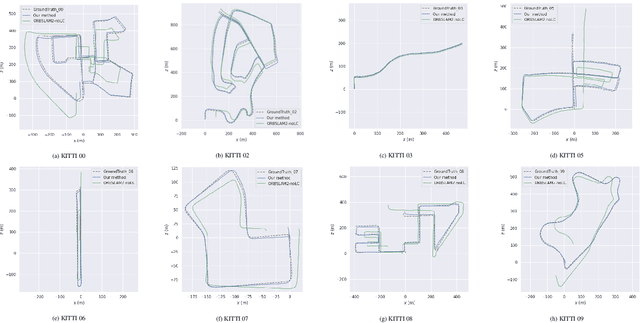
Scale ambiguity is a fundamental problem in monocular visual odometry. Typical solutions include loop closure detection and environment information mining. For applications like self-driving cars, loop closure is not always available, hence mining prior knowledge from the environment becomes a more promising approach. In this paper, with the assumption of a constant height of the camera above the ground, we develop a light-weight scale recovery framework leveraging an accurate and robust estimation of the ground plane. The framework includes a ground point extraction algorithm for selecting high-quality points on the ground plane, and a ground point aggregation algorithm for joining the extracted ground points in a local sliding window. Based on the aggregated data, the scale is finally recovered by solving a least-squares problem using a RANSAC-based optimizer. Sufficient data and robust optimizer enable a highly accurate scale recovery. Experiments on the KITTI dataset show that the proposed framework can achieve state-of-the-art accuracy in terms of translation errors, while maintaining competitive performance on the rotation error. Due to the light-weight design, our framework also demonstrates a high frequency of 20Hz on the dataset.
Object-Driven Active Mapping for More Accurate Object Pose Estimation and Robotic Grasping
Dec 03, 2020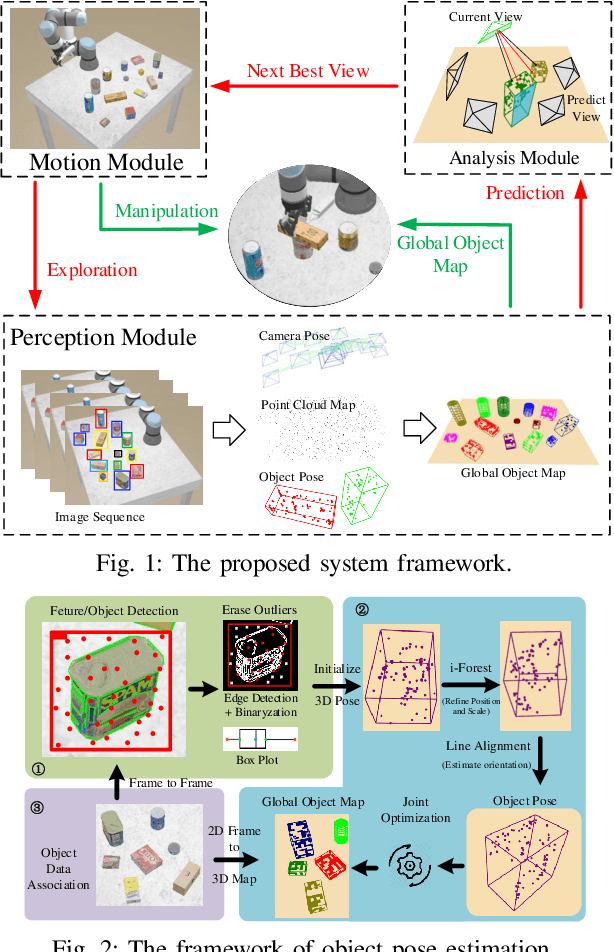
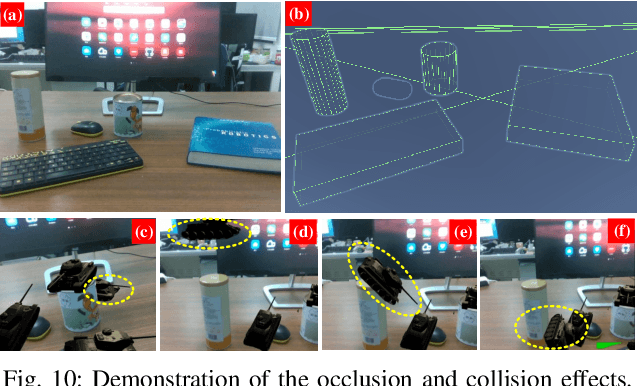

This paper presents the first active object mapping framework for complex robotic grasping tasks. The framework is built on an object SLAM system integrated with a simultaneous multi-object pose estimation process. Aiming to reduce the observation uncertainty on target objects and increase their pose estimation accuracy, we also design an object-driven exploration strategy to guide the object mapping process. By combining the mapping module and the exploration strategy, an accurate object map that is compatible with robotic grasping can be generated. Quantitative evaluations also show that the proposed framework has a very high mapping accuracy. Manipulation experiments, including object grasping, object placement, and the augmented reality, significantly demonstrate the effectiveness and advantages of our proposed framework.
Event-VPR: End-to-End Weakly Supervised Network Architecture for Event-based Visual Place Recognition
Nov 06, 2020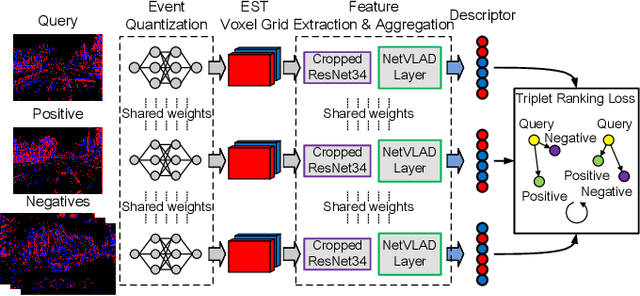
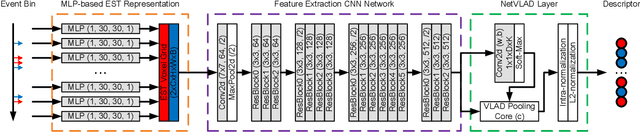
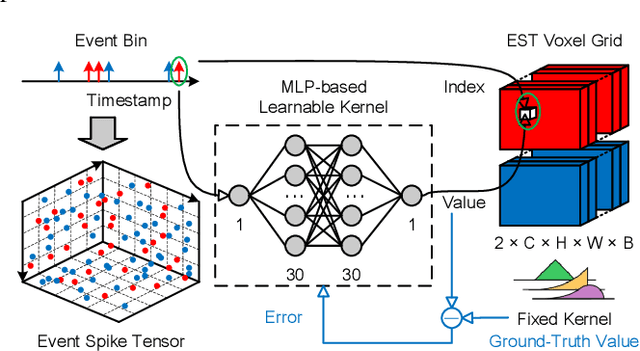
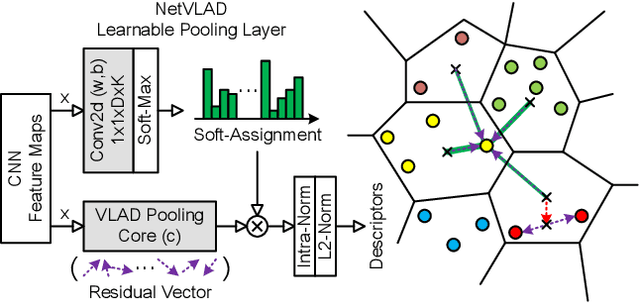
Traditional visual place recognition (VPR) methods generally use frame-based cameras, which is easy to fail due to dramatic illumination changes or fast motions. In this paper, we propose an end-to-end visual place recognition network for event cameras, which can achieve good place recognition performance in challenging environments. The key idea of the proposed algorithm is firstly to characterize the event streams with the EST voxel grid, then extract features using a convolution network, and finally aggregate features using an improved VLAD network to realize end-to-end visual place recognition using event streams. To verify the effectiveness of the proposed algorithm, we compare the proposed method with classical VPR methods on the event-based driving datasets (MVSEC, DDD17) and the synthetic datasets (Oxford RobotCar). Experimental results show that the proposed method can achieve much better performance in challenging scenarios. To our knowledge, this is the first end-to-end event-based VPR method. The accompanying source code is available at https://github.com/kongdelei/Event-VPR.
EAO-SLAM: Monocular Semi-Dense Object SLAM Based on Ensemble Data Association
Apr 27, 2020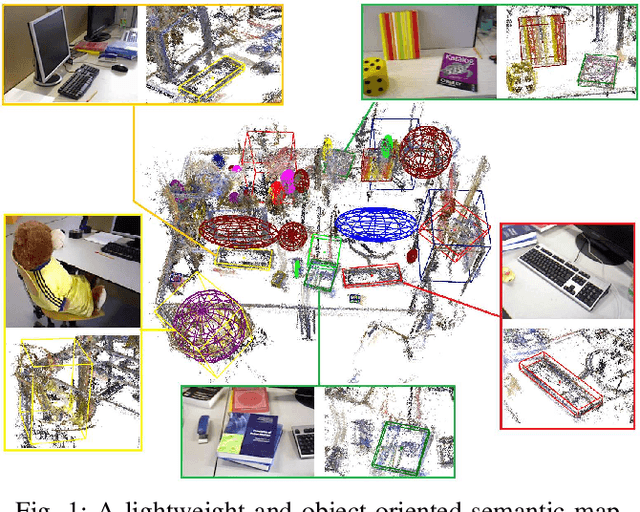
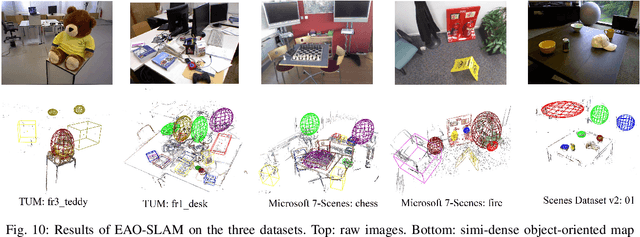
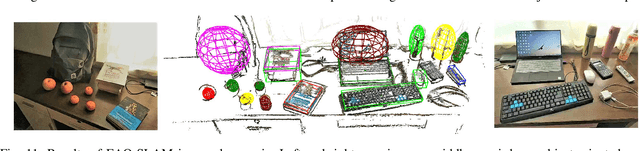
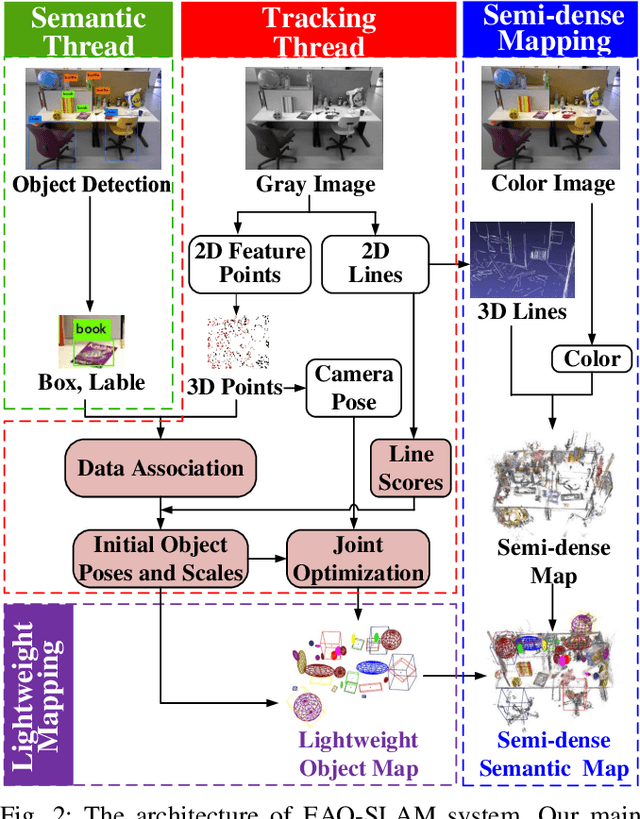
Object-level data association and pose estimation play a fundamental role in semantic SLAM, which remain unsolved due to the lack of robust and accurate algorithms. In this work, we propose an ensemble data associate strategy to integrate the parametric and nonparametric statistic tests. By exploiting the nature of different statistics, our method can effectively aggregate the information of different measurements, and thus significantly improve the robustness and accuracy of the association process. We then present an accurate object pose estimation framework, in which an outlier-robust centroid and scale estimation algorithm and an object pose initialization algorithm are developed to help improve the optimality of the estimated results. Furthermore, we build a SLAM system that can generate semi-dense or lightweight object-oriented maps with a monocular camera. Extensive experiments are conducted on three publicly available datasets and a real scenario. The results show that our approach significantly outperforms state-of-the-art techniques in accuracy and robustness.