 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDEGS: Deformable Event-based 3D Gaussian Splatting from RGB and Event Stream
Oct 09, 2025Reconstructing Dynamic 3D Gaussian Splatting (3DGS) from low-framerate RGB videos is challenging. This is because large inter-frame motions will increase the uncertainty of the solution space. For example, one pixel in the first frame might have more choices to reach the corresponding pixel in the second frame. Event cameras can asynchronously capture rapid visual changes and are robust to motion blur, but they do not provide color information. Intuitively, the event stream can provide deterministic constraints for the inter-frame large motion by the event trajectories. Hence, combining low-temporal-resolution images with high-framerate event streams can address this challenge. However, it is challenging to jointly optimize Dynamic 3DGS using both RGB and event modalities due to the significant discrepancy between these two data modalities. This paper introduces a novel framework that jointly optimizes dynamic 3DGS from the two modalities. The key idea is to adopt event motion priors to guide the optimization of the deformation fields. First, we extract the motion priors encoded in event streams by using the proposed LoCM unsupervised fine-tuning framework to adapt an event flow estimator to a certain unseen scene. Then, we present the geometry-aware data association method to build the event-Gaussian motion correspondence, which is the primary foundation of the pipeline, accompanied by two useful strategies, namely motion decomposition and inter-frame pseudo-label. Extensive experiments show that our method outperforms existing image and event-based approaches across synthetic and real scenes and prove that our method can effectively optimize dynamic 3DGS with the help of event data.
Optimal Brain Apoptosis
Feb 25, 2025
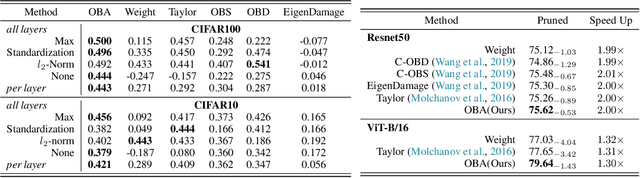
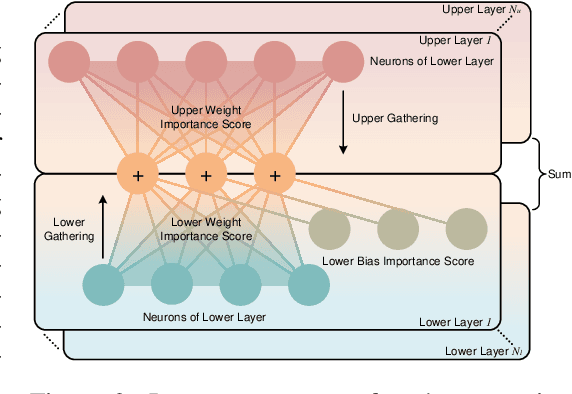
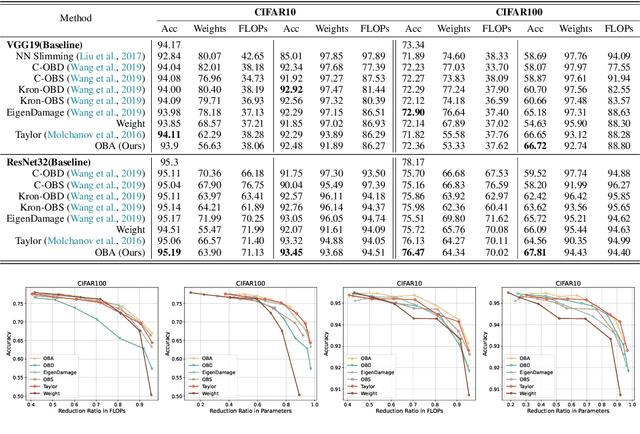
The increasing complexity and parameter count of Convolutional Neural Networks (CNNs) and Transformers pose challenges in terms of computational efficiency and resource demands. Pruning has been identified as an effective strategy to address these challenges by removing redundant elements such as neurons, channels, or connections, thereby enhancing computational efficiency without heavily compromising performance. This paper builds on the foundational work of Optimal Brain Damage (OBD) by advancing the methodology of parameter importance estimation using the Hessian matrix. Unlike previous approaches that rely on approximations, we introduce Optimal Brain Apoptosis (OBA), a novel pruning method that calculates the Hessian-vector product value directly for each parameter. By decomposing the Hessian matrix across network layers and identifying conditions under which inter-layer Hessian submatrices are non-zero, we propose a highly efficient technique for computing the second-order Taylor expansion of parameters. This approach allows for a more precise pruning process, particularly in the context of CNNs and Transformers, as validated in our experiments including VGG19, ResNet32, ResNet50, and ViT-B/16 on CIFAR10, CIFAR100 and Imagenet datasets. Our code is available at https://github.com/NEU-REAL/OBA.
DEL: Discrete Element Learner for Learning 3D Particle Dynamics with Neural Rendering
Oct 11, 2024



Learning-based simulators show great potential for simulating particle dynamics when 3D groundtruth is available, but per-particle correspondences are not always accessible. The development of neural rendering presents a new solution to this field to learn 3D dynamics from 2D images by inverse rendering. However, existing approaches still suffer from ill-posed natures resulting from the 2D to 3D uncertainty, for example, specific 2D images can correspond with various 3D particle distributions. To mitigate such uncertainty, we consider a conventional, mechanically interpretable framework as the physical priors and extend it to a learning-based version. In brief, we incorporate the learnable graph kernels into the classic Discrete Element Analysis (DEA) framework to implement a novel mechanics-integrated learning system. In this case, the graph network kernels are only used for approximating some specific mechanical operators in the DEA framework rather than the whole dynamics mapping. By integrating the strong physics priors, our methods can effectively learn the dynamics of various materials from the partial 2D observations in a unified manner. Experiments show that our approach outperforms other learned simulators by a large margin in this context and is robust to different renderers, fewer training samples, and fewer camera views.
Spiking Neural Network as Adaptive Event Stream Slicer
Oct 03, 2024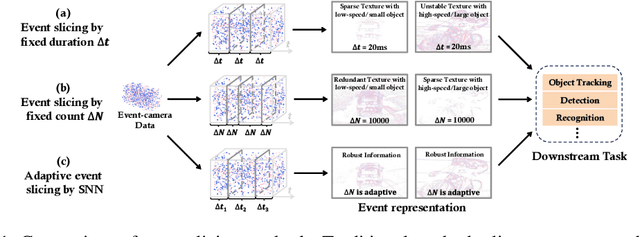
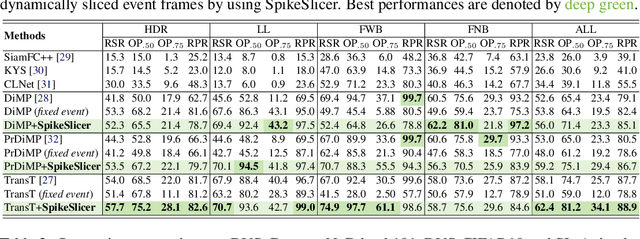
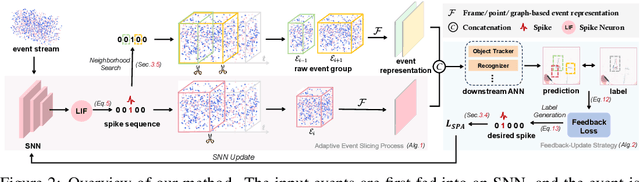

Event-based cameras are attracting significant interest as they provide rich edge information, high dynamic range, and high temporal resolution. Many state-of-the-art event-based algorithms rely on splitting the events into fixed groups, resulting in the omission of crucial temporal information, particularly when dealing with diverse motion scenarios (e.g., high/low speed). In this work, we propose SpikeSlicer, a novel-designed plug-and-play event processing method capable of splitting events stream adaptively. SpikeSlicer utilizes a lightweight (0.41M) and low-energy spiking neural network (SNN) to trigger event slicing. To guide the SNN to fire spikes at optimal time steps, we propose the Spiking Position-aware Loss (SPA-Loss) to modulate the neuron's state. Additionally, we develop a Feedback-Update training strategy that refines the slicing decisions using feedback from the downstream artificial neural network (ANN). Extensive experiments demonstrate that our method yields significant performance improvements in event-based object tracking and recognition. Notably, SpikeSlicer provides a brand-new SNN-ANN cooperation paradigm, where the SNN acts as an efficient, low-energy data processor to assist the ANN in improving downstream performance, injecting new perspectives and potential avenues of exploration.
Query-based Semantic Gaussian Field for Scene Representation in Reinforcement Learning
Jun 04, 2024



Latent scene representation plays a significant role in training reinforcement learning (RL) agents. To obtain good latent vectors describing the scenes, recent works incorporate the 3D-aware latent-conditioned NeRF pipeline into scene representation learning. However, these NeRF-related methods struggle to perceive 3D structural information due to the inefficient dense sampling in volumetric rendering. Moreover, they lack fine-grained semantic information included in their scene representation vectors because they evenly consider free and occupied spaces. Both of them can destroy the performance of downstream RL tasks. To address the above challenges, we propose a novel framework that adopts the efficient 3D Gaussian Splatting (3DGS) to learn 3D scene representation for the first time. In brief, we present the Query-based Generalizable 3DGS to bridge the 3DGS technique and scene representations with more geometrical awareness than those in NeRFs. Moreover, we present the Hierarchical Semantics Encoding to ground the fine-grained semantic features to 3D Gaussians and further distilled to the scene representation vectors. We conduct extensive experiments on two RL platforms including Maniskill2 and Robomimic across 10 different tasks. The results show that our method outperforms the other 5 baselines by a large margin. We achieve the best success rates on 8 tasks and the second-best on the other two tasks.
EvGGS: A Collaborative Learning Framework for Event-based Generalizable Gaussian Splatting
May 23, 2024



Event cameras offer promising advantages such as high dynamic range and low latency, making them well-suited for challenging lighting conditions and fast-moving scenarios. However, reconstructing 3D scenes from raw event streams is difficult because event data is sparse and does not carry absolute color information. To release its potential in 3D reconstruction, we propose the first event-based generalizable 3D reconstruction framework, called EvGGS, which reconstructs scenes as 3D Gaussians from only event input in a feedforward manner and can generalize to unseen cases without any retraining. This framework includes a depth estimation module, an intensity reconstruction module, and a Gaussian regression module. These submodules connect in a cascading manner, and we collaboratively train them with a designed joint loss to make them mutually promote. To facilitate related studies, we build a novel event-based 3D dataset with various material objects and calibrated labels of grayscale images, depth maps, camera poses, and silhouettes. Experiments show models that have jointly trained significantly outperform those trained individually. Our approach performs better than all baselines in reconstruction quality, and depth/intensity predictions with satisfactory rendering speed.
EventRPG: Event Data Augmentation with Relevance Propagation Guidance
Mar 14, 2024



Event camera, a novel bio-inspired vision sensor, has drawn a lot of attention for its low latency, low power consumption, and high dynamic range. Currently, overfitting remains a critical problem in event-based classification tasks for Spiking Neural Network (SNN) due to its relatively weak spatial representation capability. Data augmentation is a simple but efficient method to alleviate overfitting and improve the generalization ability of neural networks, and saliency-based augmentation methods are proven to be effective in the image processing field. However, there is no approach available for extracting saliency maps from SNNs. Therefore, for the first time, we present Spiking Layer-Time-wise Relevance Propagation rule (SLTRP) and Spiking Layer-wise Relevance Propagation rule (SLRP) in order for SNN to generate stable and accurate CAMs and saliency maps. Based on this, we propose EventRPG, which leverages relevance propagation on the spiking neural network for more efficient augmentation. Our proposed method has been evaluated on several SNN structures, achieving state-of-the-art performance in object recognition tasks including N-Caltech101, CIFAR10-DVS, with accuracies of 85.62% and 85.55%, as well as action recognition task SL-Animals with an accuracy of 91.59%. Our code is available at https://github.com/myuansun/EventRPG.
Spike-EVPR: Deep Spiking Residual Network with Cross-Representation Aggregation for Event-Based Visual Place Recognition
Feb 16, 2024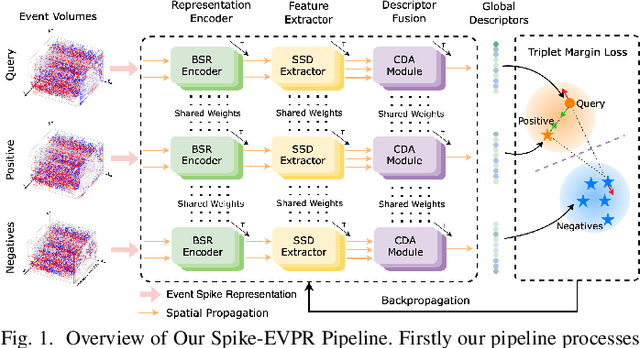
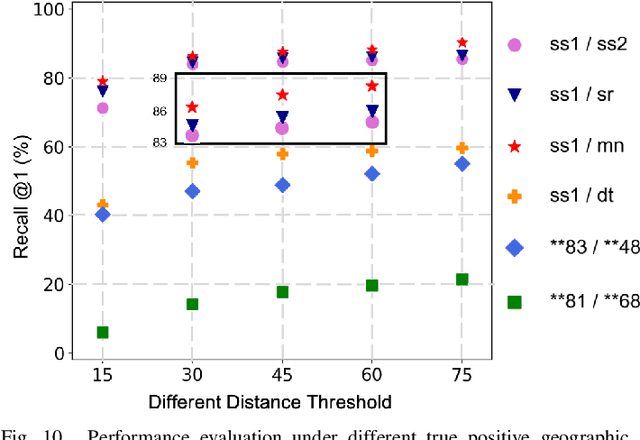
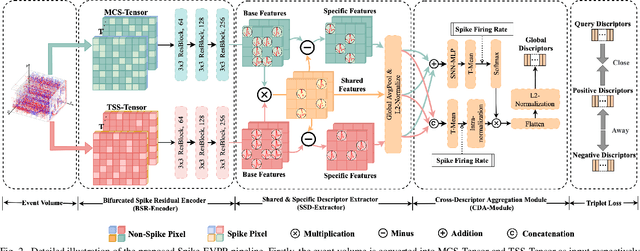
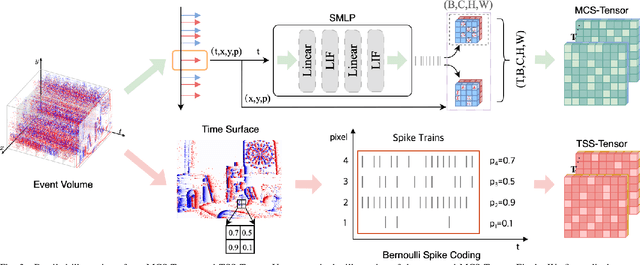
Event cameras have been successfully applied to visual place recognition (VPR) tasks by using deep artificial neural networks (ANNs) in recent years. However, previously proposed deep ANN architectures are often unable to harness the abundant temporal information presented in event streams. In contrast, deep spiking networks exhibit more intricate spatiotemporal dynamics and are inherently well-suited to process sparse asynchronous event streams. Unfortunately, directly inputting temporal-dense event volumes into the spiking network introduces excessive time steps, resulting in prohibitively high training costs for large-scale VPR tasks. To address the aforementioned issues, we propose a novel deep spiking network architecture called Spike-EVPR for event-based VPR tasks. First, we introduce two novel event representations tailored for SNN to fully exploit the spatio-temporal information from the event streams, and reduce the video memory occupation during training as much as possible. Then, to exploit the full potential of these two representations, we construct a Bifurcated Spike Residual Encoder (BSR-Encoder) with powerful representational capabilities to better extract the high-level features from the two event representations. Next, we introduce a Shared & Specific Descriptor Extractor (SSD-Extractor). This module is designed to extract features shared between the two representations and features specific to each. Finally, we propose a Cross-Descriptor Aggregation Module (CDA-Module) that fuses the above three features to generate a refined, robust global descriptor of the scene. Our experimental results indicate the superior performance of our Spike-EVPR compared to several existing EVPR pipelines on Brisbane-Event-VPR and DDD20 datasets, with the average Recall@1 increased by 7.61% on Brisbane and 13.20% on DDD20.