 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpike-EVPR: Deep Spiking Residual Network with Cross-Representation Aggregation for Event-Based Visual Place Recognition
Paper and Code
Feb 16, 2024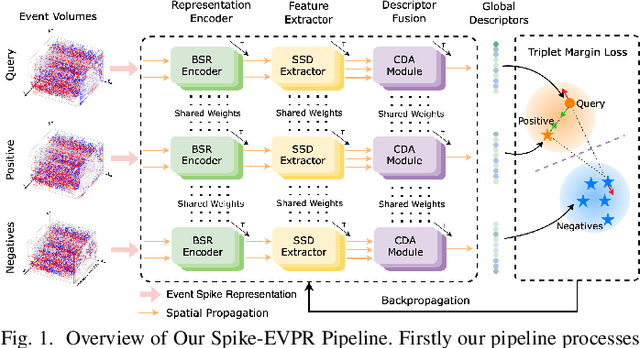
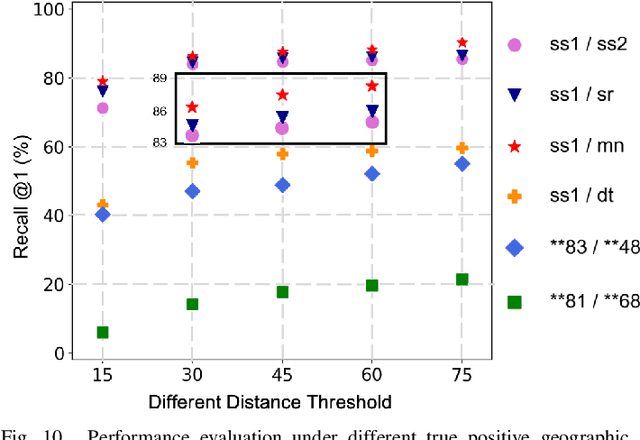
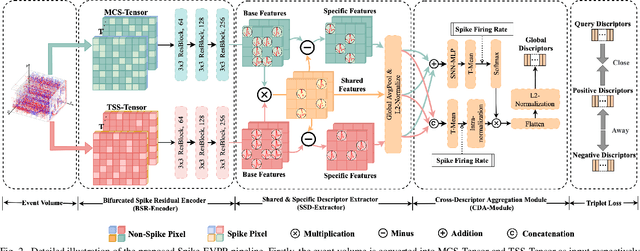
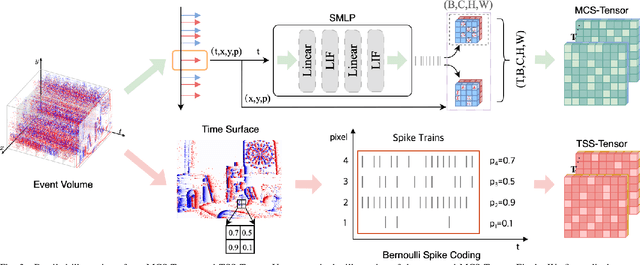
Event cameras have been successfully applied to visual place recognition (VPR) tasks by using deep artificial neural networks (ANNs) in recent years. However, previously proposed deep ANN architectures are often unable to harness the abundant temporal information presented in event streams. In contrast, deep spiking networks exhibit more intricate spatiotemporal dynamics and are inherently well-suited to process sparse asynchronous event streams. Unfortunately, directly inputting temporal-dense event volumes into the spiking network introduces excessive time steps, resulting in prohibitively high training costs for large-scale VPR tasks. To address the aforementioned issues, we propose a novel deep spiking network architecture called Spike-EVPR for event-based VPR tasks. First, we introduce two novel event representations tailored for SNN to fully exploit the spatio-temporal information from the event streams, and reduce the video memory occupation during training as much as possible. Then, to exploit the full potential of these two representations, we construct a Bifurcated Spike Residual Encoder (BSR-Encoder) with powerful representational capabilities to better extract the high-level features from the two event representations. Next, we introduce a Shared & Specific Descriptor Extractor (SSD-Extractor). This module is designed to extract features shared between the two representations and features specific to each. Finally, we propose a Cross-Descriptor Aggregation Module (CDA-Module) that fuses the above three features to generate a refined, robust global descriptor of the scene. Our experimental results indicate the superior performance of our Spike-EVPR compared to several existing EVPR pipelines on Brisbane-Event-VPR and DDD20 datasets, with the average Recall@1 increased by 7.61% on Brisbane and 13.20% on DDD20.