 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpiking Transformers Need High Frequency Information
May 24, 2025Spiking Transformers offer an energy-efficient alternative to conventional deep learning by transmitting information solely through binary (0/1) spikes. However, there remains a substantial performance gap compared to artificial neural networks. A common belief is that their binary and sparse activation transmission leads to information loss, thus degrading feature representation and accuracy. In this work, however, we reveal for the first time that spiking neurons preferentially propagate low-frequency information. We hypothesize that the rapid dissipation of high-frequency components is the primary cause of performance degradation. For example, on Cifar-100, adopting Avg-Pooling (low-pass) for token mixing lowers performance to 76.73%; interestingly, replacing it with Max-Pooling (high-pass) pushes the top-1 accuracy to 79.12%, surpassing the well-tuned Spikformer baseline by 0.97%. Accordingly, we introduce Max-Former that restores high-frequency signals through two frequency-enhancing operators: extra Max-Pooling in patch embedding and Depth-Wise Convolution in place of self-attention. Notably, our Max-Former (63.99 M) hits the top-1 accuracy of 82.39% on ImageNet, showing a +7.58% improvement over Spikformer with comparable model size (74.81%, 66.34 M). We hope this simple yet effective solution inspires future research to explore the distinctive nature of spiking neural networks, beyond the established practice in standard deep learning.
Efficient 3D Recognition with Event-driven Spike Sparse Convolution
Dec 10, 2024



Spiking Neural Networks (SNNs) provide an energy-efficient way to extract 3D spatio-temporal features. Point clouds are sparse 3D spatial data, which suggests that SNNs should be well-suited for processing them. However, when applying SNNs to point clouds, they often exhibit limited performance and fewer application scenarios. We attribute this to inappropriate preprocessing and feature extraction methods. To address this issue, we first introduce the Spike Voxel Coding (SVC) scheme, which encodes the 3D point clouds into a sparse spike train space, reducing the storage requirements and saving time on point cloud preprocessing. Then, we propose a Spike Sparse Convolution (SSC) model for efficiently extracting 3D sparse point cloud features. Combining SVC and SSC, we design an efficient 3D SNN backbone (E-3DSNN), which is friendly with neuromorphic hardware. For instance, SSC can be implemented on neuromorphic chips with only minor modifications to the addressing function of vanilla spike convolution. Experiments on ModelNet40, KITTI, and Semantic KITTI datasets demonstrate that E-3DSNN achieves state-of-the-art (SOTA) results with remarkable efficiency. Notably, our E-3DSNN (1.87M) obtained 91.7\% top-1 accuracy on ModelNet40, surpassing the current best SNN baselines (14.3M) by 3.0\%. To our best knowledge, it is the first direct training 3D SNN backbone that can simultaneously handle various 3D computer vision tasks (e.g., classification, detection, and segmentation) with an event-driven nature. Code is available: https://github.com/bollossom/E-3DSNN/.
Enhancing SNN-based Spatio-Temporal Learning: A Benchmark Dataset and Cross-Modality Attention Model
Oct 21, 2024

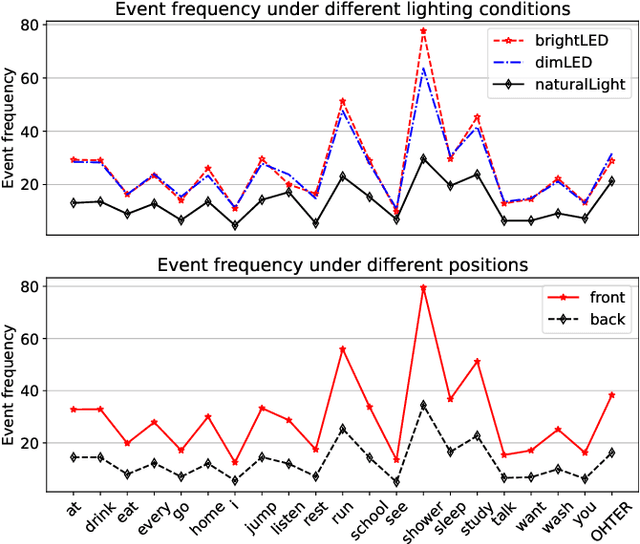
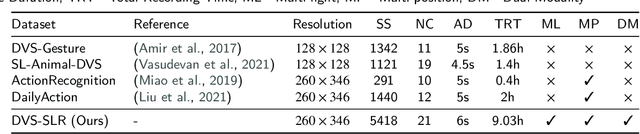
Spiking Neural Networks (SNNs), renowned for their low power consumption, brain-inspired architecture, and spatio-temporal representation capabilities, have garnered considerable attention in recent years. Similar to Artificial Neural Networks (ANNs), high-quality benchmark datasets are of great importance to the advances of SNNs. However, our analysis indicates that many prevalent neuromorphic datasets lack strong temporal correlation, preventing SNNs from fully exploiting their spatio-temporal representation capabilities. Meanwhile, the integration of event and frame modalities offers more comprehensive visual spatio-temporal information. Yet, the SNN-based cross-modality fusion remains underexplored. In this work, we present a neuromorphic dataset called DVS-SLR that can better exploit the inherent spatio-temporal properties of SNNs. Compared to existing datasets, it offers advantages in terms of higher temporal correlation, larger scale, and more varied scenarios. In addition, our neuromorphic dataset contains corresponding frame data, which can be used for developing SNN-based fusion methods. By virtue of the dual-modal feature of the dataset, we propose a Cross-Modality Attention (CMA) based fusion method. The CMA model efficiently utilizes the unique advantages of each modality, allowing for SNNs to learn both temporal and spatial attention scores from the spatio-temporal features of event and frame modalities, subsequently allocating these scores across modalities to enhance their synergy. Experimental results demonstrate that our method not only improves recognition accuracy but also ensures robustness across diverse scenarios.
Spiking Neural Network as Adaptive Event Stream Slicer
Oct 03, 2024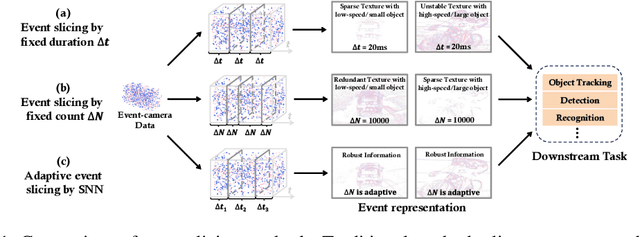
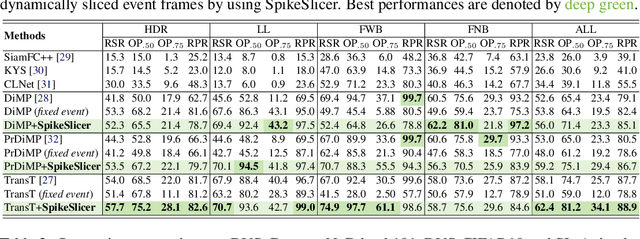
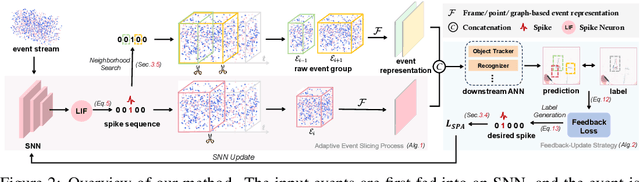

Event-based cameras are attracting significant interest as they provide rich edge information, high dynamic range, and high temporal resolution. Many state-of-the-art event-based algorithms rely on splitting the events into fixed groups, resulting in the omission of crucial temporal information, particularly when dealing with diverse motion scenarios (e.g., high/low speed). In this work, we propose SpikeSlicer, a novel-designed plug-and-play event processing method capable of splitting events stream adaptively. SpikeSlicer utilizes a lightweight (0.41M) and low-energy spiking neural network (SNN) to trigger event slicing. To guide the SNN to fire spikes at optimal time steps, we propose the Spiking Position-aware Loss (SPA-Loss) to modulate the neuron's state. Additionally, we develop a Feedback-Update training strategy that refines the slicing decisions using feedback from the downstream artificial neural network (ANN). Extensive experiments demonstrate that our method yields significant performance improvements in event-based object tracking and recognition. Notably, SpikeSlicer provides a brand-new SNN-ANN cooperation paradigm, where the SNN acts as an efficient, low-energy data processor to assist the ANN in improving downstream performance, injecting new perspectives and potential avenues of exploration.
Spectrum Attention Mechanism for Time Series Classification
Jan 25, 2021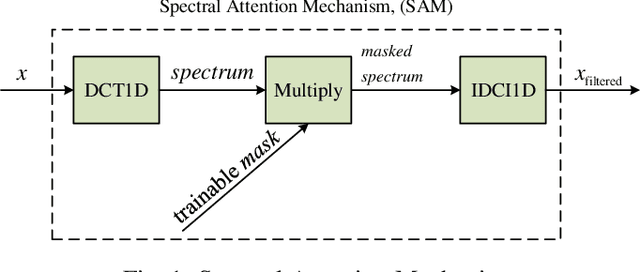
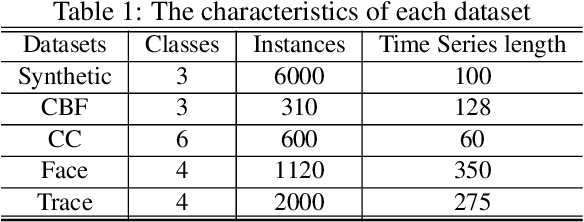
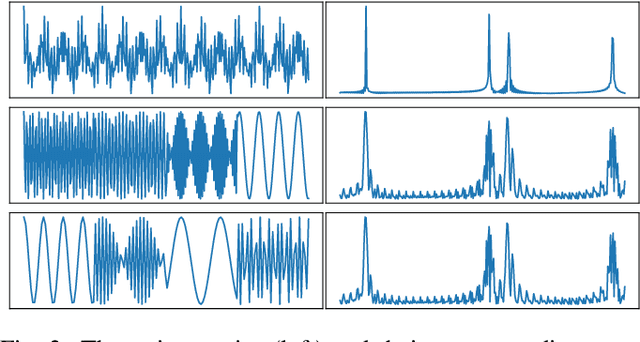

Time series classification(TSC) has always been an important and challenging research task. With the wide application of deep learning, more and more researchers use deep learning models to solve TSC problems. Since time series always contains a lot of noise, which has a negative impact on network training, people usually filter the original data before training the network. The existing schemes are to treat the filtering and training as two stages, and the design of the filter requires expert experience, which increases the design difficulty of the algorithm and is not universal. We note that the essence of filtering is to filter out the insignificant frequency components and highlight the important ones, which is similar to the attention mechanism. In this paper, we propose an attention mechanism that acts on spectrum (SAM). The network can assign appropriate weights to each frequency component to achieve adaptive filtering. We use L1 regularization to further enhance the frequency screening capability of SAM. We also propose a segmented-SAM (SSAM) to avoid the loss of time domain information caused by using the spectrum of the whole sequence. In which, a tumbling window is introduced to segment the original data. Then SAM is applied to each segment to generate new features. We propose a heuristic strategy to search for the appropriate number of segments. Experimental results show that SSAM can produce better feature representations, make the network converge faster, and improve the robustness and classification accuracy.
A Spike Learning System for Event-driven Object Recognition
Jan 21, 2021

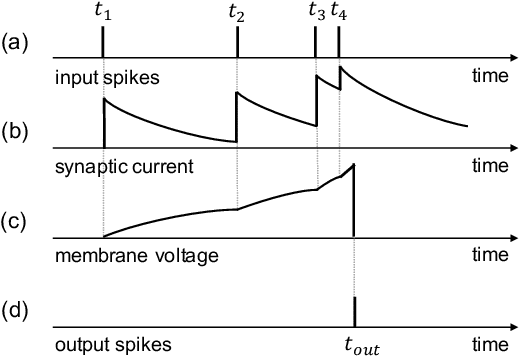
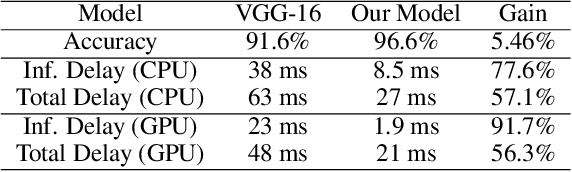
Event-driven sensors such as LiDAR and dynamic vision sensor (DVS) have found increased attention in high-resolution and high-speed applications. A lot of work has been conducted to enhance recognition accuracy. However, the essential topic of recognition delay or time efficiency is largely under-explored. In this paper, we present a spiking learning system that uses the spiking neural network (SNN) with a novel temporal coding for accurate and fast object recognition. The proposed temporal coding scheme maps each event's arrival time and data into SNN spike time so that asynchronously-arrived events are processed immediately without delay. The scheme is integrated nicely with the SNN's asynchronous processing capability to enhance time efficiency. A key advantage over existing systems is that the event accumulation time for each recognition task is determined automatically by the system rather than pre-set by the user. The system can finish recognition early without waiting for all the input events. Extensive experiments were conducted over a list of 7 LiDAR and DVS datasets. The results demonstrated that the proposed system had state-of-the-art recognition accuracy while achieving remarkable time efficiency. Recognition delay was shown to reduce by 56.3% to 91.7% in various experiment settings over the popular KITTI dataset.
Spiking Neural Networks with Single-Spike Temporal-Coded Neurons for Network Intrusion Detection
Oct 15, 2020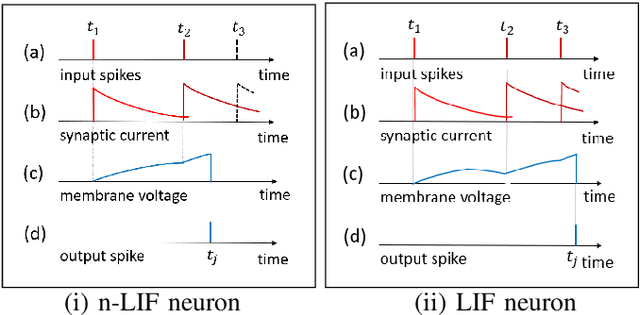


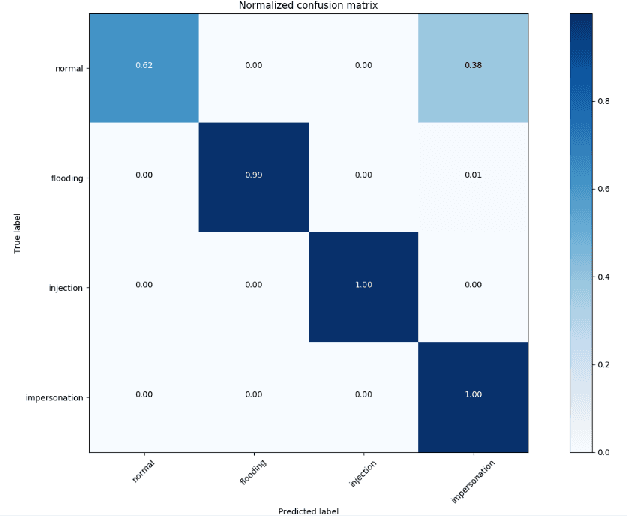
Spiking neural network (SNN) is interesting due to its strong bio-plausibility and high energy efficiency. However, its performance is falling far behind conventional deep neural networks (DNNs). In this paper, considering a general class of single-spike temporal-coded integrate-and-fire neurons, we analyze the input-output expressions of both leaky and nonleaky neurons. We show that SNNs built with leaky neurons suffer from the overly-nonlinear and overly-complex input-output response, which is the major reason for their difficult training and low performance. This reason is more fundamental than the commonly believed problem of nondifferentiable spikes. To support this claim, we show that SNNs built with nonleaky neurons can have a less-complex and less-nonlinear input-output response. They can be easily trained and can have superior performance, which is demonstrated by experimenting with the SNNs over two popular network intrusion detection datasets, i.e., the NSL-KDD and the AWID datasets. Our experiment results show that the proposed SNNs outperform a comprehensive list of DNN models and classic machine learning models. This paper demonstrates that SNNs can be promising and competitive in contrast to common beliefs.
* Published in the 25th International Conference on Pattern Recognition (ICPR'2020), January 2021
Temporal Pulses Driven Spiking Neural Network for Fast Object Recognition in Autonomous Driving
Jan 24, 2020

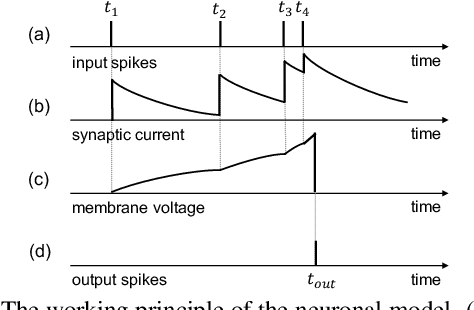

Accurate real-time object recognition from sensory data has long been a crucial and challenging task for autonomous driving. Even though deep neural networks (DNNs) have been successfully applied in this area, most existing methods still heavily rely on the pre-processing of the pulse signals derived from LiDAR sensors, and therefore introduce additional computational overhead and considerable latency. In this paper, we propose an approach to address the object recognition problem directly with raw temporal pulses utilizing the spiking neural network (SNN). Being evaluated on various datasets (including Sim LiDAR, KITTI and DVS-barrel) derived from LiDAR and dynamic vision sensor (DVS), our proposed method has shown comparable performance as the state-of-the-art methods, while achieving remarkable time efficiency. It highlights the SNN's great potentials in autonomous driving and related applications. To the best of our knowledge, this is the first attempt to use SNN to directly perform object recognition on raw temporal pulses.
Deep SCNN-based Real-time Object Detection for Self-driving Vehicles Using LiDAR Temporal Data
Jan 12, 2020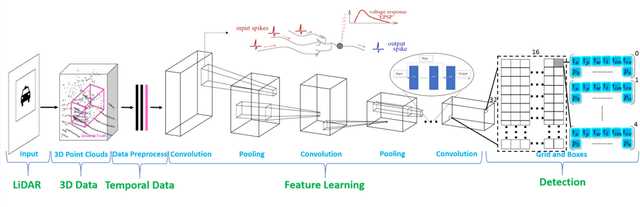
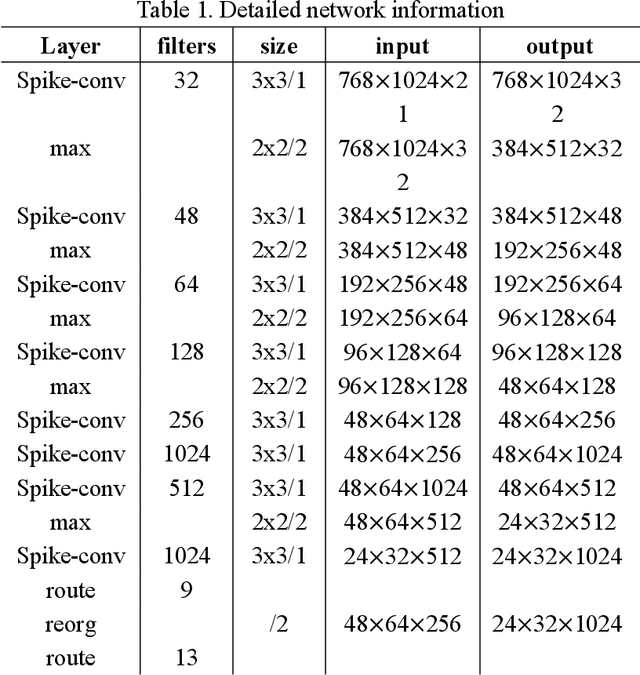
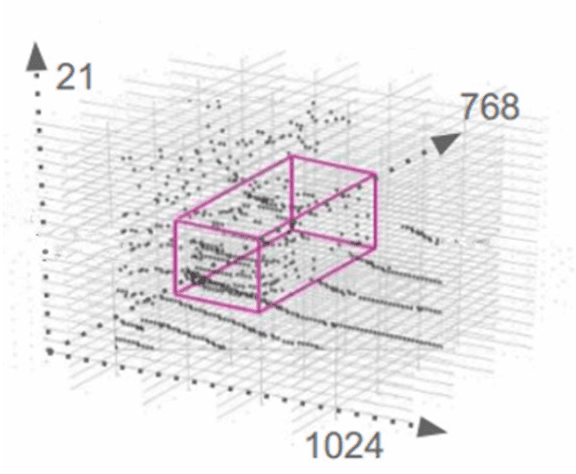
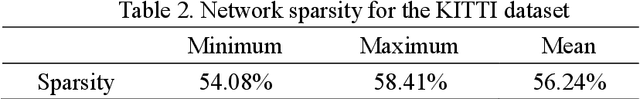
Real-time accurate detection of three-dimensional (3D) objects is a fundamental necessity for self-driving vehicles. Traditional computer-vision approaches are based on convolutional neural networks (CNN). Although the accuracy of using CNN on the KITTI vision benchmark dataset has resulted in great success, few related studies have examined its energy consumption requirements. Spiking neural networks (SNN) and spiking-CNNs (SCNN) have exhibited lower energy consumption rates than CNN. However, few studies have used SNNs or SCNNs to detect objects. Therefore, we developed a novel data preprocessing layer that translates 3D point-cloud spike times into input and employs SCNN on a YOLOv2 architecture to detect objects via spiking signals. Moreover, we present an estimation method for energy consumption and network sparsity. The results demonstrate that the proposed networks ran with a much higher frame rate of 35.7 fps on an NVIDIA GTX 1080i graphical processing unit. Additionally, the proposed networks with skip connections showed better performance than those without skip connections. Both reached state-of-the-art detection accuracy on the KITTI dataset, and our networks consumed an average (low) energy of 0.585 mJ with a mean sparsity of 56.24%.
Direct training based spiking convolutional neural networks for object recognition
Sep 24, 2019

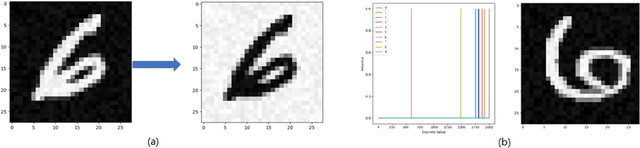
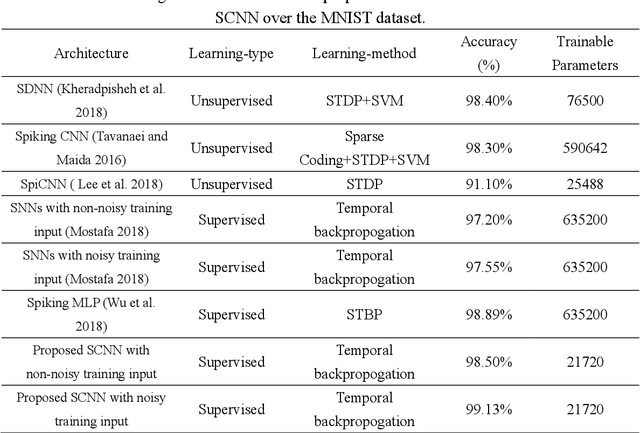
Direct training based spiking neural networks (SNNs) have been paid a lot of attention recently because of its high energy efficiency on emerging neuromorphic hardware. However, due to the non-differentiability of the spiking activity, most of the related SNNs still cannot achieve high object recognition accuracy for the complicated dataset, such as CIFAR-10. Even though some of them can reach the accuracy of 90%, the energy consumption in those networks is very high. Considering this, we propose a direct supervised learning based spiking convolutional neural networks (SCNNs) using temporal coding scheme in this study, aiming to exploit minimum trainable parameters to recognize the object in the image with high accuracy. The MNIST and CIFAR-10 datasets are used to evaluate the performance of the proposed networks. For the MNIST dataset, the proposed networks with noise input are able to reach the high recognition accuracy (99.13%) as the other state-of-art models but use the much less trainable parameters than them. For CIFAR-10 dataset, the proposed networks with data augmentation step can reach the recognition accuracy of 80.49%., which is the state-of-art high accuracy in the field of direct training based SNNs using temporal coding manner. In addition, the number of trainable parameters used in such networks is much less than that in the conversion based SCNNs reported in the literature.