 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing SNN-based Spatio-Temporal Learning: A Benchmark Dataset and Cross-Modality Attention Model
Paper and Code


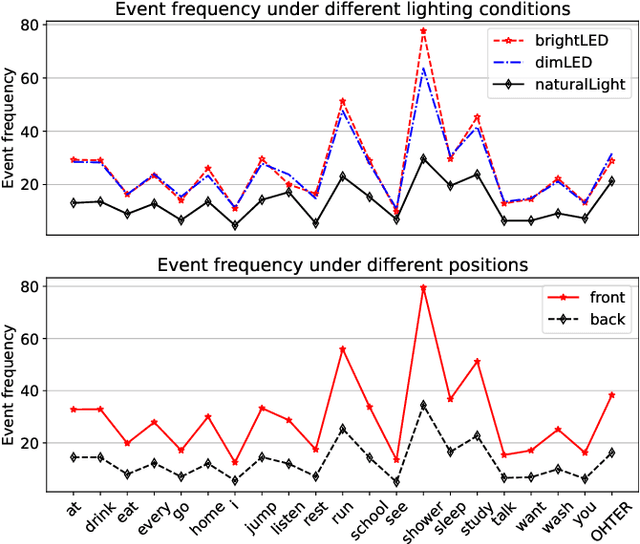
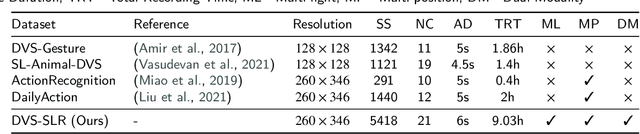
Spiking Neural Networks (SNNs), renowned for their low power consumption, brain-inspired architecture, and spatio-temporal representation capabilities, have garnered considerable attention in recent years. Similar to Artificial Neural Networks (ANNs), high-quality benchmark datasets are of great importance to the advances of SNNs. However, our analysis indicates that many prevalent neuromorphic datasets lack strong temporal correlation, preventing SNNs from fully exploiting their spatio-temporal representation capabilities. Meanwhile, the integration of event and frame modalities offers more comprehensive visual spatio-temporal information. Yet, the SNN-based cross-modality fusion remains underexplored. In this work, we present a neuromorphic dataset called DVS-SLR that can better exploit the inherent spatio-temporal properties of SNNs. Compared to existing datasets, it offers advantages in terms of higher temporal correlation, larger scale, and more varied scenarios. In addition, our neuromorphic dataset contains corresponding frame data, which can be used for developing SNN-based fusion methods. By virtue of the dual-modal feature of the dataset, we propose a Cross-Modality Attention (CMA) based fusion method. The CMA model efficiently utilizes the unique advantages of each modality, allowing for SNNs to learn both temporal and spatial attention scores from the spatio-temporal features of event and frame modalities, subsequently allocating these scores across modalities to enhance their synergy. Experimental results demonstrate that our method not only improves recognition accuracy but also ensures robustness across diverse scenarios.