 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMPD-SGR: Robust Spiking Neural Networks with Membrane Potential Distribution-Driven Surrogate Gradient Regularization
Nov 18, 2025The surrogate gradient (SG) method has shown significant promise in enhancing the performance of deep spiking neural networks (SNNs), but it also introduces vulnerabilities to adversarial attacks. Although spike coding strategies and neural dynamics parameters have been extensively studied for their impact on robustness, the critical role of gradient magnitude, which reflects the model's sensitivity to input perturbations, remains underexplored. In SNNs, the gradient magnitude is primarily determined by the interaction between the membrane potential distribution (MPD) and the SG function. In this study, we investigate the relationship between the MPD and SG and their implications for improving the robustness of SNNs. Our theoretical analysis reveals that reducing the proportion of membrane potentials lying within the gradient-available range of the SG function effectively mitigates the sensitivity of SNNs to input perturbations. Building upon this insight, we propose a novel MPD-driven surrogate gradient regularization (MPD-SGR) method, which enhances robustness by explicitly regularizing the MPD based on its interaction with the SG function. Extensive experiments across multiple image classification benchmarks and diverse network architectures confirm that the MPD-SGR method significantly enhances the resilience of SNNs to adversarial perturbations and exhibits strong generalizability across diverse network configurations, SG functions, and spike encoding schemes.
Effective Clustering for Large Multi-Relational Graphs
Aug 24, 2025Multi-relational graphs (MRGs) are an expressive data structure for modeling diverse interactions/relations among real objects (i.e., nodes), which pervade extensive applications and scenarios. Given an MRG G with N nodes, partitioning the node set therein into K disjoint clusters (MRGC) is a fundamental task in analyzing MRGs, which has garnered considerable attention. However, the majority of existing solutions towards MRGC either yield severely compromised result quality by ineffective fusion of heterogeneous graph structures and attributes, or struggle to cope with sizable MRGs with millions of nodes and billions of edges due to the adoption of sophisticated and costly deep learning models. In this paper, we present DEMM and DEMM+, two effective MRGC approaches to address the limitations above. Specifically, our algorithms are built on novel two-stage optimization objectives, where the former seeks to derive high-caliber node feature vectors by optimizing the multi-relational Dirichlet energy specialized for MRGs, while the latter minimizes the Dirichlet energy of clustering results over the node affinity graph. In particular, DEMM+ achieves significantly higher scalability and efficiency over our based method DEMM through a suite of well-thought-out optimizations. Key technical contributions include (i) a highly efficient approximation solver for constructing node feature vectors, and (ii) a theoretically-grounded problem transformation with carefully-crafted techniques that enable linear-time clustering without explicitly materializing the NxN dense affinity matrix. Further, we extend DEMM+ to handle attribute-less MRGs through non-trivial adaptations. Extensive experiments, comparing DEMM+ against 20 baselines over 11 real MRGs, exhibit that DEMM+ is consistently superior in terms of clustering quality measured against ground-truth labels, while often being remarkably faster.
Community-Aware Social Community Recommendation
Aug 07, 2025Social recommendation, which seeks to leverage social ties among users to alleviate the sparsity issue of user-item interactions, has emerged as a popular technique for elevating personalized services in recommender systems. Despite being effective, existing social recommendation models are mainly devised for recommending regular items such as blogs, images, and products, and largely fail for community recommendations due to overlooking the unique characteristics of communities. Distinctly, communities are constituted by individuals, who present high dynamicity and relate to rich structural patterns in social networks. To our knowledge, limited research has been devoted to comprehensively exploiting this information for recommending communities. To bridge this gap, this paper presents CASO, a novel and effective model specially designed for social community recommendation. Under the hood, CASO harnesses three carefully-crafted encoders for user embedding, wherein two of them extract community-related global and local structures from the social network via social modularity maximization and social closeness aggregation, while the third one captures user preferences using collaborative filtering with observed user-community affiliations. To further eliminate feature redundancy therein, we introduce a mutual exclusion between social and collaborative signals. Finally, CASO includes a community detection loss in the model optimization, thereby producing community-aware embeddings for communities. Our extensive experiments evaluating CASO against nine strong baselines on six real-world social networks demonstrate its consistent and remarkable superiority over the state of the art in terms of community recommendation performance.
Adaptive Gradient Learning for Spiking Neural Networks by Exploiting Membrane Potential Dynamics
May 17, 2025Brain-inspired spiking neural networks (SNNs) are recognized as a promising avenue for achieving efficient, low-energy neuromorphic computing. Recent advancements have focused on directly training high-performance SNNs by estimating the approximate gradients of spiking activity through a continuous function with constant sharpness, known as surrogate gradient (SG) learning. However, as spikes propagate among neurons, the distribution of membrane potential dynamics (MPD) will deviate from the gradient-available interval of fixed SG, hindering SNNs from searching the optimal solution space. To maintain the stability of gradient flows, SG needs to align with evolving MPD. Here, we propose adaptive gradient learning for SNNs by exploiting MPD, namely MPD-AGL. It fully accounts for the underlying factors contributing to membrane potential shifts and establishes a dynamic association between SG and MPD at different timesteps to relax gradient estimation, which provides a new degree of freedom for SG learning. Experimental results demonstrate that our method achieves excellent performance at low latency. Moreover, it increases the proportion of neurons that fall into the gradient-available interval compared to fixed SG, effectively mitigating the gradient vanishing problem.
ASRC-SNN: Adaptive Skip Recurrent Connection Spiking Neural Network
May 16, 2025In recent years, Recurrent Spiking Neural Networks (RSNNs) have shown promising potential in long-term temporal modeling. Many studies focus on improving neuron models and also integrate recurrent structures, leveraging their synergistic effects to improve the long-term temporal modeling capabilities of Spiking Neural Networks (SNNs). However, these studies often place an excessive emphasis on the role of neurons, overlooking the importance of analyzing neurons and recurrent structures as an integrated framework. In this work, we consider neurons and recurrent structures as an integrated system and conduct a systematic analysis of gradient propagation along the temporal dimension, revealing a challenging gradient vanishing problem. To address this issue, we propose the Skip Recurrent Connection (SRC) as a replacement for the vanilla recurrent structure, effectively mitigating the gradient vanishing problem and enhancing long-term temporal modeling performance. Additionally, we propose the Adaptive Skip Recurrent Connection (ASRC), a method that can learn the skip span of skip recurrent connection in each layer of the network. Experiments show that replacing the vanilla recurrent structure in RSNN with SRC significantly improves the model's performance on temporal benchmark datasets. Moreover, ASRC-SNN outperforms SRC-SNN in terms of temporal modeling capabilities and robustness.
Enhancing SNN-based Spatio-Temporal Learning: A Benchmark Dataset and Cross-Modality Attention Model
Oct 21, 2024

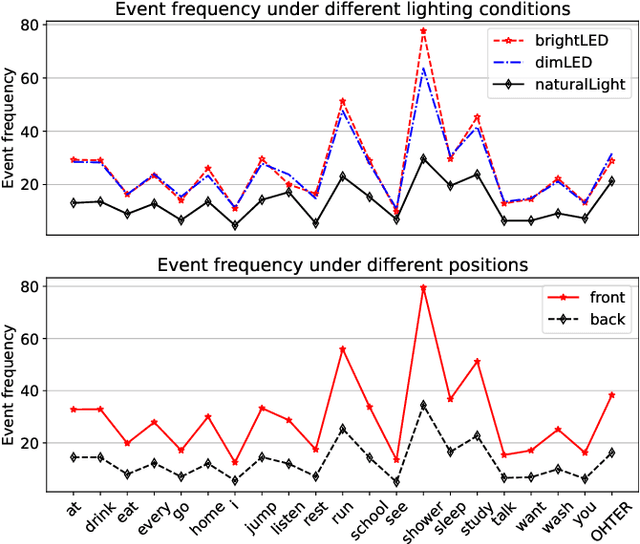
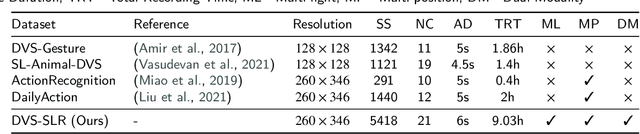
Spiking Neural Networks (SNNs), renowned for their low power consumption, brain-inspired architecture, and spatio-temporal representation capabilities, have garnered considerable attention in recent years. Similar to Artificial Neural Networks (ANNs), high-quality benchmark datasets are of great importance to the advances of SNNs. However, our analysis indicates that many prevalent neuromorphic datasets lack strong temporal correlation, preventing SNNs from fully exploiting their spatio-temporal representation capabilities. Meanwhile, the integration of event and frame modalities offers more comprehensive visual spatio-temporal information. Yet, the SNN-based cross-modality fusion remains underexplored. In this work, we present a neuromorphic dataset called DVS-SLR that can better exploit the inherent spatio-temporal properties of SNNs. Compared to existing datasets, it offers advantages in terms of higher temporal correlation, larger scale, and more varied scenarios. In addition, our neuromorphic dataset contains corresponding frame data, which can be used for developing SNN-based fusion methods. By virtue of the dual-modal feature of the dataset, we propose a Cross-Modality Attention (CMA) based fusion method. The CMA model efficiently utilizes the unique advantages of each modality, allowing for SNNs to learn both temporal and spatial attention scores from the spatio-temporal features of event and frame modalities, subsequently allocating these scores across modalities to enhance their synergy. Experimental results demonstrate that our method not only improves recognition accuracy but also ensures robustness across diverse scenarios.
GRSN: Gated Recurrent Spiking Neurons for POMDPs and MARL
Apr 24, 2024



Spiking neural networks (SNNs) are widely applied in various fields due to their energy-efficient and fast-inference capabilities. Applying SNNs to reinforcement learning (RL) can significantly reduce the computational resource requirements for agents and improve the algorithm's performance under resource-constrained conditions. However, in current spiking reinforcement learning (SRL) algorithms, the simulation results of multiple time steps can only correspond to a single-step decision in RL. This is quite different from the real temporal dynamics in the brain and also fails to fully exploit the capacity of SNNs to process temporal data. In order to address this temporal mismatch issue and further take advantage of the inherent temporal dynamics of spiking neurons, we propose a novel temporal alignment paradigm (TAP) that leverages the single-step update of spiking neurons to accumulate historical state information in RL and introduces gated units to enhance the memory capacity of spiking neurons. Experimental results show that our method can solve partially observable Markov decision processes (POMDPs) and multi-agent cooperation problems with similar performance as recurrent neural networks (RNNs) but with about 50% power consumption.
EAS-SNN: End-to-End Adaptive Sampling and Representation for Event-based Detection with Recurrent Spiking Neural Networks
Mar 19, 2024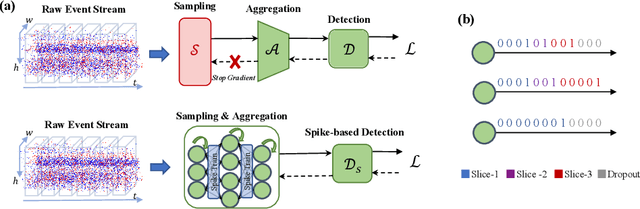
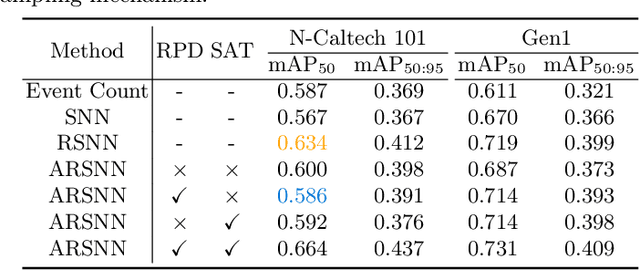
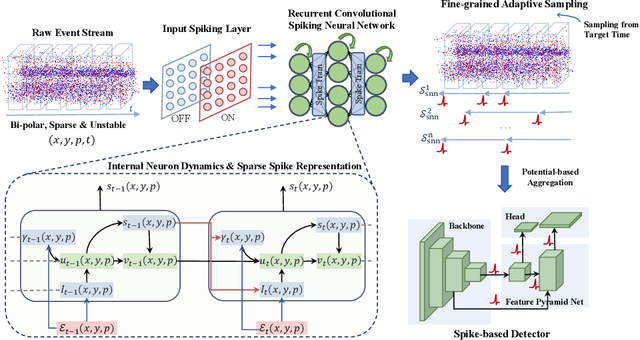
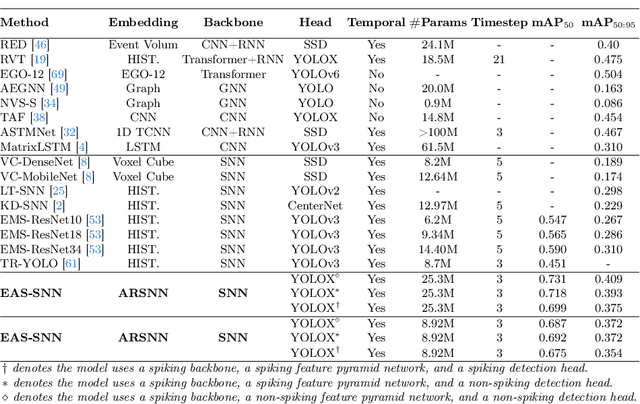
Event cameras, with their high dynamic range and temporal resolution, are ideally suited for object detection, especially under scenarios with motion blur and challenging lighting conditions. However, while most existing approaches prioritize optimizing spatiotemporal representations with advanced detection backbones and early aggregation functions, the crucial issue of adaptive event sampling remains largely unaddressed. Spiking Neural Networks (SNNs), which operate on an event-driven paradigm through sparse spike communication, emerge as a natural fit for addressing this challenge. In this study, we discover that the neural dynamics of spiking neurons align closely with the behavior of an ideal temporal event sampler. Motivated by this insight, we propose a novel adaptive sampling module that leverages recurrent convolutional SNNs enhanced with temporal memory, facilitating a fully end-to-end learnable framework for event-based detection. Additionally, we introduce Residual Potential Dropout (RPD) and Spike-Aware Training (SAT) to regulate potential distribution and address performance degradation encountered in spike-based sampling modules. Through rigorous testing on neuromorphic datasets for event-based detection, our approach demonstrably surpasses existing state-of-the-art spike-based methods, achieving superior performance with significantly fewer parameters and time steps. For instance, our method achieves a 4.4\% mAP improvement on the Gen1 dataset, while requiring 38\% fewer parameters and three time steps. Moreover, the applicability and effectiveness of our adaptive sampling methodology extend beyond SNNs, as demonstrated through further validation on conventional non-spiking detection models.
Temporal Conditioning Spiking Latent Variable Models of the Neural Response to Natural Visual Scenes
Jul 11, 2023Developing computational models of neural response is crucial for understanding sensory processing and neural computations. Current state-of-the-art neural network methods use temporal filters to handle temporal dependencies, resulting in an unrealistic and inflexible processing flow. Meanwhile, these methods target trial-averaged firing rates and fail to capture important features in spike trains. This work presents the temporal conditioning spiking latent variable models (TeCoS-LVM) to simulate the neural response to natural visual stimuli. We use spiking neurons to produce spike outputs that directly match the recorded trains. This approach helps to avoid losing information embedded in the original spike trains. We exclude the temporal dimension from the model parameter space and introduce a temporal conditioning operation to allow the model to adaptively explore and exploit temporal dependencies in stimuli sequences in a natural paradigm. We show that TeCoS-LVM models can produce more realistic spike activities and accurately fit spike statistics than powerful alternatives. Additionally, learned TeCoS-LVM models can generalize well to longer time scales. Overall, while remaining computationally tractable, our model effectively captures key features of neural coding systems. It thus provides a useful tool for building accurate predictive computational accounts for various sensory perception circuits.