 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASRC-SNN: Adaptive Skip Recurrent Connection Spiking Neural Network
May 16, 2025In recent years, Recurrent Spiking Neural Networks (RSNNs) have shown promising potential in long-term temporal modeling. Many studies focus on improving neuron models and also integrate recurrent structures, leveraging their synergistic effects to improve the long-term temporal modeling capabilities of Spiking Neural Networks (SNNs). However, these studies often place an excessive emphasis on the role of neurons, overlooking the importance of analyzing neurons and recurrent structures as an integrated framework. In this work, we consider neurons and recurrent structures as an integrated system and conduct a systematic analysis of gradient propagation along the temporal dimension, revealing a challenging gradient vanishing problem. To address this issue, we propose the Skip Recurrent Connection (SRC) as a replacement for the vanilla recurrent structure, effectively mitigating the gradient vanishing problem and enhancing long-term temporal modeling performance. Additionally, we propose the Adaptive Skip Recurrent Connection (ASRC), a method that can learn the skip span of skip recurrent connection in each layer of the network. Experiments show that replacing the vanilla recurrent structure in RSNN with SRC significantly improves the model's performance on temporal benchmark datasets. Moreover, ASRC-SNN outperforms SRC-SNN in terms of temporal modeling capabilities and robustness.
HCPM: Hierarchical Candidates Pruning for Efficient Detector-Free Matching
Mar 19, 2024Deep learning-based image matching methods play a crucial role in computer vision, yet they often suffer from substantial computational demands. To tackle this challenge, we present HCPM, an efficient and detector-free local feature-matching method that employs hierarchical pruning to optimize the matching pipeline. In contrast to recent detector-free methods that depend on an exhaustive set of coarse-level candidates for matching, HCPM selectively concentrates on a concise subset of informative candidates, resulting in fewer computational candidates and enhanced matching efficiency. The method comprises a self-pruning stage for selecting reliable candidates and an interactive-pruning stage that identifies correlated patches at the coarse level. Our results reveal that HCPM significantly surpasses existing methods in terms of speed while maintaining high accuracy. The source code will be made available upon publication.
FusionDepth: Complement Self-Supervised Monocular Depth Estimation with Cost Volume
May 10, 2023Multi-view stereo depth estimation based on cost volume usually works better than self-supervised monocular depth estimation except for moving objects and low-textured surfaces. So in this paper, we propose a multi-frame depth estimation framework which monocular depth can be refined continuously by multi-frame sequential constraints, leveraging a Bayesian fusion layer within several iterations. Both monocular and multi-view networks can be trained with no depth supervision. Our method also enhances the interpretability when combining monocular estimation with multi-view cost volume. Detailed experiments show that our method surpasses state-of-the-art unsupervised methods utilizing single or multiple frames at test time on KITTI benchmark.
Scatter Points in Space: 3D Detection from Multi-view Monocular Images
Aug 31, 2022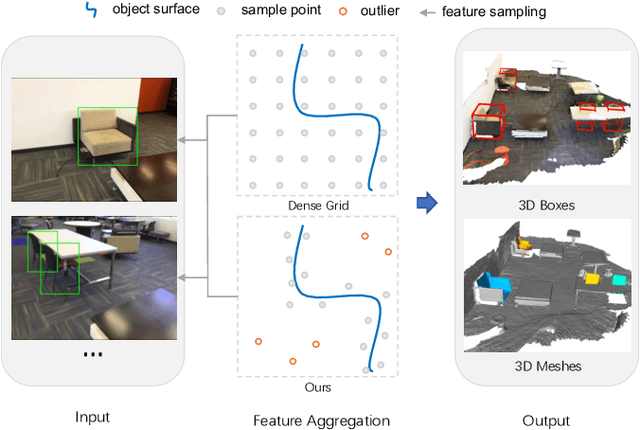
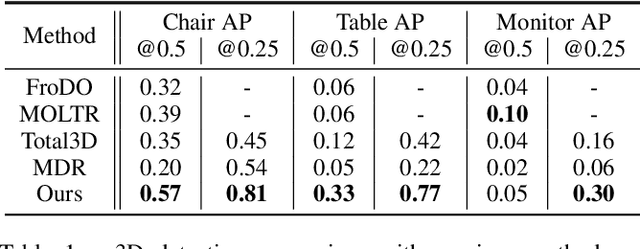
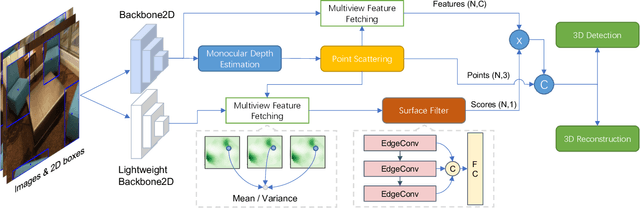
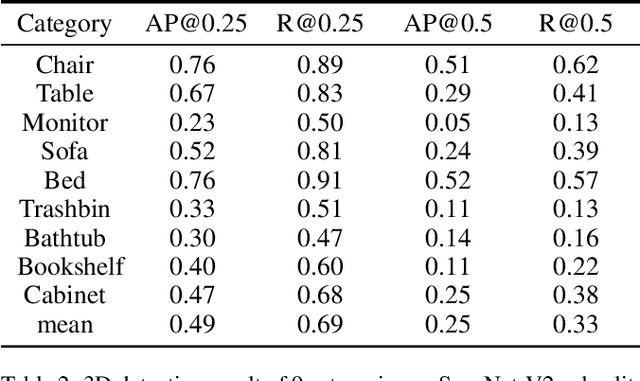
3D object detection from monocular image(s) is a challenging and long-standing problem of computer vision. To combine information from different perspectives without troublesome 2D instance tracking, recent methods tend to aggregate multiview feature by sampling regular 3D grid densely in space, which is inefficient. In this paper, we attempt to improve multi-view feature aggregation by proposing a learnable keypoints sampling method, which scatters pseudo surface points in 3D space, in order to keep data sparsity. The scattered points augmented by multi-view geometric constraints and visual features are then employed to infer objects location and shape in the scene. To make up the limitations of single frame and model multi-view geometry explicitly, we further propose a surface filter module for noise suppression. Experimental results show that our method achieves significantly better performance than previous works in terms of 3D detection (more than 0.1 AP improvement on some categories of ScanNet). The code will be publicly available.
Adaptive Assignment for Geometry Aware Local Feature Matching
Jul 18, 2022
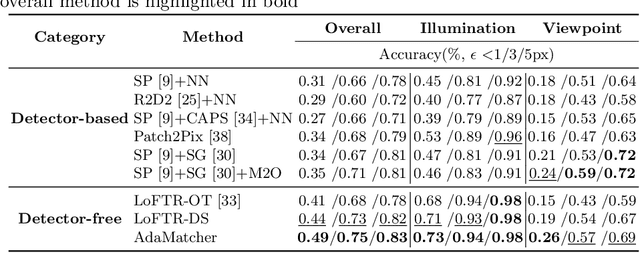
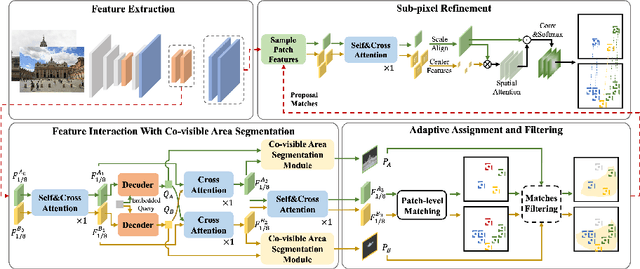
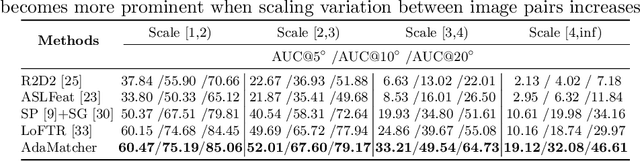
Local image feature matching, aiming to identify and correspond similar regions from image pairs, is an essential concept in computer vision. Most existing image matching approaches follow a one-to-one assignment principle and employ mutual nearest neighbor to guarantee unique correspondence between local features across images. However, images from different conditions may hold large-scale variations or viewpoint diversification so that one-to-one assignment may cause ambiguous or missing representations in dense matching. In this paper, we introduce AdaMatcher, a novel detector-free local feature matching method, which first correlates dense features by a lightweight feature interaction module and estimates co-visible area of the paired images, then performs a patch-level many-to-one assignment to predict match proposals, and finally refines them based on a one-to-one refinement module. Extensive experiments show that AdaMatcher outperforms solid baselines and achieves state-of-the-art results on many downstream tasks. Additionally, the many-to-one assignment and one-to-one refinement module can be used as a refinement network for other matching methods, such as SuperGlue, to boost their performance further. Code will be available upon publication.
UniInst: Unique Representation for End-to-End Instance Segmentation
May 26, 2022

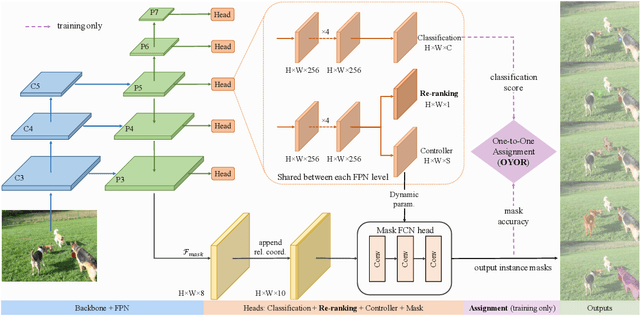

Existing instance segmentation methods have achieved impressive performance but still suffer from a common dilemma: redundant representations (e.g., multiple boxes, grids, and anchor points) are inferred for one instance, which leads to multiple duplicated predictions. Thus, mainstream methods usually rely on a hand-designed non-maximum suppression (NMS) post-processing step to select the optimal prediction result, which hinders end-to-end training. To address this issue, we propose a box-free and NMS-free end-to-end instance segmentation framework, termed UniInst, that yields only one unique representation for each instance. Specifically, we design an instance-aware one-to-one assignment scheme, namely Only Yield One Representation (OYOR), which dynamically assigns one unique representation to each instance according to the matching quality between predictions and ground truths. Then, a novel prediction re-ranking strategy is elegantly integrated into the framework to address the misalignment between the classification score and the mask quality, enabling the learned representation to be more discriminative. With these techniques, our UniInst, the first FCN-based end-to-end instance segmentation framework, achieves competitive performance, e.g., 39.0 mask AP using ResNet-50-FPN and 40.2 mask AP using ResNet-101-FPN, against mainstream methods on COCO test-dev. Moreover, the proposed instance-aware method is robust to occlusion scenes, outperforming common baselines by remarkable mask AP on the heavily-occluded OCHuman benchmark. Our codes will be available upon publication.
Guide Local Feature Matching by Overlap Estimation
Feb 23, 2022
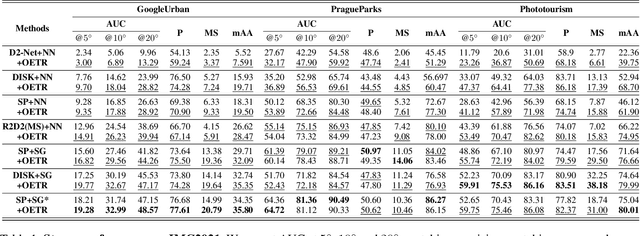
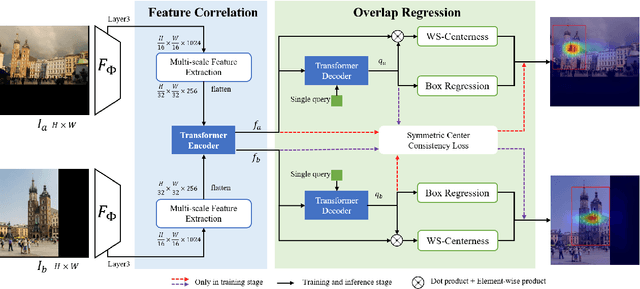
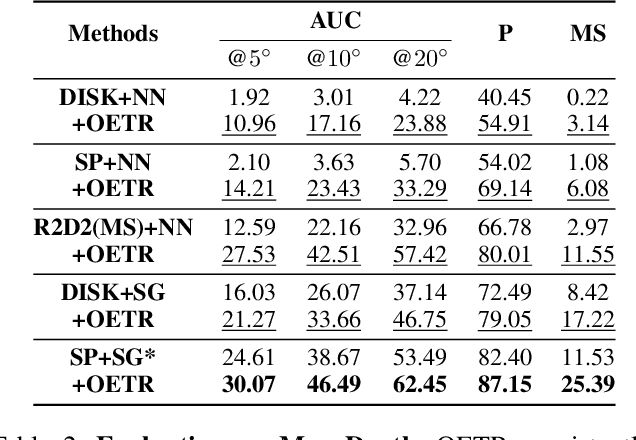
Local image feature matching under large appearance, viewpoint, and distance changes is challenging yet important. Conventional methods detect and match tentative local features across the whole images, with heuristic consistency checks to guarantee reliable matches. In this paper, we introduce a novel Overlap Estimation method conditioned on image pairs with TRansformer, named OETR, to constrain local feature matching in the commonly visible region. OETR performs overlap estimation in a two-step process of feature correlation and then overlap regression. As a preprocessing module, OETR can be plugged into any existing local feature detection and matching pipeline, to mitigate potential view angle or scale variance. Intensive experiments show that OETR can boost state-of-the-art local feature matching performance substantially, especially for image pairs with small shared regions. The code will be publicly available at https://github.com/AbyssGaze/OETR.