 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Transfer Learning Method Utilizing Acoustic and Vibration Signals for Rotating Machinery Fault Diagnosis
Oct 20, 2023


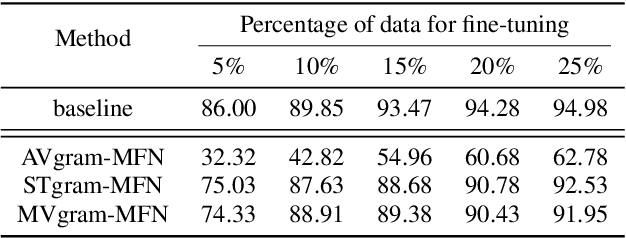
Fault diagnosis of rotating machinery plays a important role for the safety and stability of modern industrial systems. However, there is a distribution discrepancy between training data and data of real-world operation scenarios, which causing the decrease of performance of existing systems. This paper proposed a transfer learning based method utilizing acoustic and vibration signal to address this distribution discrepancy. We designed the acoustic and vibration feature fusion MAVgram to offer richer and more reliable information of faults, coordinating with a DNN-based classifier to obtain more effective diagnosis representation. The backbone was pre-trained and then fine-tuned to obtained excellent performance of the target task. Experimental results demonstrate the effectiveness of the proposed method, and achieved improved performance compared to STgram-MFN.
FusionDepth: Complement Self-Supervised Monocular Depth Estimation with Cost Volume
May 10, 2023Multi-view stereo depth estimation based on cost volume usually works better than self-supervised monocular depth estimation except for moving objects and low-textured surfaces. So in this paper, we propose a multi-frame depth estimation framework which monocular depth can be refined continuously by multi-frame sequential constraints, leveraging a Bayesian fusion layer within several iterations. Both monocular and multi-view networks can be trained with no depth supervision. Our method also enhances the interpretability when combining monocular estimation with multi-view cost volume. Detailed experiments show that our method surpasses state-of-the-art unsupervised methods utilizing single or multiple frames at test time on KITTI benchmark.
Scatter Points in Space: 3D Detection from Multi-view Monocular Images
Aug 31, 2022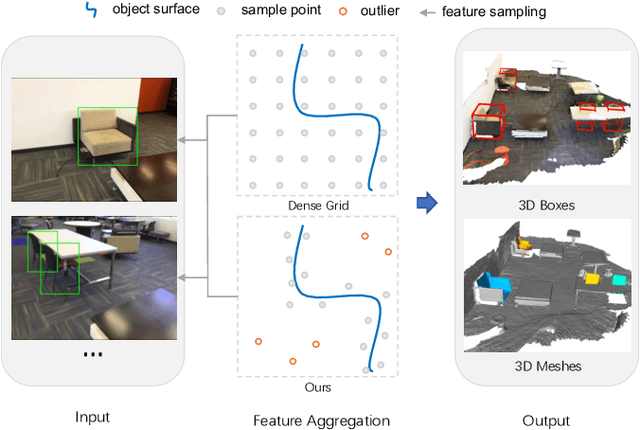
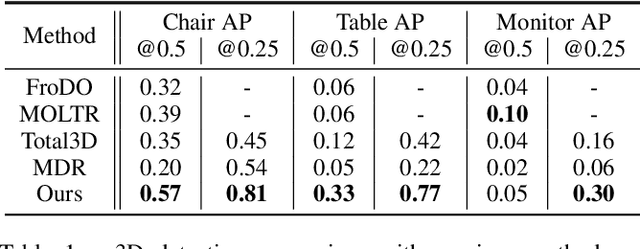
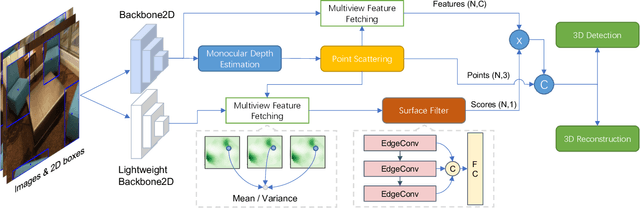
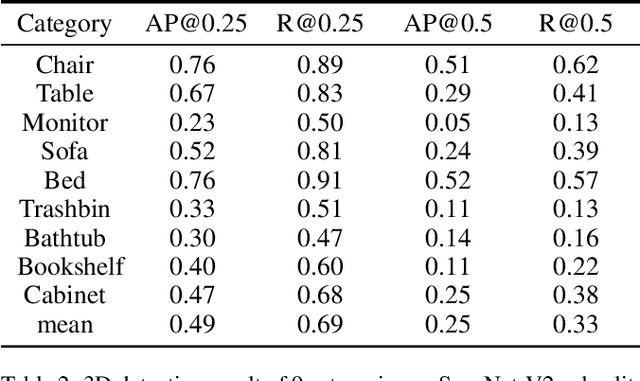
3D object detection from monocular image(s) is a challenging and long-standing problem of computer vision. To combine information from different perspectives without troublesome 2D instance tracking, recent methods tend to aggregate multiview feature by sampling regular 3D grid densely in space, which is inefficient. In this paper, we attempt to improve multi-view feature aggregation by proposing a learnable keypoints sampling method, which scatters pseudo surface points in 3D space, in order to keep data sparsity. The scattered points augmented by multi-view geometric constraints and visual features are then employed to infer objects location and shape in the scene. To make up the limitations of single frame and model multi-view geometry explicitly, we further propose a surface filter module for noise suppression. Experimental results show that our method achieves significantly better performance than previous works in terms of 3D detection (more than 0.1 AP improvement on some categories of ScanNet). The code will be publicly available.
Stochastic Bundle Adjustment for Efficient and Scalable 3D Reconstruction
Aug 02, 2020
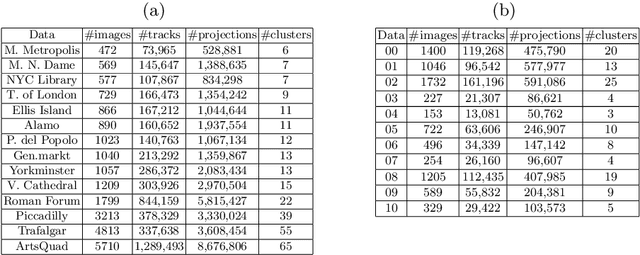


Current bundle adjustment solvers such as the Levenberg-Marquardt (LM) algorithm are limited by the bottleneck in solving the Reduced Camera System (RCS) whose dimension is proportional to the camera number. When the problem is scaled up, this step is neither efficient in computation nor manageable for a single compute node. In this work, we propose a stochastic bundle adjustment algorithm which seeks to decompose the RCS approximately inside the LM iterations to improve the efficiency and scalability. It first reformulates the quadratic programming problem of an LM iteration based on the clustering of the visibility graph by introducing the equality constraints across clusters. Then, we propose to relax it into a chance constrained problem and solve it through sampled convex program. The relaxation is intended to eliminate the interdependence between clusters embodied by the constraints, so that a large RCS can be decomposed into independent linear sub-problems. Numerical experiments on unordered Internet image sets and sequential SLAM image sets, as well as distributed experiments on large-scale datasets, have demonstrated the high efficiency and scalability of the proposed approach. Codes are released at https://github.com/zlthinker/STBA.