 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Dimensionality Reduction in Grid-based 3D Object Detection
Sep 24, 2022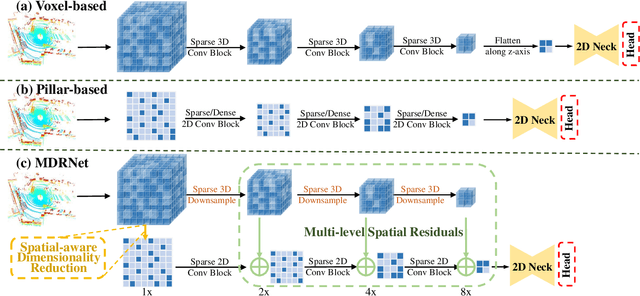
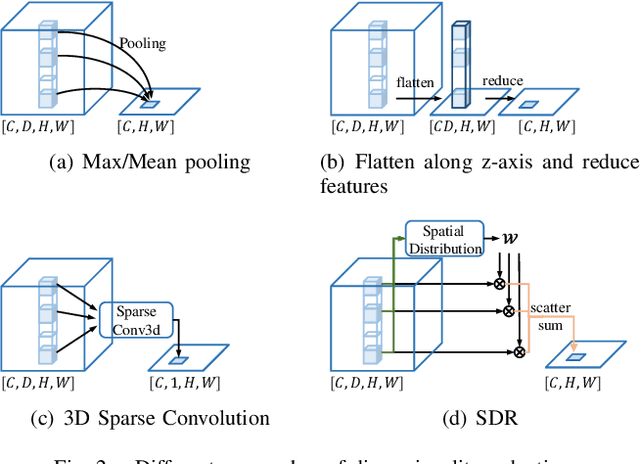

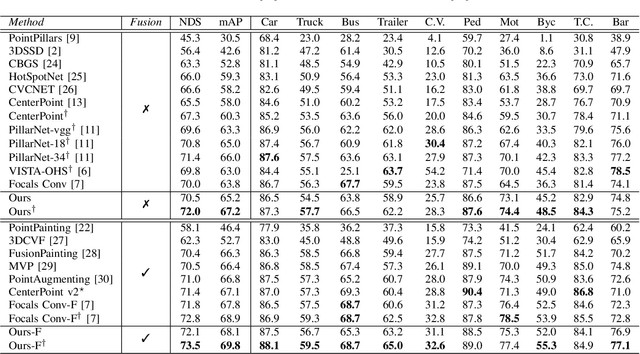
Bird's eye view (BEV) is widely adopted by most of the current point cloud detectors due to the applicability of well-explored 2D detection techniques. However, existing methods obtain BEV features by simply collapsing voxel or point features along the height dimension, which causes the heavy loss of 3D spatial information. To alleviate the information loss, we propose a novel point cloud detection network based on a Multi-level feature dimensionality reduction strategy, called MDRNet. In MDRNet, the Spatial-aware Dimensionality Reduction (SDR) is designed to dynamically focus on the valuable parts of the object during voxel-to-BEV feature transformation. Furthermore, the Multi-level Spatial Residuals (MSR) is proposed to fuse the multi-level spatial information in the BEV feature maps. Extensive experiments on nuScenes show that the proposed method outperforms the state-of-the-art methods. The code will be available upon publication.
Scatter Points in Space: 3D Detection from Multi-view Monocular Images
Aug 31, 2022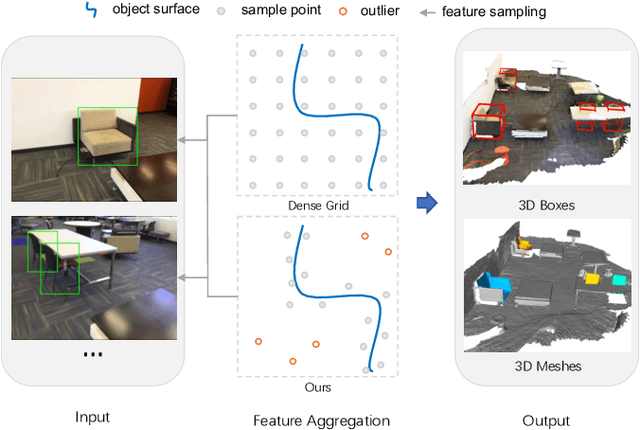
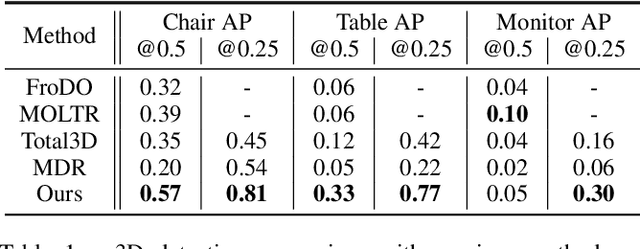
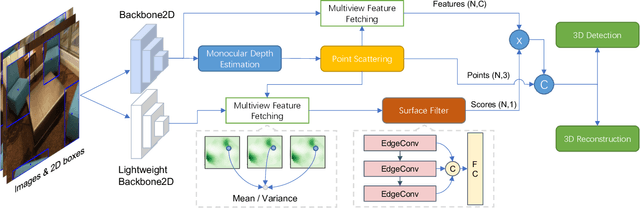
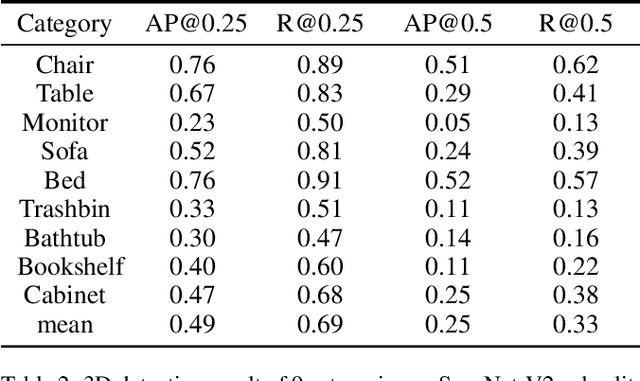
3D object detection from monocular image(s) is a challenging and long-standing problem of computer vision. To combine information from different perspectives without troublesome 2D instance tracking, recent methods tend to aggregate multiview feature by sampling regular 3D grid densely in space, which is inefficient. In this paper, we attempt to improve multi-view feature aggregation by proposing a learnable keypoints sampling method, which scatters pseudo surface points in 3D space, in order to keep data sparsity. The scattered points augmented by multi-view geometric constraints and visual features are then employed to infer objects location and shape in the scene. To make up the limitations of single frame and model multi-view geometry explicitly, we further propose a surface filter module for noise suppression. Experimental results show that our method achieves significantly better performance than previous works in terms of 3D detection (more than 0.1 AP improvement on some categories of ScanNet). The code will be publicly available.
Adaptive Assignment for Geometry Aware Local Feature Matching
Jul 18, 2022
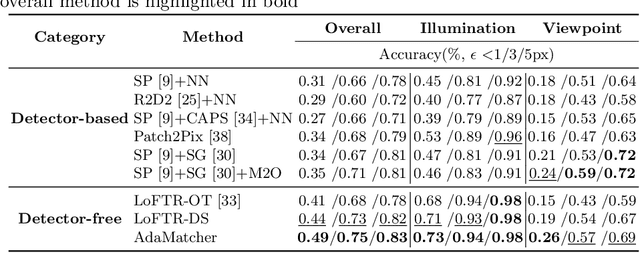
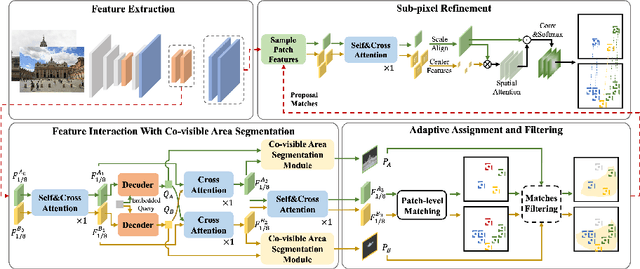
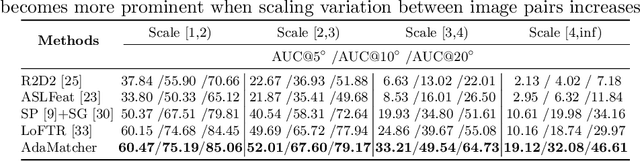
Local image feature matching, aiming to identify and correspond similar regions from image pairs, is an essential concept in computer vision. Most existing image matching approaches follow a one-to-one assignment principle and employ mutual nearest neighbor to guarantee unique correspondence between local features across images. However, images from different conditions may hold large-scale variations or viewpoint diversification so that one-to-one assignment may cause ambiguous or missing representations in dense matching. In this paper, we introduce AdaMatcher, a novel detector-free local feature matching method, which first correlates dense features by a lightweight feature interaction module and estimates co-visible area of the paired images, then performs a patch-level many-to-one assignment to predict match proposals, and finally refines them based on a one-to-one refinement module. Extensive experiments show that AdaMatcher outperforms solid baselines and achieves state-of-the-art results on many downstream tasks. Additionally, the many-to-one assignment and one-to-one refinement module can be used as a refinement network for other matching methods, such as SuperGlue, to boost their performance further. Code will be available upon publication.
Enhancing Multi-view Stereo with Contrastive Matching and Weighted Focal Loss
Jun 21, 2022
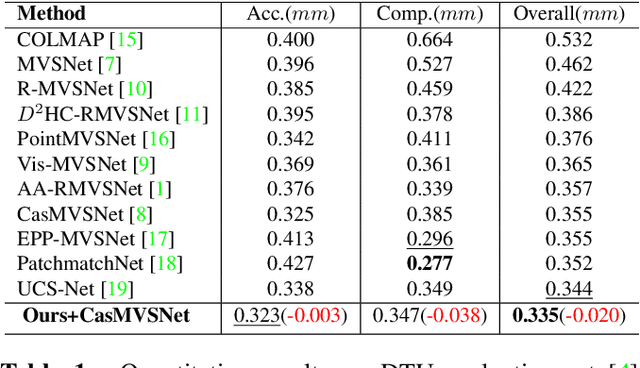


Learning-based multi-view stereo (MVS) methods have made impressive progress and surpassed traditional methods in recent years. However, their accuracy and completeness are still struggling. In this paper, we propose a new method to enhance the performance of existing networks inspired by contrastive learning and feature matching. First, we propose a Contrast Matching Loss (CML), which treats the correct matching points in depth-dimension as positive sample and other points as negative samples, and computes the contrastive loss based on the similarity of features. We further propose a Weighted Focal Loss (WFL) for better classification capability, which weakens the contribution of low-confidence pixels in unimportant areas to the loss according to predicted confidence. Extensive experiments performed on DTU, Tanks and Temples and BlendedMVS datasets show our method achieves state-of-the-art performance and significant improvement over baseline network.
WT-MVSNet: Window-based Transformers for Multi-view Stereo
May 28, 2022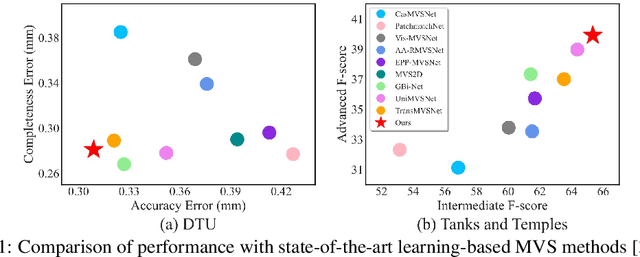
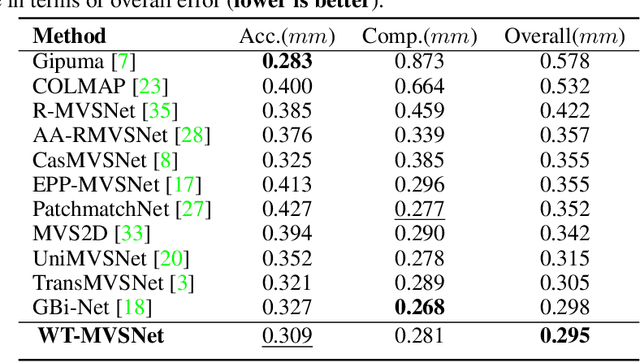
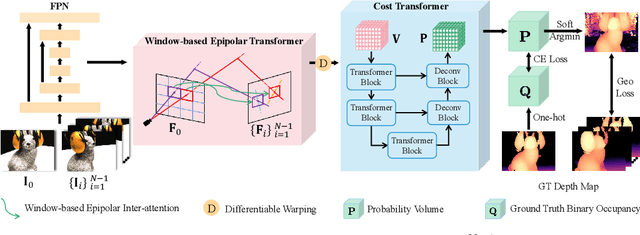
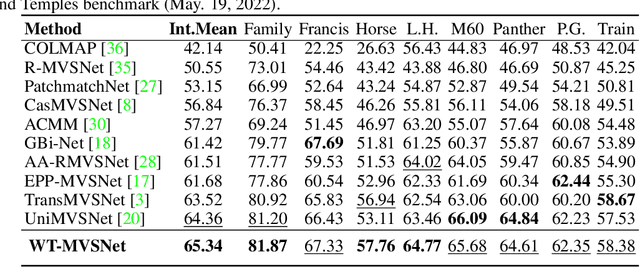
Recently, Transformers were shown to enhance the performance of multi-view stereo by enabling long-range feature interaction. In this work, we propose Window-based Transformers (WT) for local feature matching and global feature aggregation in multi-view stereo. We introduce a Window-based Epipolar Transformer (WET) which reduces matching redundancy by using epipolar constraints. Since point-to-line matching is sensitive to erroneous camera pose and calibration, we match windows near the epipolar lines. A second Shifted WT is employed for aggregating global information within cost volume. We present a novel Cost Transformer (CT) to replace 3D convolutions for cost volume regularization. In order to better constrain the estimated depth maps from multiple views, we further design a novel geometric consistency loss (Geo Loss) which punishes unreliable areas where multi-view consistency is not satisfied. Our WT multi-view stereo method (WT-MVSNet) achieves state-of-the-art performance across multiple datasets and ranks $1^{st}$ on Tanks and Temples benchmark.
Guide Local Feature Matching by Overlap Estimation
Feb 23, 2022
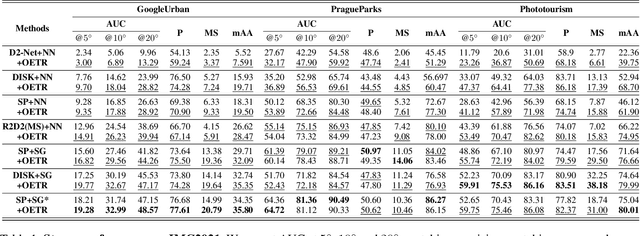
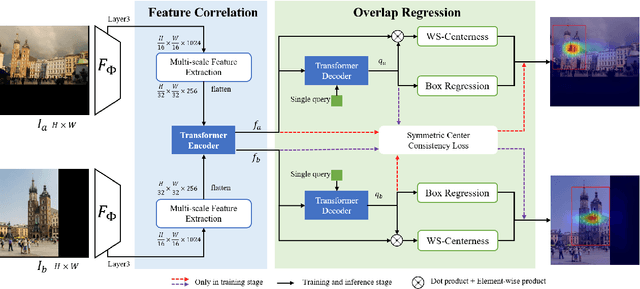
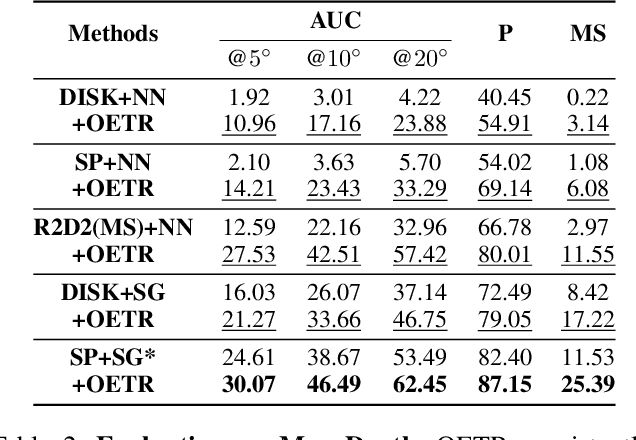
Local image feature matching under large appearance, viewpoint, and distance changes is challenging yet important. Conventional methods detect and match tentative local features across the whole images, with heuristic consistency checks to guarantee reliable matches. In this paper, we introduce a novel Overlap Estimation method conditioned on image pairs with TRansformer, named OETR, to constrain local feature matching in the commonly visible region. OETR performs overlap estimation in a two-step process of feature correlation and then overlap regression. As a preprocessing module, OETR can be plugged into any existing local feature detection and matching pipeline, to mitigate potential view angle or scale variance. Intensive experiments show that OETR can boost state-of-the-art local feature matching performance substantially, especially for image pairs with small shared regions. The code will be publicly available at https://github.com/AbyssGaze/OETR.