 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnimus3D: Text-driven 3D Animation via Motion Score Distillation
Dec 14, 2025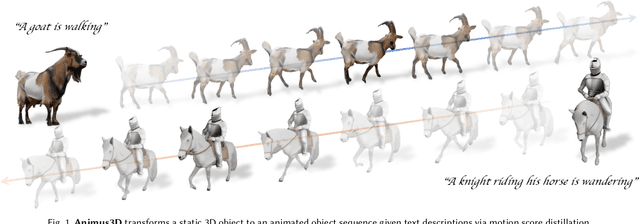
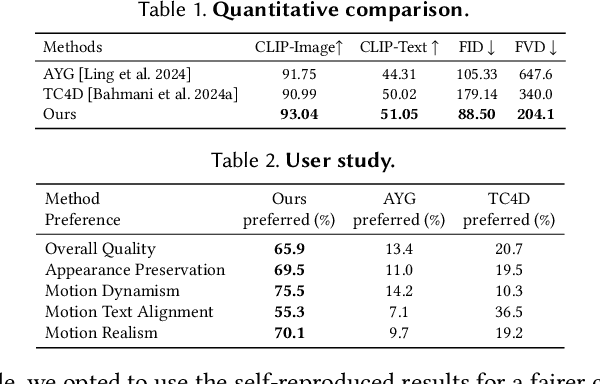
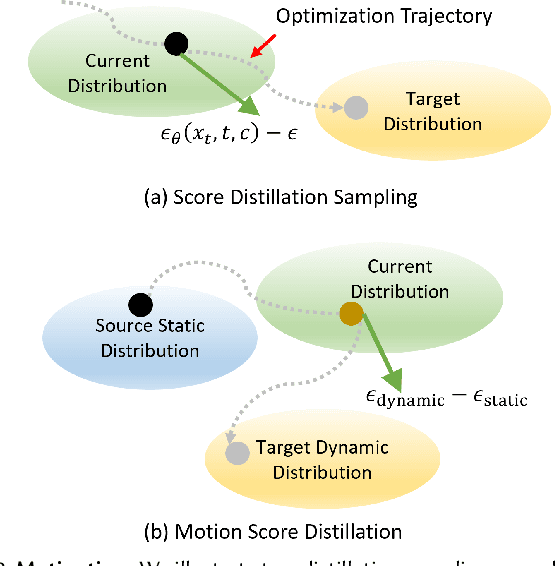
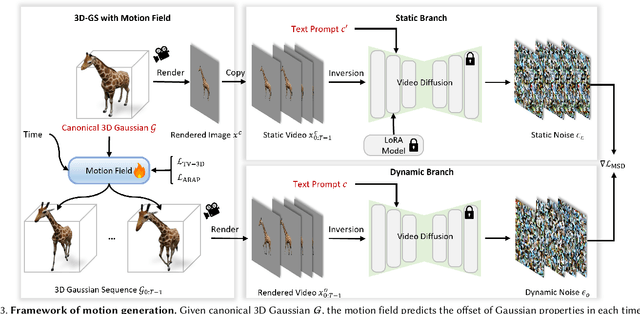
We present Animus3D, a text-driven 3D animation framework that generates motion field given a static 3D asset and text prompt. Previous methods mostly leverage the vanilla Score Distillation Sampling (SDS) objective to distill motion from pretrained text-to-video diffusion, leading to animations with minimal movement or noticeable jitter. To address this, our approach introduces a novel SDS alternative, Motion Score Distillation (MSD). Specifically, we introduce a LoRA-enhanced video diffusion model that defines a static source distribution rather than pure noise as in SDS, while another inversion-based noise estimation technique ensures appearance preservation when guiding motion. To further improve motion fidelity, we incorporate explicit temporal and spatial regularization terms that mitigate geometric distortions across time and space. Additionally, we propose a motion refinement module to upscale the temporal resolution and enhance fine-grained details, overcoming the fixed-resolution constraints of the underlying video model. Extensive experiments demonstrate that Animus3D successfully animates static 3D assets from diverse text prompts, generating significantly more substantial and detailed motion than state-of-the-art baselines while maintaining high visual integrity. Code will be released at https://qiisun.github.io/animus3d_page.
MV-Performer: Taming Video Diffusion Model for Faithful and Synchronized Multi-view Performer Synthesis
Oct 08, 2025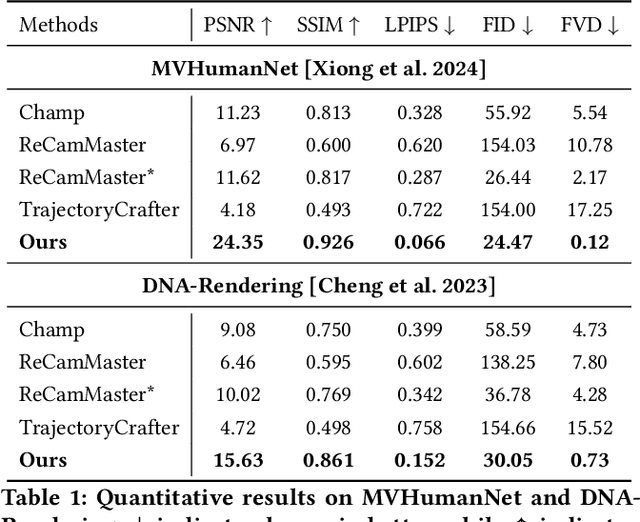

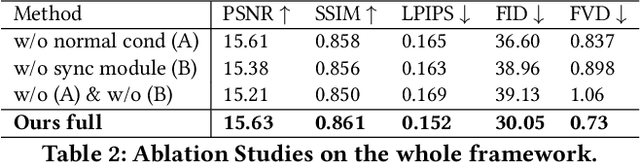
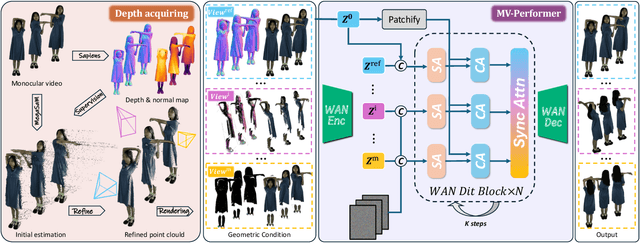
Recent breakthroughs in video generation, powered by large-scale datasets and diffusion techniques, have shown that video diffusion models can function as implicit 4D novel view synthesizers. Nevertheless, current methods primarily concentrate on redirecting camera trajectory within the front view while struggling to generate 360-degree viewpoint changes. In this paper, we focus on human-centric subdomain and present MV-Performer, an innovative framework for creating synchronized novel view videos from monocular full-body captures. To achieve a 360-degree synthesis, we extensively leverage the MVHumanNet dataset and incorporate an informative condition signal. Specifically, we use the camera-dependent normal maps rendered from oriented partial point clouds, which effectively alleviate the ambiguity between seen and unseen observations. To maintain synchronization in the generated videos, we propose a multi-view human-centric video diffusion model that fuses information from the reference video, partial rendering, and different viewpoints. Additionally, we provide a robust inference procedure for in-the-wild video cases, which greatly mitigates the artifacts induced by imperfect monocular depth estimation. Extensive experiments on three datasets demonstrate our MV-Performer's state-of-the-art effectiveness and robustness, setting a strong model for human-centric 4D novel view synthesis.
MA-NeRF: Motion-Assisted Neural Radiance Fields for Face Synthesis from Sparse Images
Jun 24, 2023We address the problem of photorealistic 3D face avatar synthesis from sparse images. Existing Parametric models for face avatar reconstruction struggle to generate details that originate from inputs. Meanwhile, although current NeRF-based avatar methods provide promising results for novel view synthesis, they fail to generalize well for unseen expressions. We improve from NeRF and propose a novel framework that, by leveraging the parametric 3DMM models, can reconstruct a high-fidelity drivable face avatar and successfully handle the unseen expressions. At the core of our implementation are structured displacement feature and semantic-aware learning module. Our structured displacement feature will introduce the motion prior as an additional constraints and help perform better for unseen expressions, by constructing displacement volume. Besides, the semantic-aware learning incorporates multi-level prior, e.g., semantic embedding, learnable latent code, to lift the performance to a higher level. Thorough experiments have been doen both quantitatively and qualitatively to demonstrate the design of our framework, and our method achieves much better results than the current state-of-the-arts.
WT-MVSNet: Window-based Transformers for Multi-view Stereo
May 28, 2022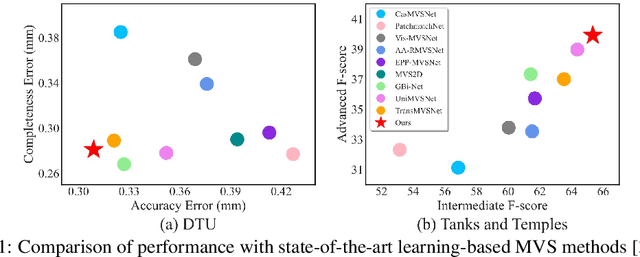
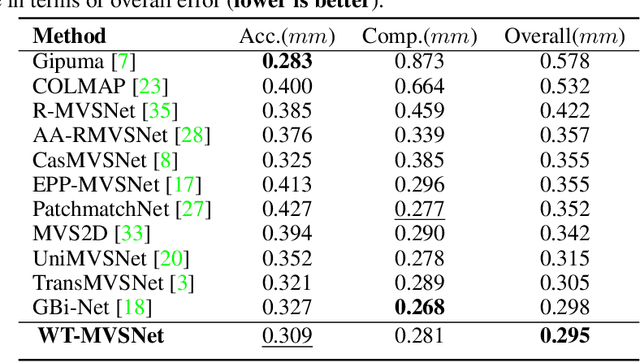
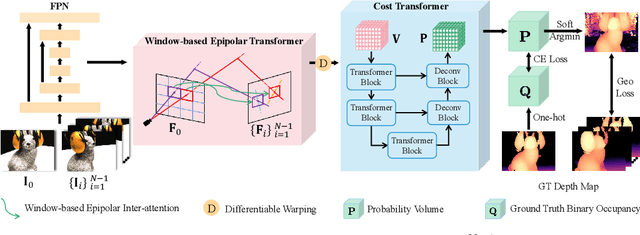
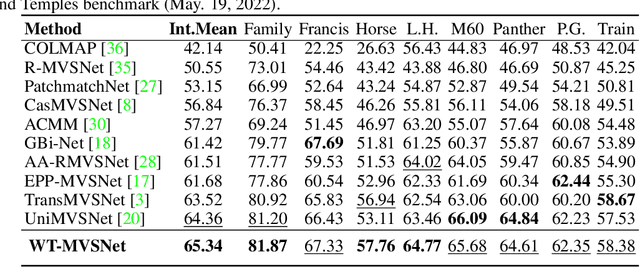
Recently, Transformers were shown to enhance the performance of multi-view stereo by enabling long-range feature interaction. In this work, we propose Window-based Transformers (WT) for local feature matching and global feature aggregation in multi-view stereo. We introduce a Window-based Epipolar Transformer (WET) which reduces matching redundancy by using epipolar constraints. Since point-to-line matching is sensitive to erroneous camera pose and calibration, we match windows near the epipolar lines. A second Shifted WT is employed for aggregating global information within cost volume. We present a novel Cost Transformer (CT) to replace 3D convolutions for cost volume regularization. In order to better constrain the estimated depth maps from multiple views, we further design a novel geometric consistency loss (Geo Loss) which punishes unreliable areas where multi-view consistency is not satisfied. Our WT multi-view stereo method (WT-MVSNet) achieves state-of-the-art performance across multiple datasets and ranks $1^{st}$ on Tanks and Temples benchmark.
Adversarial Learning of Hard Positives for Place Recognition
May 08, 2022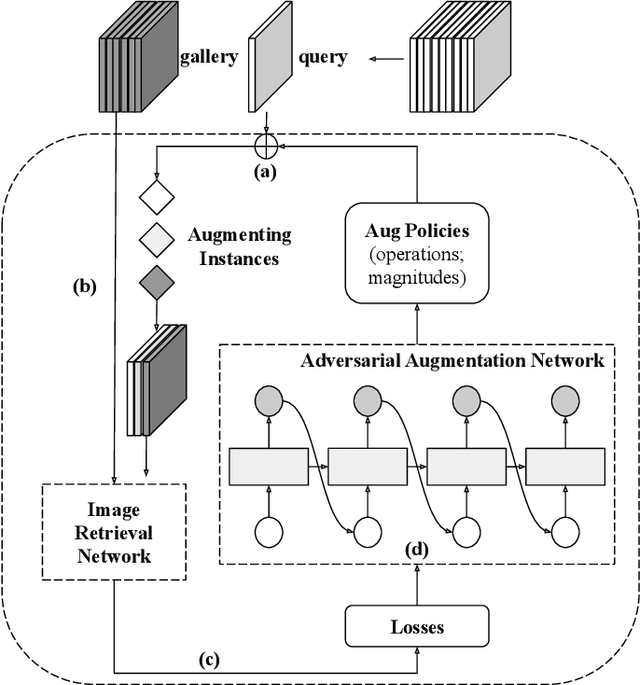
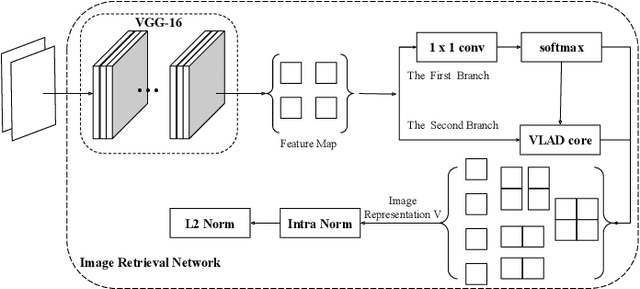

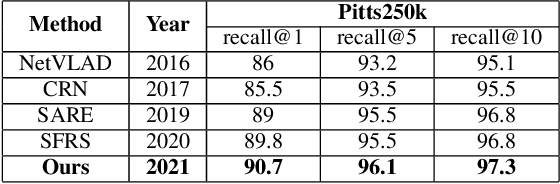
Image retrieval methods for place recognition learn global image descriptors that are used for fetching geo-tagged images at inference time. Recent works have suggested employing weak and self-supervision for mining hard positives and hard negatives in order to improve localization accuracy and robustness to visibility changes (e.g. in illumination or view point). However, generating hard positives, which is essential for obtaining robustness, is still limited to hard-coded or global augmentations. In this work we propose an adversarial method to guide the creation of hard positives for training image retrieval networks. Our method learns local and global augmentation policies which will increase the training loss, while the image retrieval network is forced to learn more powerful features for discriminating increasingly difficult examples. This approach allows the image retrieval network to generalize beyond the hard examples presented in the data and learn features that are robust to a wide range of variations. Our method achieves state-of-the-art recalls on the Pitts250 and Tokyo 24/7 benchmarks and outperforms recent image retrieval methods on the rOxford and rParis datasets by a noticeable margin.
ClusterGNN: Cluster-based Coarse-to-Fine Graph Neural Network for Efficient Feature Matching
Apr 25, 2022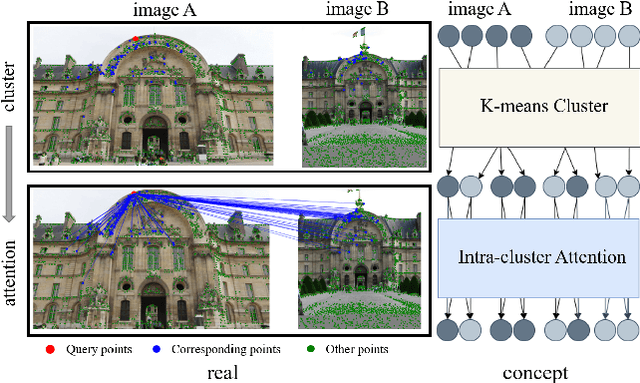
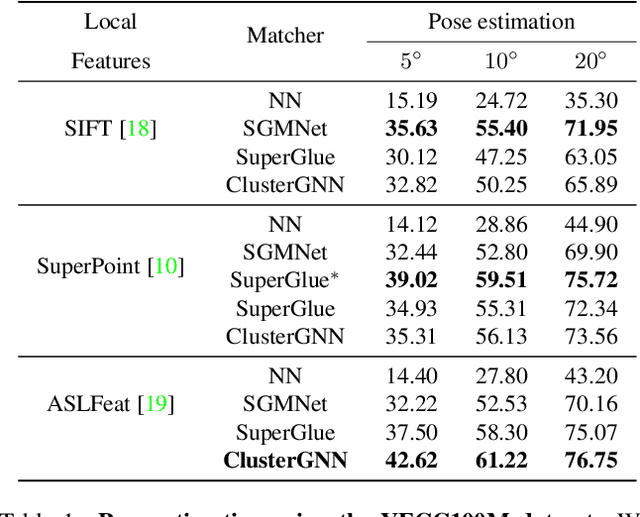
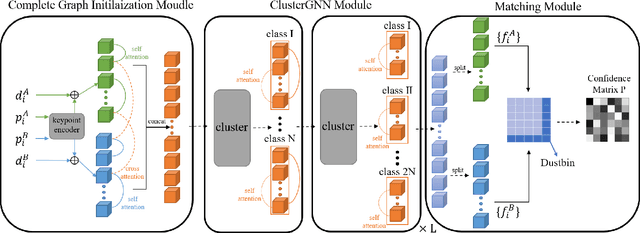
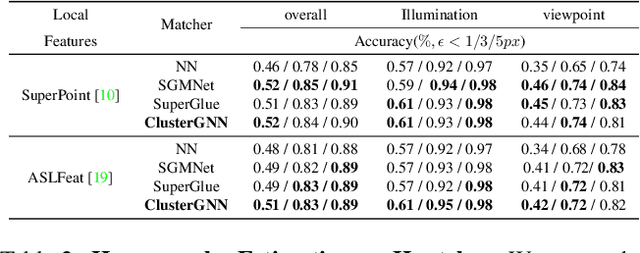
Graph Neural Networks (GNNs) with attention have been successfully applied for learning visual feature matching. However, current methods learn with complete graphs, resulting in a quadratic complexity in the number of features. Motivated by a prior observation that self- and cross- attention matrices converge to a sparse representation, we propose ClusterGNN, an attentional GNN architecture which operates on clusters for learning the feature matching task. Using a progressive clustering module we adaptively divide keypoints into different subgraphs to reduce redundant connectivity, and employ a coarse-to-fine paradigm for mitigating miss-classification within images. Our approach yields a 59.7% reduction in runtime and 58.4% reduction in memory consumption for dense detection, compared to current state-of-the-art GNN-based matching, while achieving a competitive performance on various computer vision tasks.
Controllable Continuous Gaze Redirection
Oct 09, 2020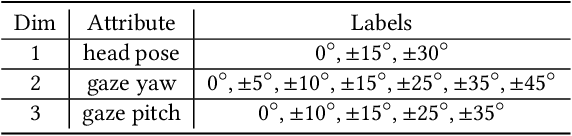
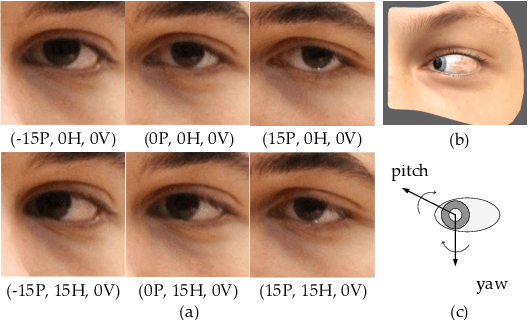
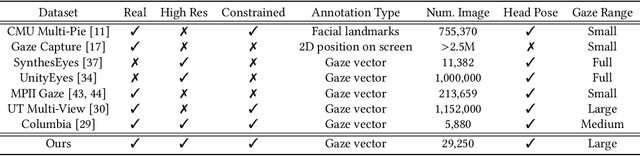
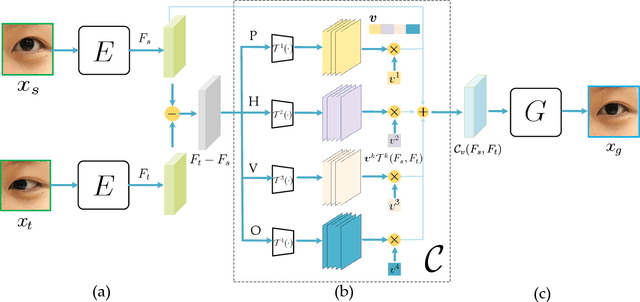
In this work, we present interpGaze, a novel framework for controllable gaze redirection that achieves both precise redirection and continuous interpolation. Given two gaze images with different attributes, our goal is to redirect the eye gaze of one person into any gaze direction depicted in the reference image or to generate continuous intermediate results. To accomplish this, we design a model including three cooperative components: an encoder, a controller and a decoder. The encoder maps images into a well-disentangled and hierarchically-organized latent space. The controller adjusts the magnitudes of latent vectors to the desired strength of corresponding attributes by altering a control vector. The decoder converts the desired representations from the attribute space to the image space. To facilitate covering the full space of gaze directions, we introduce a high-quality gaze image dataset with a large range of directions, which also benefits researchers in related areas. Extensive experimental validation and comparisons to several baseline methods show that the proposed interpGaze outperforms state-of-the-art methods in terms of image quality and redirection precision.
Learning Generic Diffusion Processes for Image Restoration
Jul 17, 2018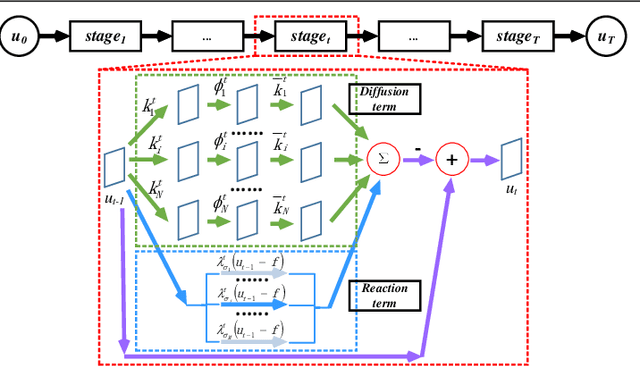
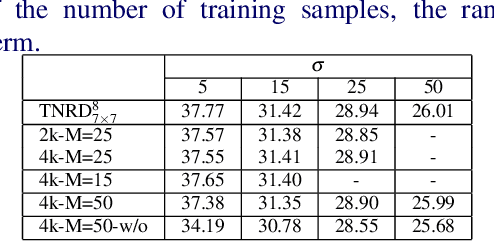
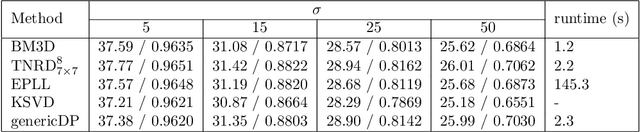

Image restoration problems are typical ill-posed problems where the regularization term plays an important role. The regularization term learned via generative approaches is easy to transfer to various image restoration, but offers inferior restoration quality compared with that learned via discriminative approaches. On the contrary, the regularization term learned via discriminative approaches are usually trained for a specific image restoration problem, and fail in the problem for which it is not trained. To address this issue, we propose a generic diffusion process (genericDP) to handle multiple Gaussian denoising problems based on the Trainable Non-linear Reaction Diffusion (TNRD) models. Instead of one model, which consists of a diffusion and a reaction term, for one Gaussian denoising problem in TNRD, we enforce multiple TNRD models to share one diffusion term. The trained genericDP model can provide both promising denoising performance and high training efficiency compared with the original TNRD models. We also transfer the trained diffusion term to non-blind deconvolution which is unseen in the training phase. Experiment results show that the trained diffusion term for multiple Gaussian denoising can be transferred to image non-blind deconvolution as an image prior and provide competitive performance.
* 12 pages, 3 figures, 3 tables
Speckle Reduction with Trained Nonlinear Diffusion Filtering
Feb 24, 2017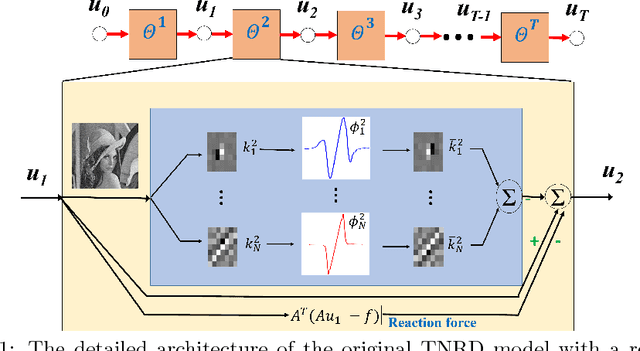

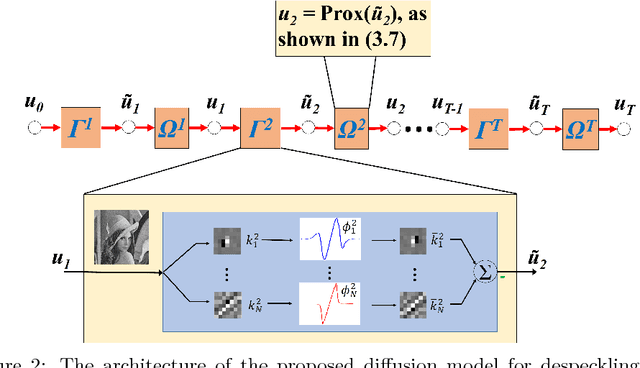

Speckle reduction is a prerequisite for many image processing tasks in synthetic aperture radar (SAR) images, as well as all coherent images. In recent years, predominant state-of-the-art approaches for despeckling are usually based on nonlocal methods which mainly concentrate on achieving utmost image restoration quality, with relatively low computational efficiency. Therefore, in this study we aim to propose an efficient despeckling model with both high computational efficiency and high recovery quality. To this end, we exploit a newly-developed trainable nonlinear reaction diffusion(TNRD) framework which has proven a simple and effective model for various image restoration problems. {In the original TNRD applications, the diffusion network is usually derived based on the direct gradient descent scheme. However, this approach will encounter some problem for the task of multiplicative noise reduction exploited in this study. To solve this problem, we employed a new architecture derived from the proximal gradient descent method.} {Taking into account the speckle noise statistics, the diffusion process for the despeckling task is derived. We then retrain all the model parameters in the presence of speckle noise. Finally, optimized nonlinear diffusion filtering models are obtained, which are specialized for despeckling with various noise levels. Experimental results substantiate that the trained filtering models provide comparable or even better results than state-of-the-art nonlocal approaches. Meanwhile, our proposed model merely contains convolution of linear filters with an image, which offers high level parallelism on GPUs. As a consequence, for images of size $512 \times 512$, our GPU implementation takes less than 0.1 seconds to produce state-of-the-art despeckling performance.}
Learning Non-local Image Diffusion for Image Denoising
Feb 24, 2017


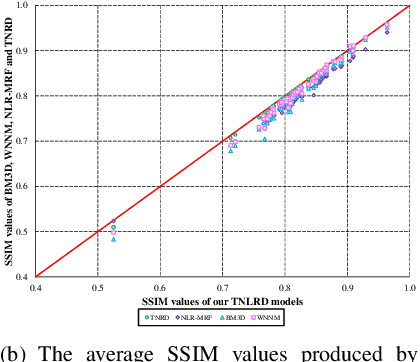
Image diffusion plays a fundamental role for the task of image denoising. Recently proposed trainable nonlinear reaction diffusion (TNRD) model defines a simple but very effective framework for image denoising. However, as the TNRD model is a local model, the diffusion behavior of which is purely controlled by information of local patches, it is prone to create artifacts in the homogenous regions and over-smooth highly textured regions, especially in the case of strong noise levels. Meanwhile, it is widely known that the non-local self-similarity (NSS) prior stands as an effective image prior for image denoising, which has been widely exploited in many non-local methods. In this work, we are highly motivated to embed the NSS prior into the TNRD model to tackle its weaknesses. In order to preserve the expected property that end-to-end training is available, we exploit the NSS prior by a set of non-local filters, and derive our proposed trainable non-local reaction diffusion (TNLRD) model for image denoising. Together with the local filters and influence functions, the non-local filters are learned by employing loss-specific training. The experimental results show that the trained TNLRD model produces visually plausible recovered images with more textures and less artifacts, compared to its local versions. Moreover, the trained TNLRD model can achieve strongly competitive performance to recent state-of-the-art image denoising methods in terms of peak signal-to-noise ratio (PSNR) and structural similarity index (SSIM).