 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2022 Challenge on Super-Resolution and Quality Enhancement of Compressed Video: Dataset, Methods and Results
Apr 25, 2022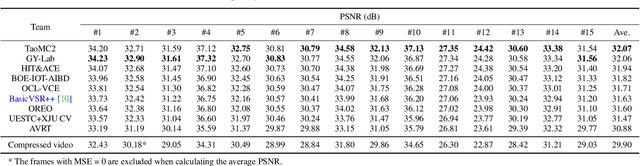
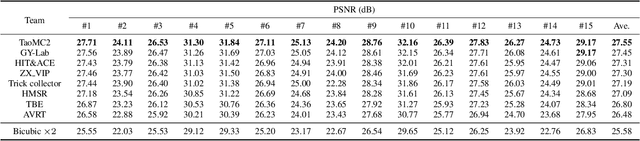

This paper reviews the NTIRE 2022 Challenge on Super-Resolution and Quality Enhancement of Compressed Video. In this challenge, we proposed the LDV 2.0 dataset, which includes the LDV dataset (240 videos) and 95 additional videos. This challenge includes three tracks. Track 1 aims at enhancing the videos compressed by HEVC at a fixed QP. Track 2 and Track 3 target both the super-resolution and quality enhancement of HEVC compressed video. They require x2 and x4 super-resolution, respectively. The three tracks totally attract more than 600 registrations. In the test phase, 8 teams, 8 teams and 12 teams submitted the final results to Tracks 1, 2 and 3, respectively. The proposed methods and solutions gauge the state-of-the-art of super-resolution and quality enhancement of compressed video. The proposed LDV 2.0 dataset is available at https://github.com/RenYang-home/LDV_dataset. The homepage of this challenge (including open-sourced codes) is at https://github.com/RenYang-home/NTIRE22_VEnh_SR.
Self-Supervised Learning for Real-World Super-Resolution from Dual Zoomed Observations
Mar 02, 2022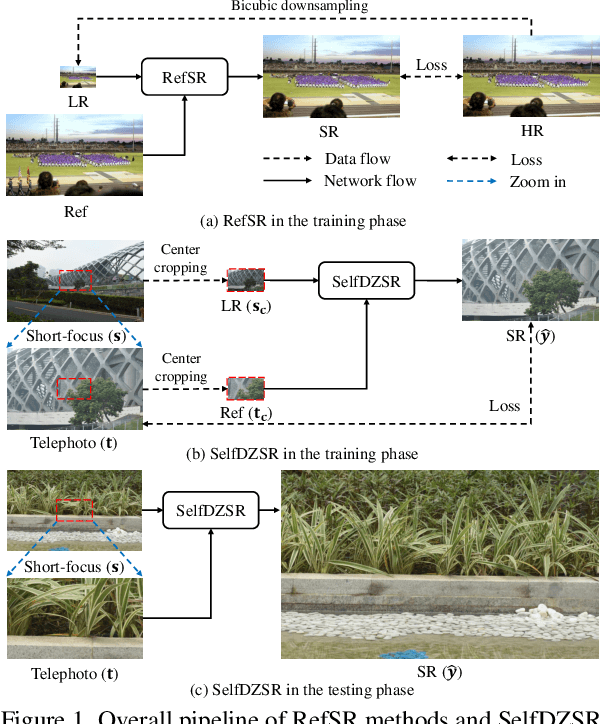
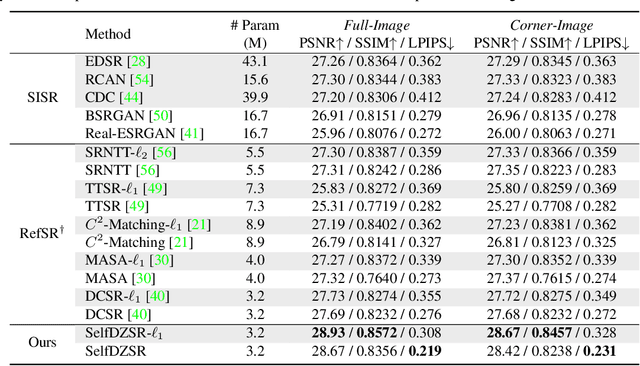

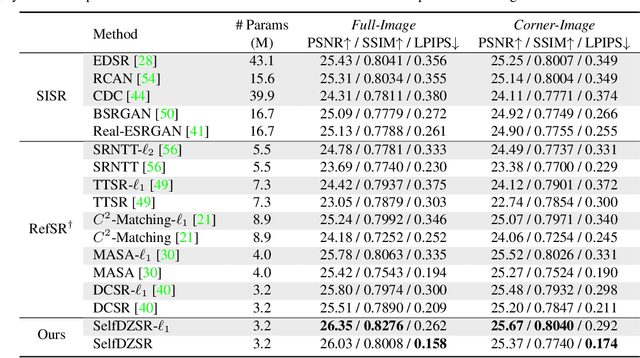
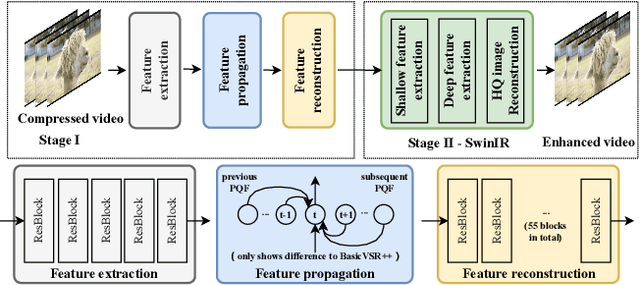
In this paper, we consider two challenging issues in reference-based super-resolution (RefSR), (i) how to choose a proper reference image, and (ii) how to learn real-world RefSR in a self-supervised manner. Particularly, we present a novel self-supervised learning approach for real-world image SR from observations at dual camera zooms (SelfDZSR). For the first issue, the more zoomed (telephoto) image can be naturally leveraged as the reference to guide the SR of the lesser zoomed (short-focus) image. For the second issue, SelfDZSR learns a deep network to obtain the SR result of short-focal image and with the same resolution as the telephoto image. For this purpose, we take the telephoto image instead of an additional high-resolution image as the supervision information and select a patch from it as the reference to super-resolve the corresponding short-focus image patch. To mitigate the effect of various misalignment between the short-focus low-resolution (LR) image and telephoto ground-truth (GT) image, we design a degradation model and map the GT to a pseudo-LR image aligned with GT. Then the pseudo-LR and LR image can be fed into the proposed adaptive spatial transformer networks (AdaSTN) to deform the LR features. During testing, SelfDZSR can be directly deployed to super-solve the whole short-focus image with the reference of telephoto image. Experiments show that our method achieves better quantitative and qualitative performance against state-of-the-arts. The code and pre-trained models will be publicly available.
Learning Generic Diffusion Processes for Image Restoration
Jul 17, 2018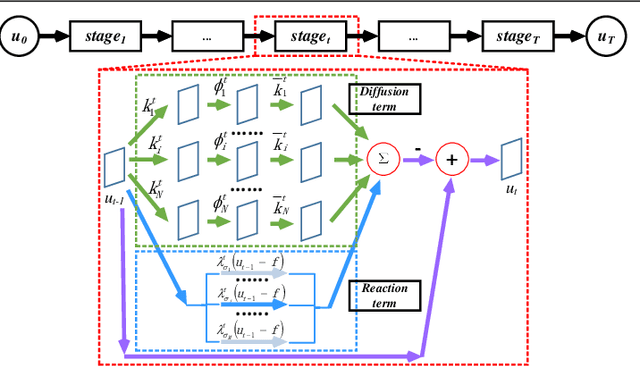
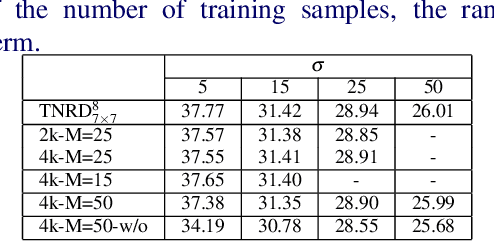
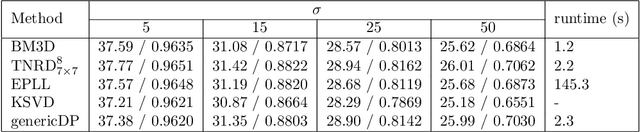

Image restoration problems are typical ill-posed problems where the regularization term plays an important role. The regularization term learned via generative approaches is easy to transfer to various image restoration, but offers inferior restoration quality compared with that learned via discriminative approaches. On the contrary, the regularization term learned via discriminative approaches are usually trained for a specific image restoration problem, and fail in the problem for which it is not trained. To address this issue, we propose a generic diffusion process (genericDP) to handle multiple Gaussian denoising problems based on the Trainable Non-linear Reaction Diffusion (TNRD) models. Instead of one model, which consists of a diffusion and a reaction term, for one Gaussian denoising problem in TNRD, we enforce multiple TNRD models to share one diffusion term. The trained genericDP model can provide both promising denoising performance and high training efficiency compared with the original TNRD models. We also transfer the trained diffusion term to non-blind deconvolution which is unseen in the training phase. Experiment results show that the trained diffusion term for multiple Gaussian denoising can be transferred to image non-blind deconvolution as an image prior and provide competitive performance.
* 12 pages, 3 figures, 3 tables
LEARN: Learned Experts' Assessment-based Reconstruction Network for Sparse-data CT
Feb 10, 2018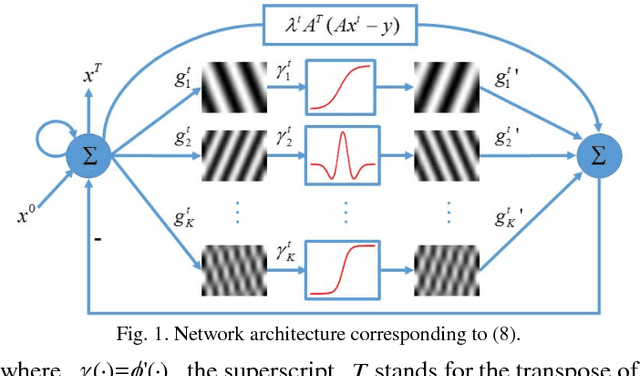
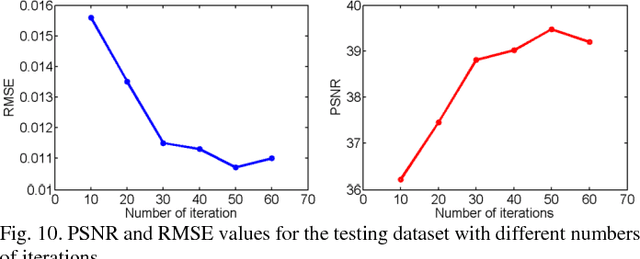
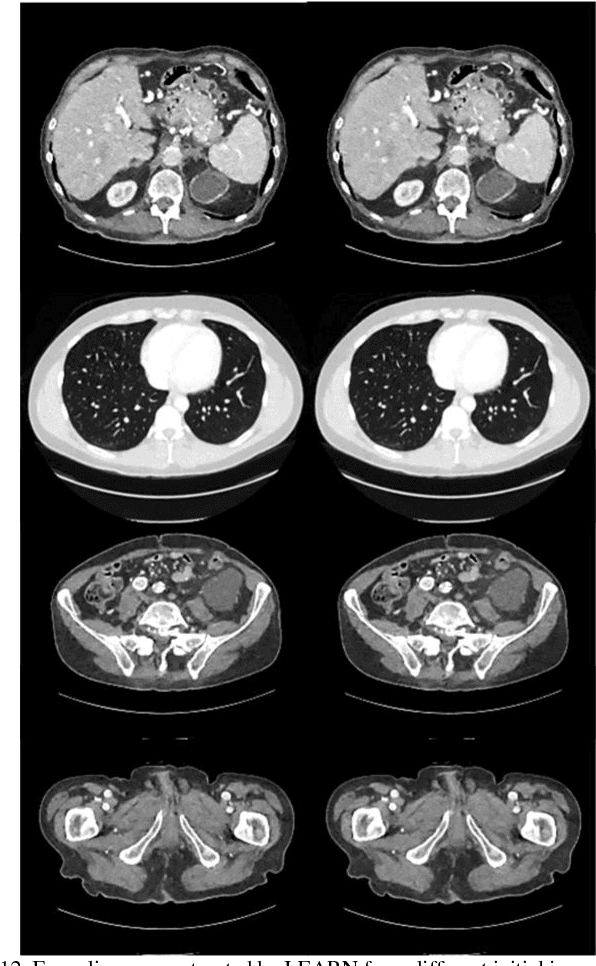
Compressive sensing (CS) has proved effective for tomographic reconstruction from sparsely collected data or under-sampled measurements, which are practically important for few-view CT, tomosynthesis, interior tomography, and so on. To perform sparse-data CT, the iterative reconstruction commonly use regularizers in the CS framework. Currently, how to choose the parameters adaptively for regularization is a major open problem. In this paper, inspired by the idea of machine learning especially deep learning, we unfold a state-of-the-art "fields of experts" based iterative reconstruction scheme up to a number of iterations for data-driven training, construct a Learned Experts' Assessment-based Reconstruction Network ("LEARN") for sparse-data CT, and demonstrate the feasibility and merits of our LEARN network. The experimental results with our proposed LEARN network produces a competitive performance with the well-known Mayo Clinic Low-Dose Challenge Dataset relative to several state-of-the-art methods, in terms of artifact reduction, feature preservation, and computational speed. This is consistent to our insight that because all the regularization terms and parameters used in the iterative reconstruction are now learned from the training data, our LEARN network utilizes application-oriented knowledge more effectively and recovers underlying images more favorably than competing algorithms. Also, the number of layers in the LEARN network is only 12, reducing the computational complexity of typical iterative algorithms by orders of magnitude.
Speckle Reduction with Trained Nonlinear Diffusion Filtering
Feb 24, 2017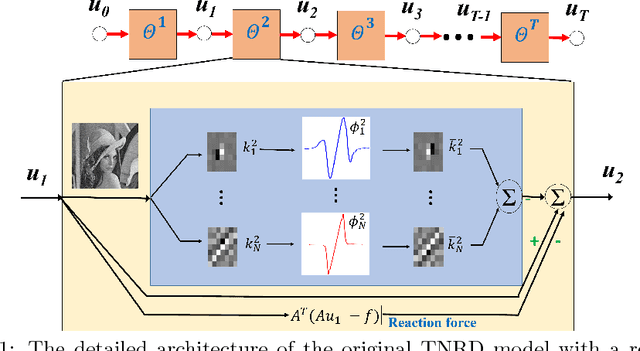

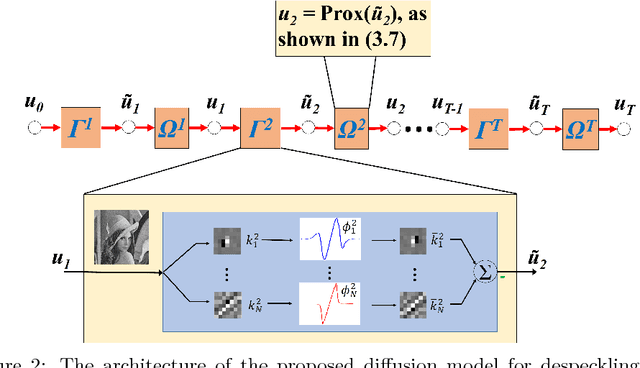

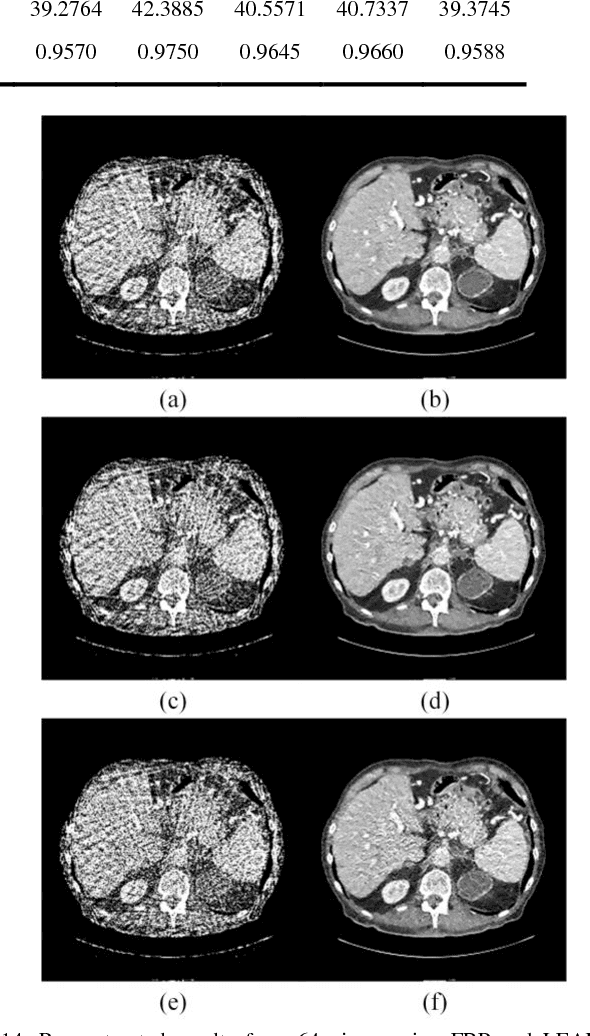
Speckle reduction is a prerequisite for many image processing tasks in synthetic aperture radar (SAR) images, as well as all coherent images. In recent years, predominant state-of-the-art approaches for despeckling are usually based on nonlocal methods which mainly concentrate on achieving utmost image restoration quality, with relatively low computational efficiency. Therefore, in this study we aim to propose an efficient despeckling model with both high computational efficiency and high recovery quality. To this end, we exploit a newly-developed trainable nonlinear reaction diffusion(TNRD) framework which has proven a simple and effective model for various image restoration problems. {In the original TNRD applications, the diffusion network is usually derived based on the direct gradient descent scheme. However, this approach will encounter some problem for the task of multiplicative noise reduction exploited in this study. To solve this problem, we employed a new architecture derived from the proximal gradient descent method.} {Taking into account the speckle noise statistics, the diffusion process for the despeckling task is derived. We then retrain all the model parameters in the presence of speckle noise. Finally, optimized nonlinear diffusion filtering models are obtained, which are specialized for despeckling with various noise levels. Experimental results substantiate that the trained filtering models provide comparable or even better results than state-of-the-art nonlocal approaches. Meanwhile, our proposed model merely contains convolution of linear filters with an image, which offers high level parallelism on GPUs. As a consequence, for images of size $512 \times 512$, our GPU implementation takes less than 0.1 seconds to produce state-of-the-art despeckling performance.}
Learning Non-local Image Diffusion for Image Denoising
Feb 24, 2017


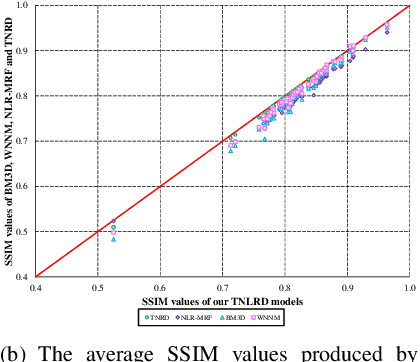
Image diffusion plays a fundamental role for the task of image denoising. Recently proposed trainable nonlinear reaction diffusion (TNRD) model defines a simple but very effective framework for image denoising. However, as the TNRD model is a local model, the diffusion behavior of which is purely controlled by information of local patches, it is prone to create artifacts in the homogenous regions and over-smooth highly textured regions, especially in the case of strong noise levels. Meanwhile, it is widely known that the non-local self-similarity (NSS) prior stands as an effective image prior for image denoising, which has been widely exploited in many non-local methods. In this work, we are highly motivated to embed the NSS prior into the TNRD model to tackle its weaknesses. In order to preserve the expected property that end-to-end training is available, we exploit the NSS prior by a set of non-local filters, and derive our proposed trainable non-local reaction diffusion (TNLRD) model for image denoising. Together with the local filters and influence functions, the non-local filters are learned by employing loss-specific training. The experimental results show that the trained TNLRD model produces visually plausible recovered images with more textures and less artifacts, compared to its local versions. Moreover, the trained TNLRD model can achieve strongly competitive performance to recent state-of-the-art image denoising methods in terms of peak signal-to-noise ratio (PSNR) and structural similarity index (SSIM).
Image Denoising via Multi-scale Nonlinear Diffusion Models
Sep 21, 2016
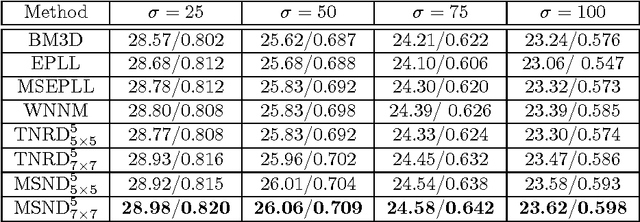
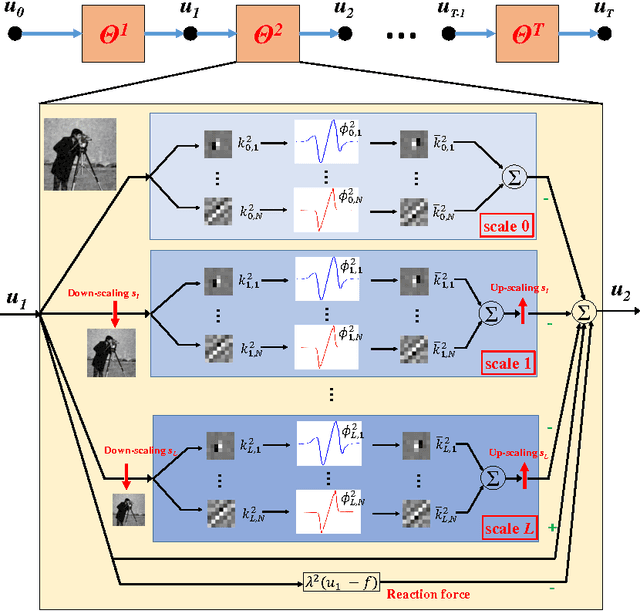
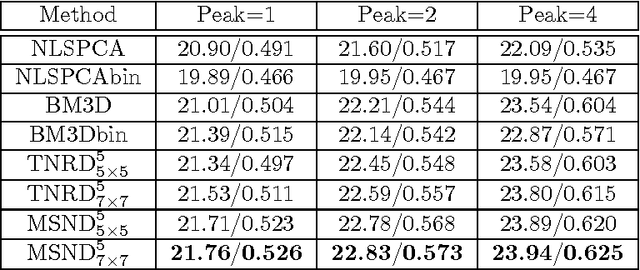
Image denoising is a fundamental operation in image processing and holds considerable practical importance for various real-world applications. Arguably several thousands of papers are dedicated to image denoising. In the past decade, sate-of-the-art denoising algorithm have been clearly dominated by non-local patch-based methods, which explicitly exploit patch self-similarity within image. However, in recent two years, discriminatively trained local approaches have started to outperform previous non-local models and have been attracting increasing attentions due to the additional advantage of computational efficiency. Successful approaches include cascade of shrinkage fields (CSF) and trainable nonlinear reaction diffusion (TNRD). These two methods are built on filter response of linear filters of small size using feed forward architectures. Due to the locality inherent in local approaches, the CSF and TNRD model become less effective when noise level is high and consequently introduces some noise artifacts. In order to overcome this problem, in this paper we introduce a multi-scale strategy. To be specific, we build on our newly-developed TNRD model, adopting the multi-scale pyramid image representation to devise a multi-scale nonlinear diffusion process. As expected, all the parameters in the proposed multi-scale diffusion model, including the filters and the influence functions across scales, are learned from training data through a loss based approach. Numerical results on Gaussian and Poisson denoising substantiate that the exploited multi-scale strategy can successfully boost the performance of the original TNRD model with single scale. As a consequence, the resulting multi-scale diffusion models can significantly suppress the typical incorrect features for those noisy images with heavy noise.
Poisson Noise Reduction with Higher-order Natural Image Prior Model
Sep 19, 2016


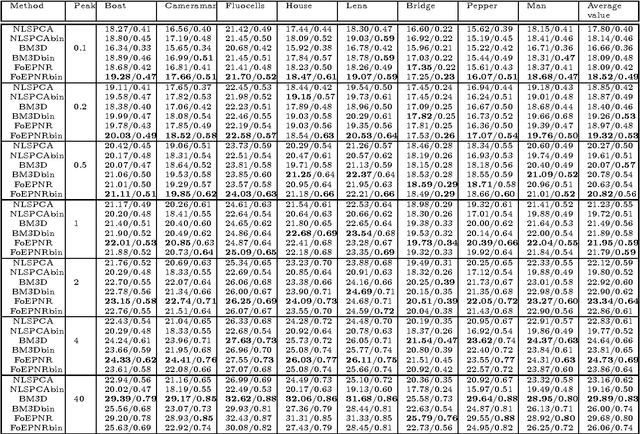
Poisson denoising is an essential issue for various imaging applications, such as night vision, medical imaging and microscopy. State-of-the-art approaches are clearly dominated by patch-based non-local methods in recent years. In this paper, we aim to propose a local Poisson denoising model with both structure simplicity and good performance. To this end, we consider a variational modeling to integrate the so-called Fields of Experts (FoE) image prior, that has proven an effective higher-order Markov Random Fields (MRF) model for many classic image restoration problems. We exploit several feasible variational variants for this task. We start with a direct modeling in the original image domain by taking into account the Poisson noise statistics, which performs generally well for the cases of high SNR. However, this strategy encounters problem in cases of low SNR. Then we turn to an alternative modeling strategy by using the Anscombe transform and Gaussian statistics derived data term. We retrain the FoE prior model directly in the transform domain. With the newly trained FoE model, we end up with a local variational model providing strongly competitive results against state-of-the-art non-local approaches, meanwhile bearing the property of simple structure. Furthermore, our proposed model comes along with an additional advantage, that the inference is very efficient as it is well-suited for parallel computation on GPUs. For images of size $512 \times 512$, our GPU implementation takes less than 1 second to produce state-of-the-art Poisson denoising performance.
Trainable Nonlinear Reaction Diffusion: A Flexible Framework for Fast and Effective Image Restoration
Aug 20, 2016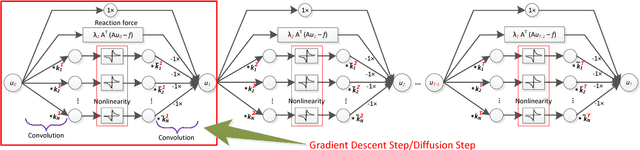
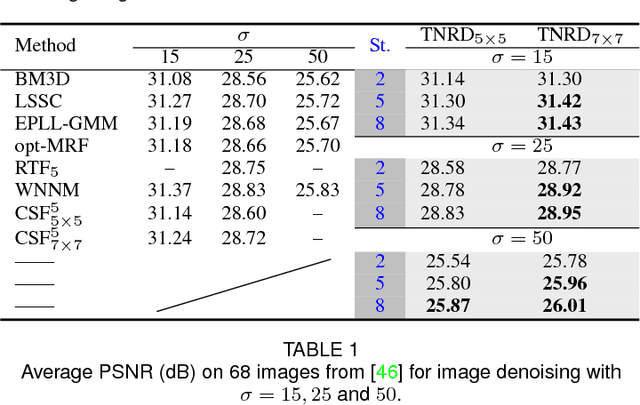

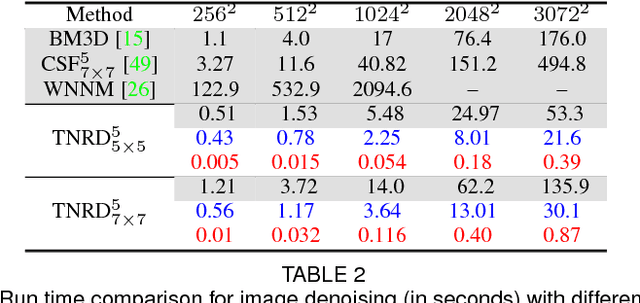
Image restoration is a long-standing problem in low-level computer vision with many interesting applications. We describe a flexible learning framework based on the concept of nonlinear reaction diffusion models for various image restoration problems. By embodying recent improvements in nonlinear diffusion models, we propose a dynamic nonlinear reaction diffusion model with time-dependent parameters (\ie, linear filters and influence functions). In contrast to previous nonlinear diffusion models, all the parameters, including the filters and the influence functions, are simultaneously learned from training data through a loss based approach. We call this approach TNRD -- \textit{Trainable Nonlinear Reaction Diffusion}. The TNRD approach is applicable for a variety of image restoration tasks by incorporating appropriate reaction force. We demonstrate its capabilities with three representative applications, Gaussian image denoising, single image super resolution and JPEG deblocking. Experiments show that our trained nonlinear diffusion models largely benefit from the training of the parameters and finally lead to the best reported performance on common test datasets for the tested applications. Our trained models preserve the structural simplicity of diffusion models and take only a small number of diffusion steps, thus are highly efficient. Moreover, they are also well-suited for parallel computation on GPUs, which makes the inference procedure extremely fast.
Beyond a Gaussian Denoiser: Residual Learning of Deep CNN for Image Denoising
Aug 13, 2016



Discriminative model learning for image denoising has been recently attracting considerable attentions due to its favorable denoising performance. In this paper, we take one step forward by investigating the construction of feed-forward denoising convolutional neural networks (DnCNNs) to embrace the progress in very deep architecture, learning algorithm, and regularization method into image denoising. Specifically, residual learning and batch normalization are utilized to speed up the training process as well as boost the denoising performance. Different from the existing discriminative denoising models which usually train a specific model for additive white Gaussian noise (AWGN) at a certain noise level, our DnCNN model is able to handle Gaussian denoising with unknown noise level (i.e., blind Gaussian denoising). With the residual learning strategy, DnCNN implicitly removes the latent clean image in the hidden layers. This property motivates us to train a single DnCNN model to tackle with several general image denoising tasks such as Gaussian denoising, single image super-resolution and JPEG image deblocking. Our extensive experiments demonstrate that our DnCNN model can not only exhibit high effectiveness in several general image denoising tasks, but also be efficiently implemented by benefiting from GPU computing.